 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Joint JSCC-Resource Allocation Framework for QoS-Aware Semantic Communication in LEO Satellite-based EO Missions
Mar 12, 2026In Earth observation (EO) missions with Low Earth orbit (LEO) satellites, high-resolution image acquisition generates a massive data volume that poses a significant challenge for transmission under the limited satellite power budget, while LEO movement introduces dynamic systems. To enable efficient image transmission, this paper employs semantic communication (SemCom) with joint source-channel coding (JSCC), which focuses on transmitting meaningful information to reduce power consumption. Under a quality-of-service (QoS) requirement defined by image reconstruction quality, this work aims to minimize the total transmit power by jointly optimizing the JSCC encoder-decoder parameters and resource allocation. However, the implicit relationship among JSCC parameters, link quality, and image quality, coupled with the presence of mixed integer-continuous variables, makes the problem difficult to solve directly. To address this, a curve-fitting model is proposed to approximate the JSCC compression-SNR-quality relationship. Then, the joint compression ratio-resource allocation (JCRRA) algorithm is proposed to address the underlying problem. Numerical results demonstrate that the proposed method achieves substantial power savings compared to both greedy algorithms and conventional transmission paradigms.
Toward a Unified Semantic Loss Model for Deep JSCC-based Transmission of EO Imagery
Jan 28, 2026Modern Earth Observation (EO) systems increasingly rely on high-resolution imagery to support critical applications such as environmental monitoring, disaster response, and land-use analysis. Although these applications benefit from detailed visual data, the resulting data volumes impose significant challenges on satellite communication systems constrained by limited bandwidth, power, and dynamic link conditions. To address these limitations, this paper investigates Deep Joint Source-Channel Coding (DJSCC) as an effective source-channel paradigm for the transmission of EO imagery. We focus on two complementary aspects of semantic loss in DJSCC-based systems. First, a reconstruction-centric framework is evaluated by analyzing the semantic degradation of reconstructed images under varying compression ratios and channel signal-to-noise ratios (SNR). Second, a task-oriented framework is developed by integrating DJSCC with lightweight, application-specific models (e.g., EfficientViT), with performance measured using downstream task accuracy rather than pixel-level fidelity. Based on extensive empirical analysis, we propose a unified semantic loss framework that captures both reconstruction-centric and task-oriented performance within a single model. This framework characterizes the implicit relationship between JSCC compression, channel SNR, and semantic quality, offering actionable insights for the design of robust and efficient EO imagery transmission under resource-constrained satellite links.
DT-Aided Resource Management in Spectrum Sharing Integrated Satellite-Terrestrial Networks
Jul 28, 2025



The integrated satellite-terrestrial networks (ISTNs) through spectrum sharing have emerged as a promising solution to improve spectral efficiency and meet increasing wireless demand. However, this coexistence introduces significant challenges, including inter-system interference (ISI) and the low Earth orbit satellite (LSat) movements. To capture the actual environment for resource management, we propose a time-varying digital twin (DT)-aided framework for ISTNs incorporating 3D map that enables joint optimization of bandwidth (BW) allocation, traffic steering, and resource allocation, and aims to minimize congestion. The problem is formulated as a mixed-integer nonlinear programming (MINLP), addressed through a two-phase algorithm based on successive convex approximation (SCA) and compressed sensing approaches. Numerical results demonstrate the proposed method's superior performance in queue length minimization compared to benchmarks.
Multimodal Conversation Structure Understanding
May 23, 2025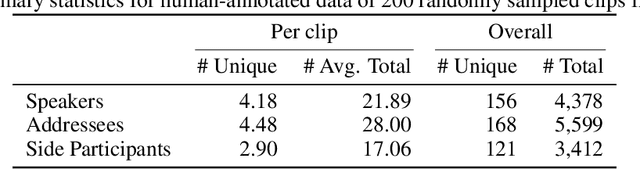
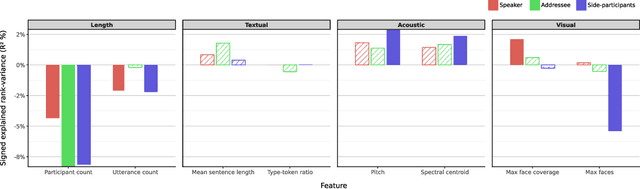
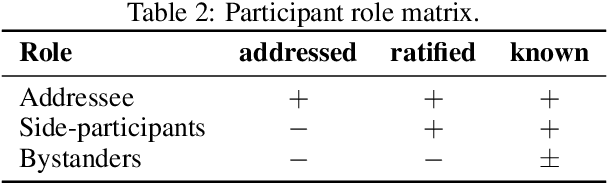
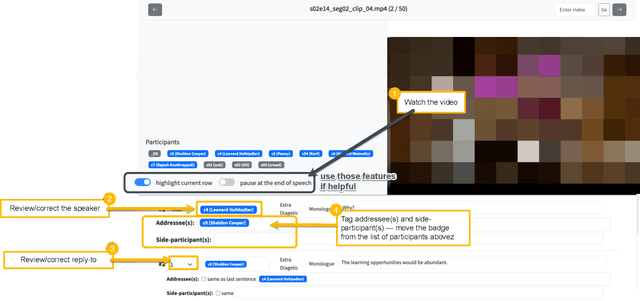
Conversations are usually structured by roles -- who is speaking, who's being addressed, and who's listening -- and unfold in threads that break with changes in speaker floor or topical focus. While large language models (LLMs) have shown incredible capabilities in dialogue and reasoning, their ability to understand fine-grained conversational structure, especially in multi-modal, multi-party settings, remains underexplored. To address this gap, we introduce a suite of tasks focused on conversational role attribution (speaker, addressees, side-participants) and conversation threading (utterance linking and clustering), drawing on conversation analysis and sociolinguistics. To support those tasks, we present a human annotated dataset of 4,398 annotations for speakers and reply-to relationship, 5,755 addressees, and 3,142 side-participants. We evaluate popular audio-visual LLMs and vision-language models on our dataset, and our experimental results suggest that multimodal conversational structure understanding remains challenging. The most performant audio-visual LLM outperforms all vision-language models across all metrics, especially in speaker and addressee recognition. However, its performance drops significantly when conversation participants are anonymized. The number of conversation participants in a clip is the strongest negative predictor of role-attribution performance, while acoustic clarity (measured by pitch and spectral centroid) and detected face coverage yield positive associations. We hope this work lays the groundwork for future evaluation and development of multimodal LLMs that can reason more effectively about conversation structure.
GLUSE: Enhanced Channel-Wise Adaptive Gated Linear Units SE for Onboard Satellite Earth Observation Image Classification
Apr 16, 2025This study introduces ResNet-GLUSE, a lightweight ResNet variant enhanced with Gated Linear Unit-enhanced Squeeze-and-Excitation (GLUSE), an adaptive channel-wise attention mechanism. By integrating dynamic gating into the traditional SE framework, GLUSE improves feature recalibration while maintaining computational efficiency. Experiments on EuroSAT and PatternNet datasets confirm its effectiveness, achieving exceeding \textbf{94\% and 98\% accuracy}, respectively. While \textbf{MobileViT achieves 99\% accuracy}, ResNet-GLUSE offers \textbf{33x fewer parameters, 27x fewer FLOPs, 33x smaller model size (MB), $\approx$6x lower power consumption (W), and $\approx$3x faster inference time (s)}, making it significantly more efficient for onboard satellite deployment. Furthermore, due to its simplicity, ResNet-GLUSE can be easily mimicked for \textbf{neuromorphic computing}, enabling ultra-low power inference at just \textbf{852.30 mW} on Akida Brainchip. This balance between high accuracy and ultra-low resource consumption establishes ResNet-GLUSE as a practical solution for real-time Earth Observation (EO) tasks. Reproducible codes are available in our shared repository.
A Semantic-Loss Function Modeling Framework With Task-Oriented Machine Learning Perspectives
Mar 12, 2025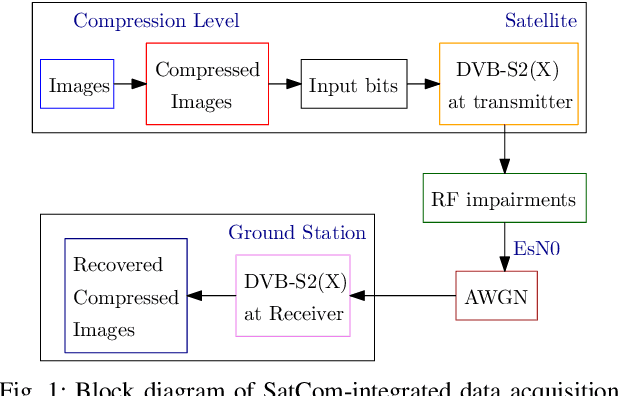
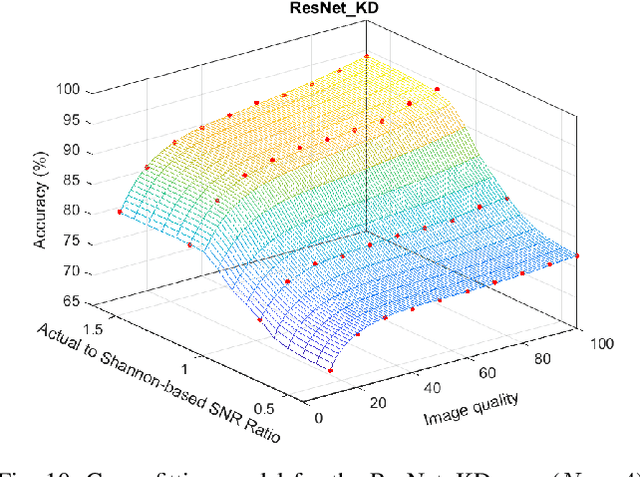
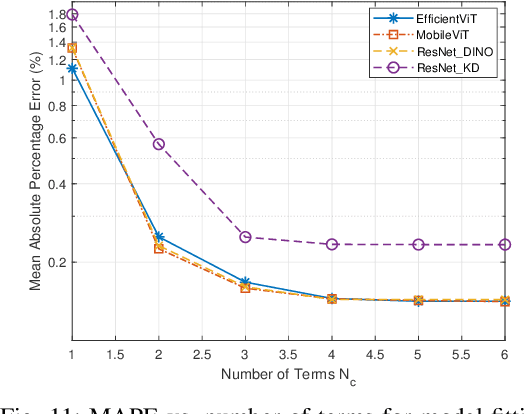

The integration of machine learning (ML) has significantly enhanced the capabilities of Earth Observation (EO) systems by enabling the extraction of actionable insights from complex datasets. However, the performance of data-driven EO applications is heavily influenced by the data collection and transmission processes, where limited satellite bandwidth and latency constraints can hinder the full transmission of original data to the receivers. To address this issue, adopting the concepts of Semantic Communication (SC) offers a promising solution by prioritizing the transmission of essential data semantics over raw information. Implementing SC for EO systems requires a thorough understanding of the impact of data processing and communication channel conditions on semantic loss at the processing center. This work proposes a novel data-fitting framework to empirically model the semantic loss using real-world EO datasets and domain-specific insights. The framework quantifies two primary types of semantic loss: (1) source coding loss, assessed via a data quality indicator measuring the impact of processing on raw source data, and (2) transmission loss, evaluated by comparing practical transmission performance against the Shannon limit. Semantic losses are estimated by evaluating the accuracy of EO applications using four task-oriented ML models, EfficientViT, MobileViT, ResNet50-DINO, and ResNet8-KD, on lossy image datasets under varying channel conditions and compression ratios. These results underpin a framework for efficient semantic-loss modeling in bandwidth-constrained EO scenarios, enabling more reliable and effective operations.
Semantic Knowledge Distillation for Onboard Satellite Earth Observation Image Classification
Oct 31, 2024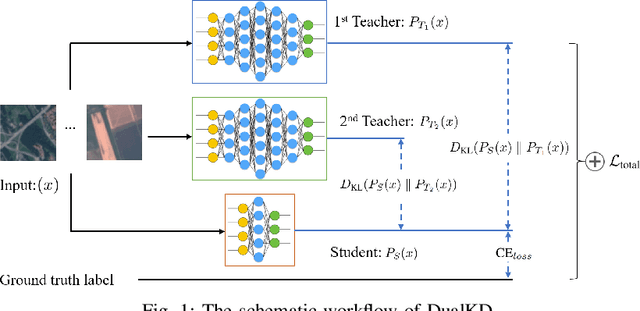
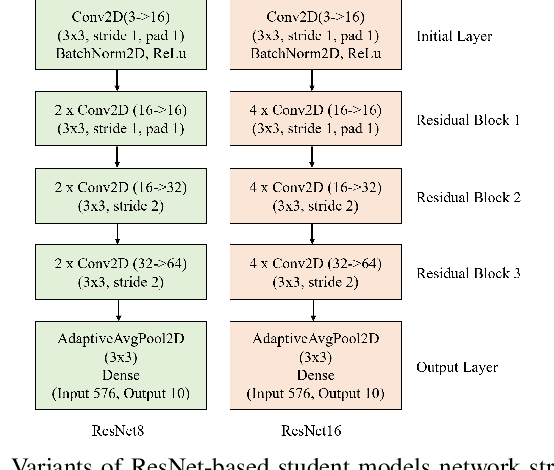
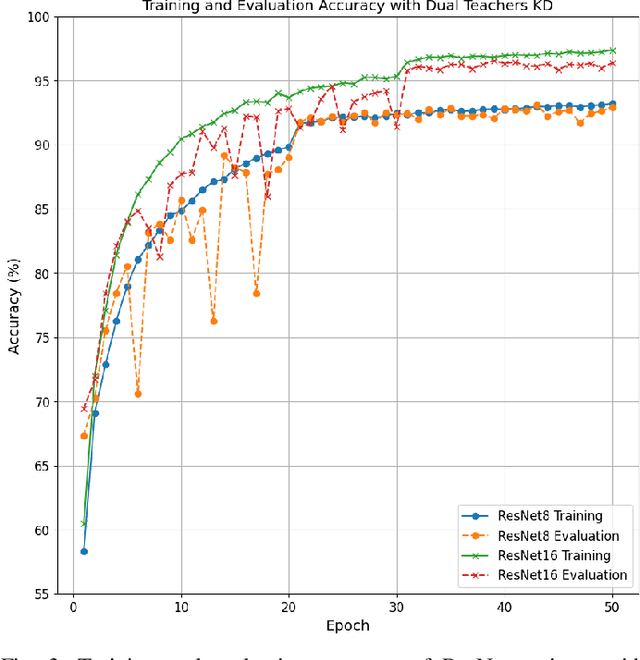
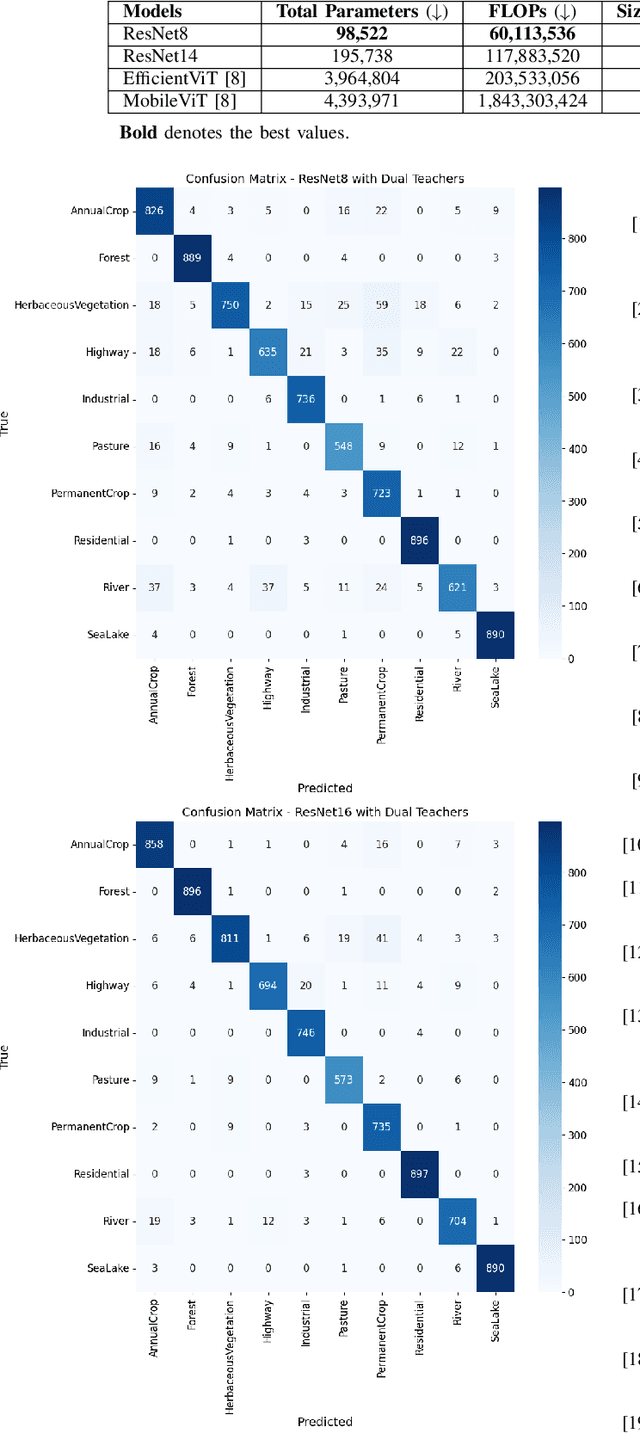
This study presents an innovative dynamic weighting knowledge distillation (KD) framework tailored for efficient Earth observation (EO) image classification (IC) in resource-constrained settings. Utilizing EfficientViT and MobileViT as teacher models, this framework enables lightweight student models, particularly ResNet8 and ResNet16, to surpass 90% in accuracy, precision, and recall, adhering to the stringent confidence thresholds necessary for reliable classification tasks. Unlike conventional KD methods that rely on static weight distribution, our adaptive weighting mechanism responds to each teacher model's confidence, allowing student models to prioritize more credible sources of knowledge dynamically. Remarkably, ResNet8 delivers substantial efficiency gains, achieving a 97.5% reduction in parameters, a 96.7% decrease in FLOPs, an 86.2% cut in power consumption, and a 63.5% increase in inference speed over MobileViT. This significant optimization of complexity and resource demands establishes ResNet8 as an optimal candidate for EO tasks, combining robust performance with feasibility in deployment. The confidence-based, adaptable KD approach underscores the potential of dynamic distillation strategies to yield high-performing, resource-efficient models tailored for satellite-based EO applications. The reproducible code is accessible on our GitHub repository.
On-board Satellite Image Classification for Earth Observation: A Comparative Study of Pre-Trained Vision Transformer Models
Sep 05, 2024



Remote sensing image classification is a critical component of Earth observation (EO) systems, traditionally dominated by convolutional neural networks (CNNs) and other deep learning techniques. However, the advent of Transformer-based architectures and large-scale pre-trained models has significantly shifted, offering enhanced performance and efficiency. This study focuses on identifying the most effective pre-trained model for land use classification in onboard satellite processing, emphasizing achieving high accuracy, computational efficiency, and robustness against noisy data conditions commonly encountered during satellite-based inference. Through extensive experimentation, we compared traditional CNN-based models, ResNet-based models, and various pre-trained vision Transformer models. Our findings demonstrate that pre-trained Transformer models, particularly MobileViTV2 and EfficientViT-M2, outperform models trained from scratch in accuracy and efficiency. These models achieve high performance with reduced computational requirements and exhibit greater resilience during inference under noisy conditions. While MobileViTV2 excelled on clean validation data, EfficientViT-M2 proved more robust when handling noise, making it the most suitable model for onboard satellite Earth observation tasks. In conclusion, EfficientViT-M2 is the optimal choice for reliable and efficient remote sensing image classification in satellite operations, achieving 98.76\% accuracy, precision, and recall. Specifically, EfficientViT-M2 delivered the highest performance across all metrics, excelled in training efficiency (1,000s) and inference time (10s), and demonstrated greater robustness (overall robustness score at 0.79).
The Impact of LoRA Adapters for LLMs on Clinical NLP Classification Under Data Limitations
Jul 27, 2024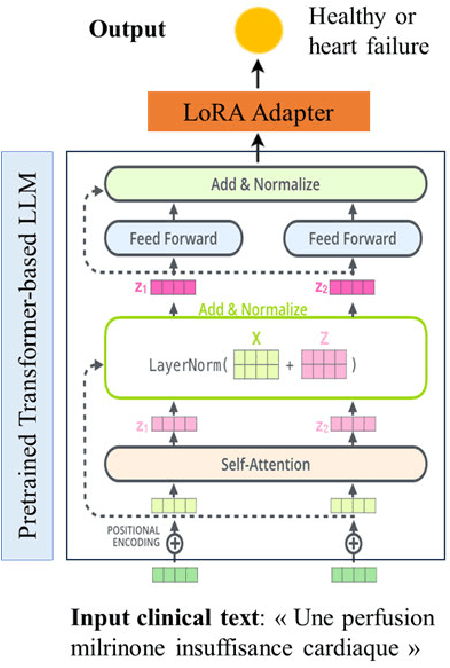

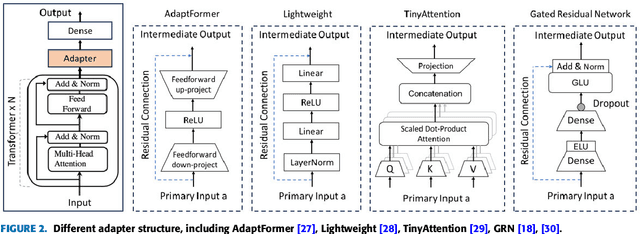

Fine-tuning Large Language Models (LLMs) for clinical Natural Language Processing (NLP) poses significant challenges due to the domain gap and limited data availability. This study investigates the effectiveness of various adapter techniques, equivalent to Low-Rank Adaptation (LoRA), for fine-tuning LLMs in a resource-constrained hospital environment. We experimented with four structures-Adapter, Lightweight, TinyAttention, and Gated Residual Network (GRN)-as final layers for clinical notes classification. We fine-tuned biomedical pre-trained models, including CamemBERT-bio, AliBERT, and DrBERT, alongside two Transformer-based models. Our extensive experimental results indicate that i) employing adapter structures does not yield significant improvements in fine-tuning biomedical pre-trained LLMs, and ii) simpler Transformer-based models, trained from scratch, perform better under resource constraints. Among the adapter structures, GRN demonstrated superior performance with accuracy, precision, recall, and an F1 score of 0.88. Moreover, the total training time for LLMs exceeded 1000 hours, compared to under 6 hours for simpler transformer-based models, highlighting that LLMs are more suitable for environments with extensive computational resources and larger datasets. Consequently, this study demonstrates that simpler Transformer-based models can be effectively trained from scratch, providing a viable solution for clinical NLP tasks in low-resource environments with limited data availability. By identifying the GRN as the most effective adapter structure, we offer a practical approach to enhance clinical note classification without requiring extensive computational resources.
A Hybrid Optimization and Deep RL Approach for Resource Allocation in Semi-GF NOMA Networks
Jul 18, 2023
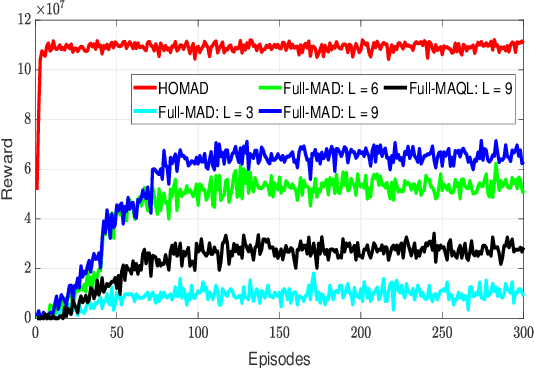
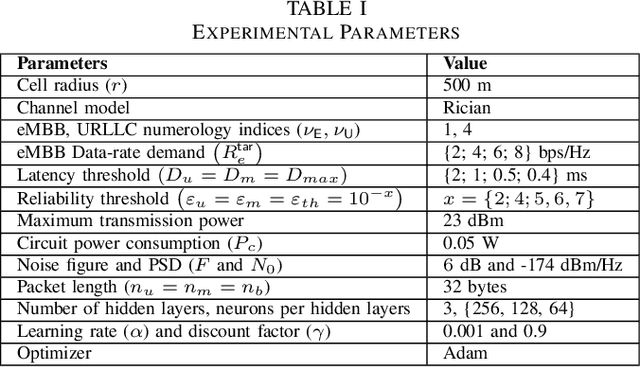
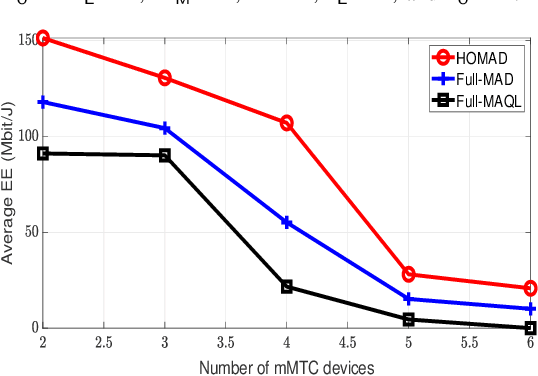
Semi-grant-free non-orthogonal multiple access (semi-GF NOMA) has emerged as a promising technology for the fifth-generation new radio (5G-NR) networks supporting the coexistence of a large number of random connections with various quality of service requirements. However, implementing a semi-GF NOMA mechanism in 5G-NR networks with heterogeneous services has raised several resource management problems relating to unpredictable interference caused by the GF access strategy. To cope with this challenge, the paper develops a novel hybrid optimization and multi-agent deep (HOMAD) reinforcement learning-based resource allocation design to maximize the energy efficiency (EE) of semi-GF NOMA 5G-NR systems. In this design, a multi-agent deep Q network (MADQN) approach is employed to conduct the subchannel assignment (SA) among users. While optimization-based methods are utilized to optimize the transmission power for every SA setting. In addition, a full MADQN scheme conducting both SA and power allocation is also considered for comparison purposes. Simulation results show that the HOMAD approach outperforms other benchmarks significantly in terms of the convergence time and average EE.