 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Models as Measurement Apparatus for Culture
Jul 02, 2026Language models are increasingly used to quantify cultural phenomena, but what makes such measurement distinctively cultural? This paper argues that NLP work on culture is a material-discursive practice: the apparatus -- model, data, annotation, evaluation -- participates in constituting the cultural reality it measures, rather than passively recording it. Drawing on Karen Barad's concept of the agential cut -- the contingent boundary between phenomenon and instrument -- I show that the apparatus's substantive design choices draw such boundaries, and that the boundary is entangled from the start because language models have already internalized much of the cultural material they measure. I illustrate this through three case studies on television and film dialogue (measuring structure, interaction, and deviation) and three examinations of the apparatus itself (erasure of cultural markers, attunement to historical material, and agency in an agentic workflow). This big picture analysis proposes a research program that is theory-driven, empirically rigorous, and culturally contingent, treating each agential cut as a conscious commitment, at once methodological and ethical.
Multimodal Conversation Structure Understanding
May 23, 2025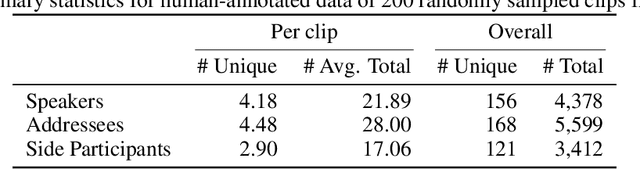
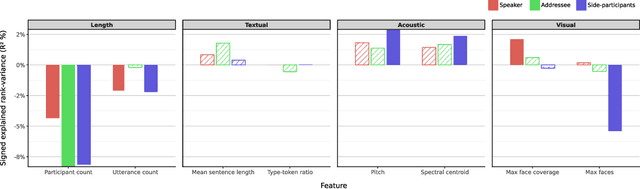
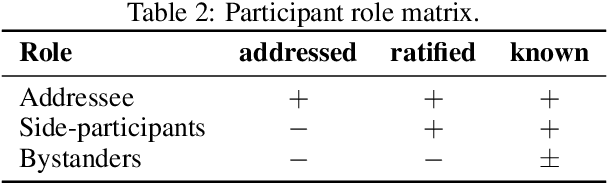
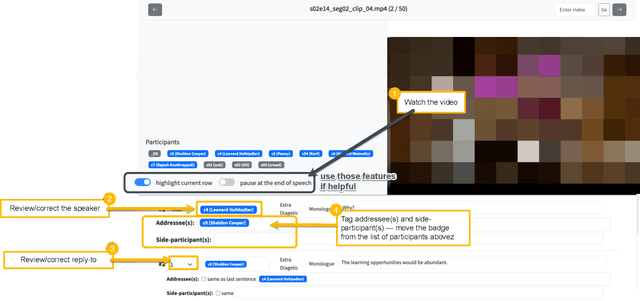
Conversations are usually structured by roles -- who is speaking, who's being addressed, and who's listening -- and unfold in threads that break with changes in speaker floor or topical focus. While large language models (LLMs) have shown incredible capabilities in dialogue and reasoning, their ability to understand fine-grained conversational structure, especially in multi-modal, multi-party settings, remains underexplored. To address this gap, we introduce a suite of tasks focused on conversational role attribution (speaker, addressees, side-participants) and conversation threading (utterance linking and clustering), drawing on conversation analysis and sociolinguistics. To support those tasks, we present a human annotated dataset of 4,398 annotations for speakers and reply-to relationship, 5,755 addressees, and 3,142 side-participants. We evaluate popular audio-visual LLMs and vision-language models on our dataset, and our experimental results suggest that multimodal conversational structure understanding remains challenging. The most performant audio-visual LLM outperforms all vision-language models across all metrics, especially in speaker and addressee recognition. However, its performance drops significantly when conversation participants are anonymized. The number of conversation participants in a clip is the strongest negative predictor of role-attribution performance, while acoustic clarity (measured by pitch and spectral centroid) and detected face coverage yield positive associations. We hope this work lays the groundwork for future evaluation and development of multimodal LLMs that can reason more effectively about conversation structure.
Subversive Characters and Stereotyping Readers: Characterizing Queer Relationalities with Dialogue-Based Relation Extraction
Oct 19, 2024



Television is often seen as a site for subcultural identification and subversive fantasy, including in queer cultures. How might we measure subversion, or the degree to which the depiction of social relationship between a dyad (e.g. two characters who are colleagues) deviates from its typical representation on TV? To explore this question, we introduce the task of stereotypic relationship extraction. Built on cognitive stylistics, linguistic anthropology, and dialogue relation extraction, in this paper, we attempt to model the cognitive process of stereotyping TV characters in dialogic interactions. Given a dyad, we want to predict: what social relationship do the speakers exhibit through their words? Subversion is then characterized by the discrepancy between the distribution of the model's predictions and the ground truth labels. To demonstrate the usefulness of this task and gesture at a methodological intervention, we enclose four case studies to characterize the representation of queer relationalities in the Big Bang Theory, Frasier, and Gilmore Girls, as we explore the suspicious and reparative modes of reading with our computational methods.
On Classification with Large Language Models in Cultural Analytics
Oct 15, 2024



In this work, we survey the way in which classification is used as a sensemaking practice in cultural analytics, and assess where large language models can fit into this landscape. We identify ten tasks supported by publicly available datasets on which we empirically assess the performance of LLMs compared to traditional supervised methods, and explore the ways in which LLMs can be employed for sensemaking goals beyond mere accuracy. We find that prompt-based LLMs are competitive with traditional supervised models for established tasks, but perform less well on de novo tasks. In addition, LLMs can assist sensemaking by acting as an intermediary input to formal theory testing.
Dramatic Conversation Disentanglement
May 26, 2023We present a new dataset for studying conversation disentanglement in movies and TV series. While previous work has focused on conversation disentanglement in IRC chatroom dialogues, movies and TV shows provide a space for studying complex pragmatic patterns of floor and topic change in face-to-face multi-party interactions. In this work, we draw on theoretical research in sociolinguistics, sociology, and film studies to operationalize a conversational thread (including the notion of a floor change) in dramatic texts, and use that definition to annotate a dataset of 10,033 dialogue turns (comprising 2,209 threads) from 831 movies. We compare the performance of several disentanglement models on this dramatic dataset, and apply the best-performing model to disentangle 808 movies. We see that, contrary to expectation, average thread lengths do not decrease significantly over the past 40 years, and characters portrayed by actors who are women, while underrepresented, initiate more new conversational threads relative to their speaking time.
Speak, Memory: An Archaeology of Books Known to ChatGPT/GPT-4
Apr 28, 2023



In this work, we carry out a data archaeology to infer books that are known to ChatGPT and GPT-4 using a name cloze membership inference query. We find that OpenAI models have memorized a wide collection of copyrighted materials, and that the degree of memorization is tied to the frequency with which passages of those books appear on the web. The ability of these models to memorize an unknown set of books complicates assessments of measurement validity for cultural analytics by contaminating test data; we show that models perform much better on memorized books than on non-memorized books for downstream tasks. We argue that this supports a case for open models whose training data is known.