 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLUSE: Enhanced Channel-Wise Adaptive Gated Linear Units SE for Onboard Satellite Earth Observation Image Classification
Apr 16, 2025This study introduces ResNet-GLUSE, a lightweight ResNet variant enhanced with Gated Linear Unit-enhanced Squeeze-and-Excitation (GLUSE), an adaptive channel-wise attention mechanism. By integrating dynamic gating into the traditional SE framework, GLUSE improves feature recalibration while maintaining computational efficiency. Experiments on EuroSAT and PatternNet datasets confirm its effectiveness, achieving exceeding \textbf{94\% and 98\% accuracy}, respectively. While \textbf{MobileViT achieves 99\% accuracy}, ResNet-GLUSE offers \textbf{33x fewer parameters, 27x fewer FLOPs, 33x smaller model size (MB), $\approx$6x lower power consumption (W), and $\approx$3x faster inference time (s)}, making it significantly more efficient for onboard satellite deployment. Furthermore, due to its simplicity, ResNet-GLUSE can be easily mimicked for \textbf{neuromorphic computing}, enabling ultra-low power inference at just \textbf{852.30 mW} on Akida Brainchip. This balance between high accuracy and ultra-low resource consumption establishes ResNet-GLUSE as a practical solution for real-time Earth Observation (EO) tasks. Reproducible codes are available in our shared repository.
A Semantic-Loss Function Modeling Framework With Task-Oriented Machine Learning Perspectives
Mar 12, 2025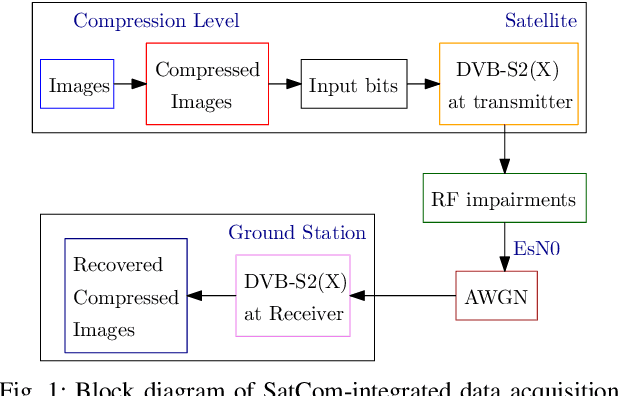
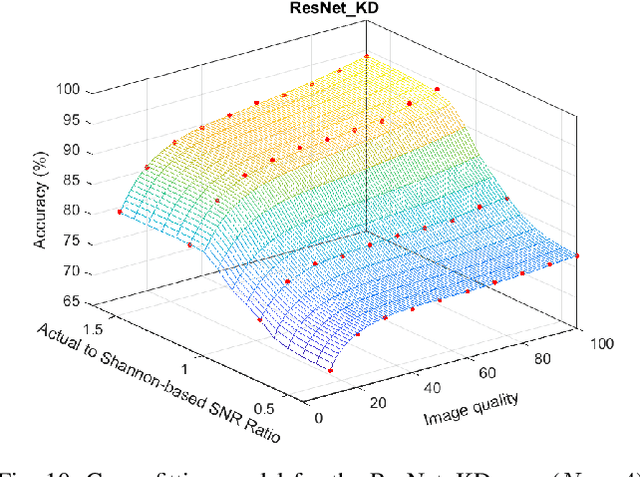
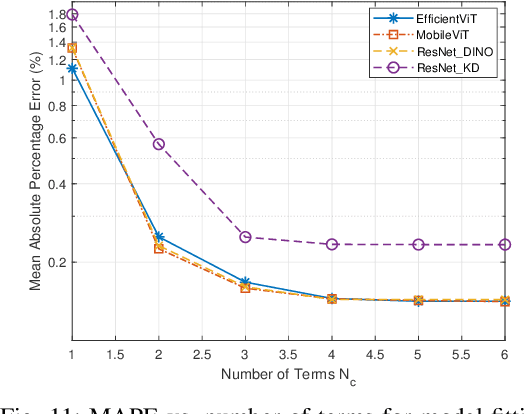

The integration of machine learning (ML) has significantly enhanced the capabilities of Earth Observation (EO) systems by enabling the extraction of actionable insights from complex datasets. However, the performance of data-driven EO applications is heavily influenced by the data collection and transmission processes, where limited satellite bandwidth and latency constraints can hinder the full transmission of original data to the receivers. To address this issue, adopting the concepts of Semantic Communication (SC) offers a promising solution by prioritizing the transmission of essential data semantics over raw information. Implementing SC for EO systems requires a thorough understanding of the impact of data processing and communication channel conditions on semantic loss at the processing center. This work proposes a novel data-fitting framework to empirically model the semantic loss using real-world EO datasets and domain-specific insights. The framework quantifies two primary types of semantic loss: (1) source coding loss, assessed via a data quality indicator measuring the impact of processing on raw source data, and (2) transmission loss, evaluated by comparing practical transmission performance against the Shannon limit. Semantic losses are estimated by evaluating the accuracy of EO applications using four task-oriented ML models, EfficientViT, MobileViT, ResNet50-DINO, and ResNet8-KD, on lossy image datasets under varying channel conditions and compression ratios. These results underpin a framework for efficient semantic-loss modeling in bandwidth-constrained EO scenarios, enabling more reliable and effective operations.
Semantic Knowledge Distillation for Onboard Satellite Earth Observation Image Classification
Oct 31, 2024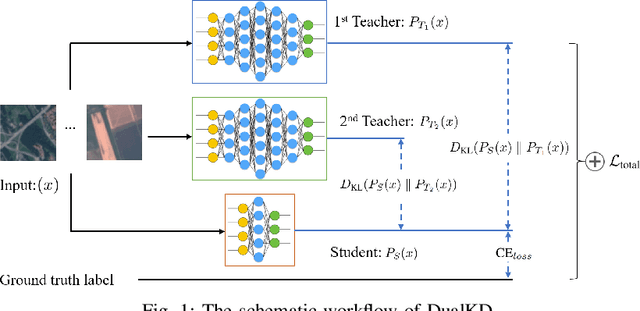
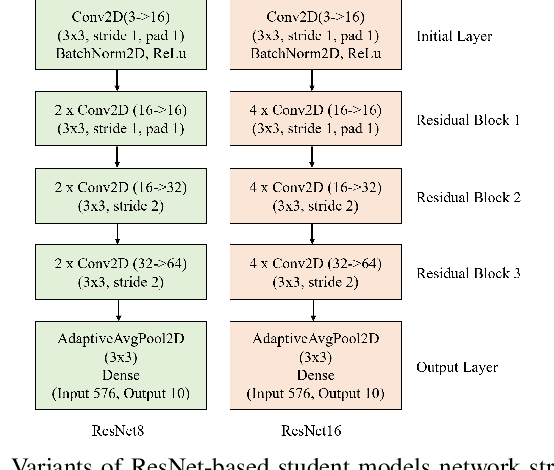
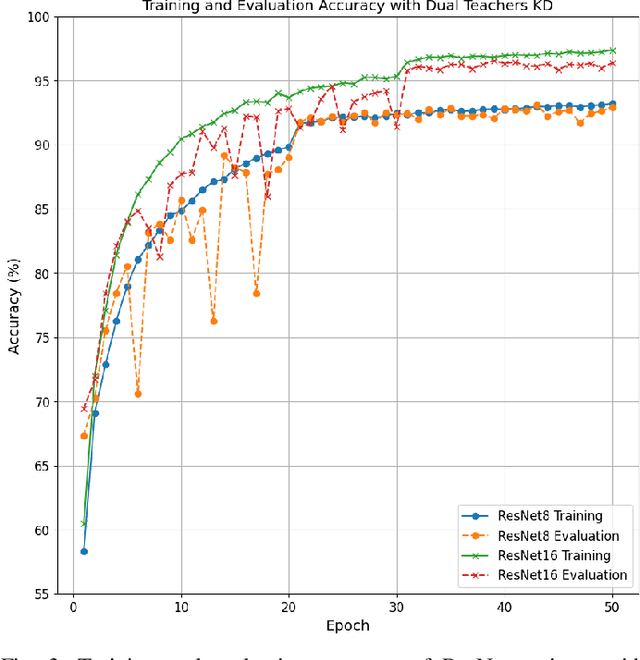
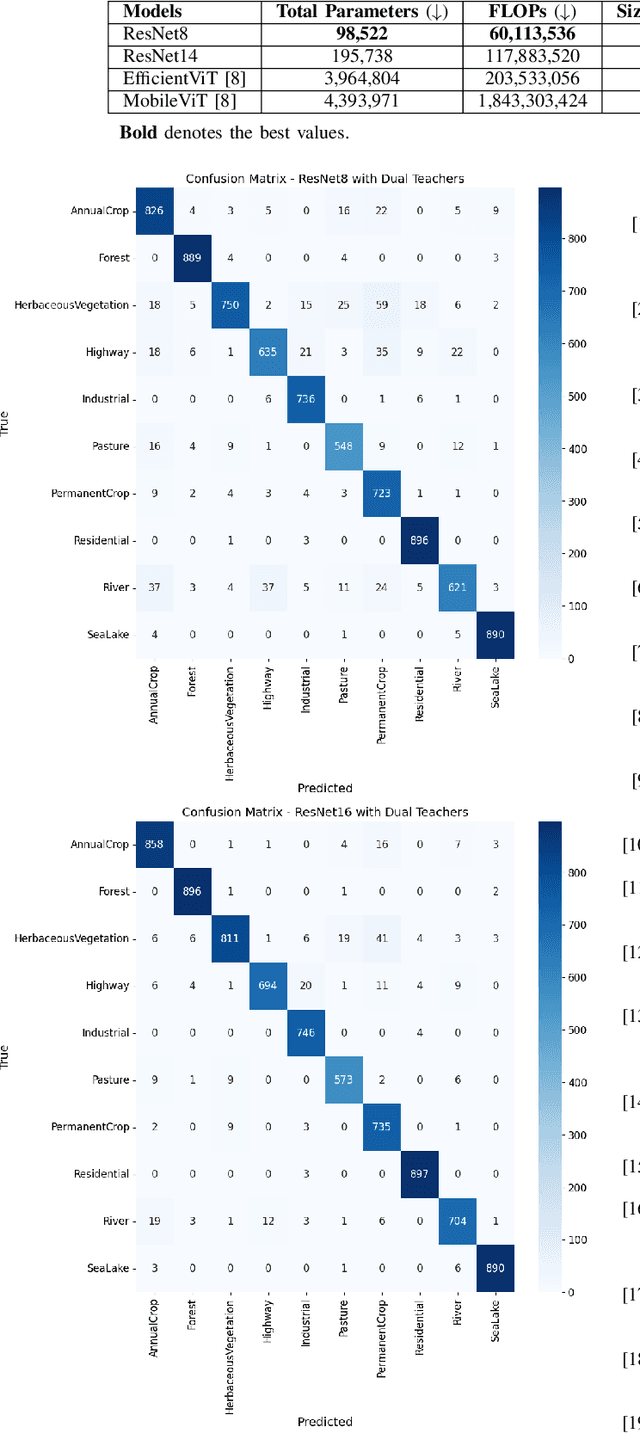
This study presents an innovative dynamic weighting knowledge distillation (KD) framework tailored for efficient Earth observation (EO) image classification (IC) in resource-constrained settings. Utilizing EfficientViT and MobileViT as teacher models, this framework enables lightweight student models, particularly ResNet8 and ResNet16, to surpass 90% in accuracy, precision, and recall, adhering to the stringent confidence thresholds necessary for reliable classification tasks. Unlike conventional KD methods that rely on static weight distribution, our adaptive weighting mechanism responds to each teacher model's confidence, allowing student models to prioritize more credible sources of knowledge dynamically. Remarkably, ResNet8 delivers substantial efficiency gains, achieving a 97.5% reduction in parameters, a 96.7% decrease in FLOPs, an 86.2% cut in power consumption, and a 63.5% increase in inference speed over MobileViT. This significant optimization of complexity and resource demands establishes ResNet8 as an optimal candidate for EO tasks, combining robust performance with feasibility in deployment. The confidence-based, adaptable KD approach underscores the potential of dynamic distillation strategies to yield high-performing, resource-efficient models tailored for satellite-based EO applications. The reproducible code is accessible on our GitHub repository.
On-board Satellite Image Classification for Earth Observation: A Comparative Study of Pre-Trained Vision Transformer Models
Sep 05, 2024



Remote sensing image classification is a critical component of Earth observation (EO) systems, traditionally dominated by convolutional neural networks (CNNs) and other deep learning techniques. However, the advent of Transformer-based architectures and large-scale pre-trained models has significantly shifted, offering enhanced performance and efficiency. This study focuses on identifying the most effective pre-trained model for land use classification in onboard satellite processing, emphasizing achieving high accuracy, computational efficiency, and robustness against noisy data conditions commonly encountered during satellite-based inference. Through extensive experimentation, we compared traditional CNN-based models, ResNet-based models, and various pre-trained vision Transformer models. Our findings demonstrate that pre-trained Transformer models, particularly MobileViTV2 and EfficientViT-M2, outperform models trained from scratch in accuracy and efficiency. These models achieve high performance with reduced computational requirements and exhibit greater resilience during inference under noisy conditions. While MobileViTV2 excelled on clean validation data, EfficientViT-M2 proved more robust when handling noise, making it the most suitable model for onboard satellite Earth observation tasks. In conclusion, EfficientViT-M2 is the optimal choice for reliable and efficient remote sensing image classification in satellite operations, achieving 98.76\% accuracy, precision, and recall. Specifically, EfficientViT-M2 delivered the highest performance across all metrics, excelled in training efficiency (1,000s) and inference time (10s), and demonstrated greater robustness (overall robustness score at 0.79).
Joint Source-Channel Coding System for 6G Communication: Design, Prototype and Future Directions
Oct 02, 2023The goal of semantic communication is to surpass optimal Shannon's criterion regarding a notable problem for future communication which lies in the integration of collaborative efforts between the intelligence of the transmission source and the joint design of source coding and channel coding. The convergence of scholarly investigation and applicable products in the field of semantic communication is facilitated by the utilization of flexible structural hardware design, which is constrained by the computational capabilities of edge devices. This characteristic represents a significant benefit of joint source-channel coding (JSCC), as it enables the generation of source alphabets with diverse lengths and achieves a code rate of unity. Moreover, JSCC exhibits near-capacity performance while maintaining low complexity. Therefore, we leverage not only quasi-cyclic (QC) characteristics to propose a QC-LDPC code-based JSCC scheme but also Unequal Error Protection (UEP) to ensure the recovery of semantic importance. In this study, the feasibility for using a semantic encoder/decoder that is aware of UEP can be explored based on the existing JSCC system. This approach is aimed at protecting the significance of semantic task-oriented information. Additionally, the deployment of a JSCC system can be facilitated by employing Low-Density Parity-Check (LDPC) codes on a reconfigurable device. This is achieved by reconstructing the LDPC codes as QC-LDPC codes. The QC-LDPC layered decoding technique, which has been specifically optimized for hardware parallelism and tailored for channel decoding applications, can be suitably adapted to accommodate the JSCC system. The performance of the proposed system is evaluated by conducting BER measurements using both floating-point and 6-bit quantization.