 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Compact Pretraining Approach for Neural Language Models
Paper and Code
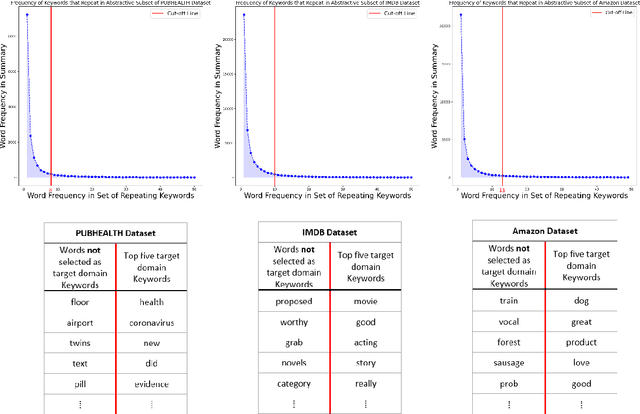
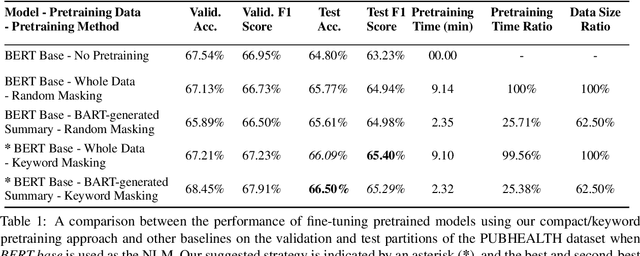
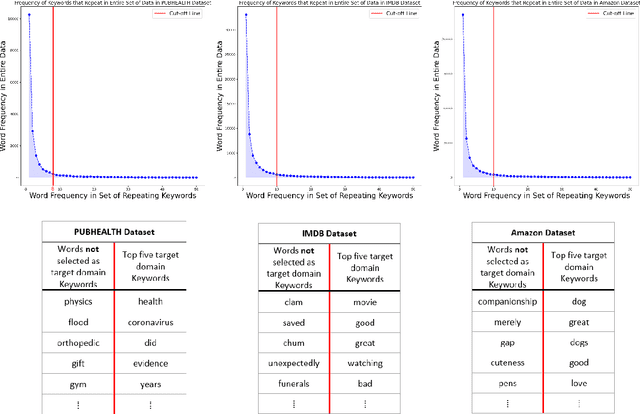

Domain adaptation for large neural language models (NLMs) is coupled with massive amounts of unstructured data in the pretraining phase. In this study, however, we show that pretrained NLMs learn in-domain information more effectively and faster from a compact subset of the data that focuses on the key information in the domain. We construct these compact subsets from the unstructured data using a combination of abstractive summaries and extractive keywords. In particular, we rely on BART to generate abstractive summaries, and KeyBERT to extract keywords from these summaries (or the original unstructured text directly). We evaluate our approach using six different settings: three datasets combined with two distinct NLMs. Our results reveal that the task-specific classifiers trained on top of NLMs pretrained using our method outperform methods based on traditional pretraining, i.e., random masking on the entire data, as well as methods without pretraining. Further, we show that our strategy reduces pretraining time by up to five times compared to vanilla pretraining. The code for all of our experiments is publicly available at https://github.com/shahriargolchin/compact-pretraining.