 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Impact of LoRA Adapters for LLMs on Clinical NLP Classification Under Data Limitations
Paper and Code
Jul 27, 2024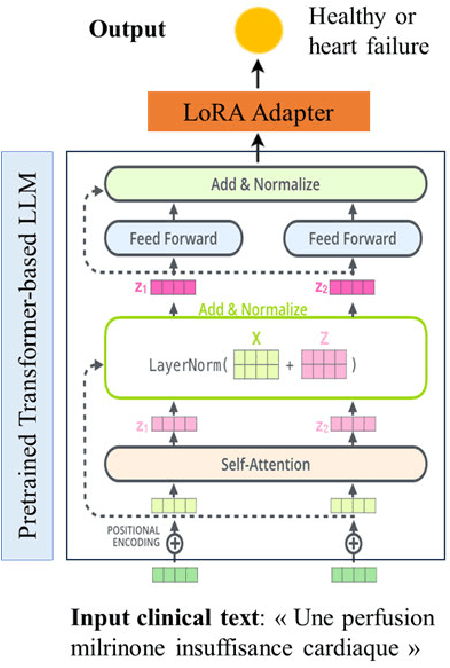

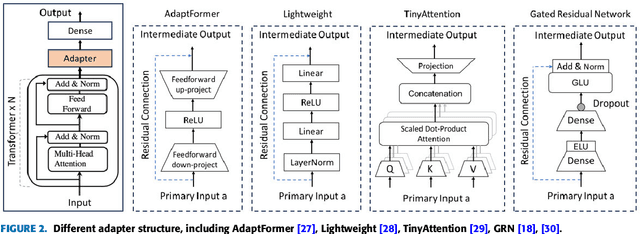

Fine-tuning Large Language Models (LLMs) for clinical Natural Language Processing (NLP) poses significant challenges due to the domain gap and limited data availability. This study investigates the effectiveness of various adapter techniques, equivalent to Low-Rank Adaptation (LoRA), for fine-tuning LLMs in a resource-constrained hospital environment. We experimented with four structures-Adapter, Lightweight, TinyAttention, and Gated Residual Network (GRN)-as final layers for clinical notes classification. We fine-tuned biomedical pre-trained models, including CamemBERT-bio, AliBERT, and DrBERT, alongside two Transformer-based models. Our extensive experimental results indicate that i) employing adapter structures does not yield significant improvements in fine-tuning biomedical pre-trained LLMs, and ii) simpler Transformer-based models, trained from scratch, perform better under resource constraints. Among the adapter structures, GRN demonstrated superior performance with accuracy, precision, recall, and an F1 score of 0.88. Moreover, the total training time for LLMs exceeded 1000 hours, compared to under 6 hours for simpler transformer-based models, highlighting that LLMs are more suitable for environments with extensive computational resources and larger datasets. Consequently, this study demonstrates that simpler Transformer-based models can be effectively trained from scratch, providing a viable solution for clinical NLP tasks in low-resource environments with limited data availability. By identifying the GRN as the most effective adapter structure, we offer a practical approach to enhance clinical note classification without requiring extensive computational resources.