 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToo Long, Didn't Model: Decomposing LLM Long-Context Understanding With Novels
May 20, 2025Although the context length of large language models (LLMs) has increased to millions of tokens, evaluating their effectiveness beyond needle-in-a-haystack approaches has proven difficult. We argue that novels provide a case study of subtle, complicated structure and long-range semantic dependencies often over 128k tokens in length. Inspired by work on computational novel analysis, we release the Too Long, Didn't Model (TLDM) benchmark, which tests a model's ability to report plot summary, storyworld configuration, and elapsed narrative time. We find that none of seven tested frontier LLMs retain stable understanding beyond 64k tokens. Our results suggest language model developers must look beyond "lost in the middle" benchmarks when evaluating model performance in complex long-context scenarios. To aid in further development we release the TLDM benchmark together with reference code and data.
Can Language Models Represent the Past without Anachronism?
Apr 28, 2025

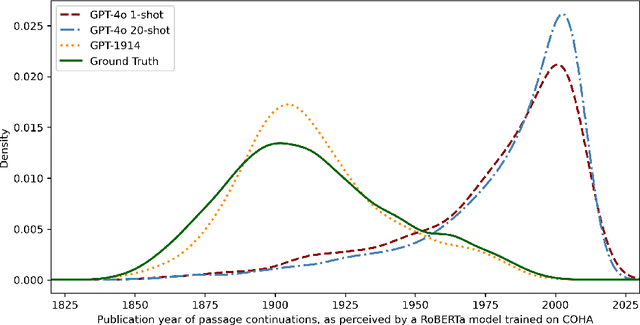
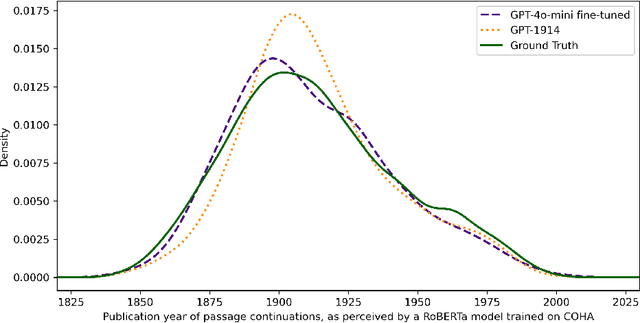
Before researchers can use language models to simulate the past, they need to understand the risk of anachronism. We find that prompting a contemporary model with examples of period prose does not produce output consistent with period style. Fine-tuning produces results that are stylistically convincing enough to fool an automated judge, but human evaluators can still distinguish fine-tuned model outputs from authentic historical text. We tentatively conclude that pretraining on period prose may be required in order to reliably simulate historical perspectives for social research.
Tasks and Roles in Legal AI: Data Curation, Annotation, and Verification
Apr 02, 2025The application of AI tools to the legal field feels natural: large legal document collections could be used with specialized AI to improve workflow efficiency for lawyers and ameliorate the "justice gap" for underserved clients. However, legal documents differ from the web-based text that underlies most AI systems. The challenges of legal AI are both specific to the legal domain, and confounded with the expectation of AI's high performance in high-stakes settings. We identify three areas of special relevance to practitioners: data curation, data annotation, and output verification. First, it is difficult to obtain usable legal texts. Legal collections are inconsistent, analog, and scattered for reasons technical, economic, and jurisdictional. AI tools can assist document curation efforts, but the lack of existing data also limits AI performance. Second, legal data annotation typically requires significant expertise to identify complex phenomena such as modes of judicial reasoning or controlling precedents. We describe case studies of AI systems that have been developed to improve the efficiency of human annotation in legal contexts and identify areas of underperformance. Finally, AI-supported work in the law is valuable only if results are verifiable and trustworthy. We describe both the abilities of AI systems to support evaluation of their outputs, as well as new approaches to systematic evaluation of computational systems in complex domains. We call on both legal and AI practitioners to collaborate across disciplines and to release open access materials to support the development of novel, high-performing, and reliable AI tools for legal applications.
A City of Millions: Mapping Literary Social Networks At Scale
Feb 26, 2025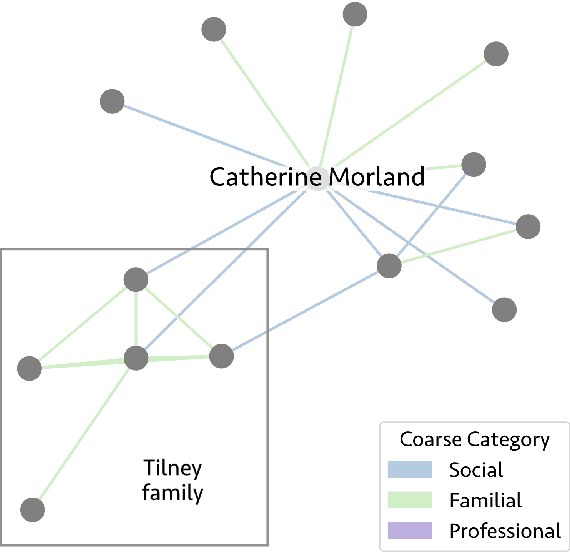
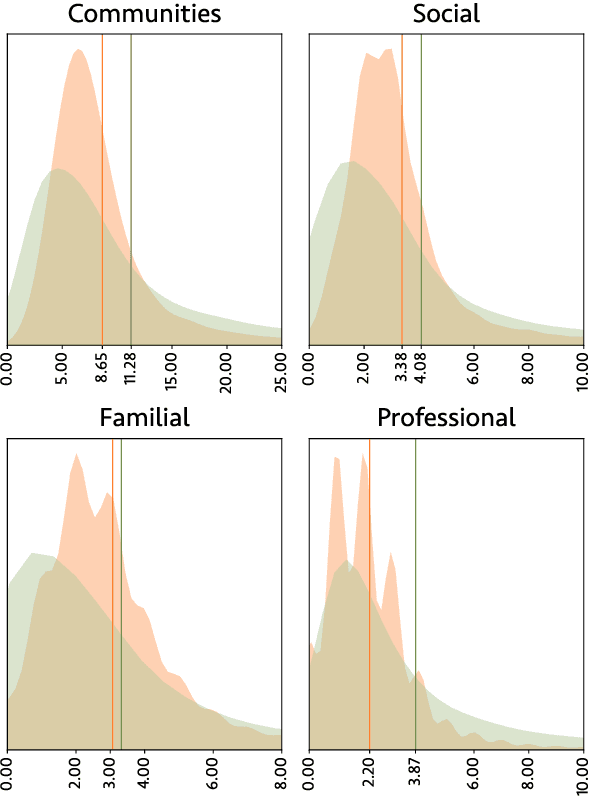
We release 70,509 high-quality social networks extracted from multilingual fiction and nonfiction narratives. We additionally provide metadata for ~30,000 of these texts (73% nonfiction and 27% fiction) written between 1800 and 1999 in 58 languages. This dataset provides information on historical social worlds at an unprecedented scale, including data for 1,192,855 individuals in 2,805,482 pair-wise relationships annotated for affinity and relationship type. We achieve this scale by automating previously manual methods of extracting social networks; specifically, we adapt an existing annotation task as a language model prompt, ensuring consistency at scale with the use of structured output. This dataset provides an unprecedented resource for the humanities and social sciences by providing data on cognitive models of social realities.
The Afterlives of Shakespeare and Company in Online Social Readership
Jan 14, 2024



The growth of social reading platforms such as Goodreads and LibraryThing enables us to analyze reading activity at very large scale and in remarkable detail. But twenty-first century systems give us a perspective only on contemporary readers. Meanwhile, the digitization of the lending library records of Shakespeare and Company provides a window into the reading activity of an earlier, smaller community in interwar Paris. In this article, we explore the extent to which we can make comparisons between the Shakespeare and Company and Goodreads communities. By quantifying similarities and differences, we can identify patterns in how works have risen or fallen in popularity across these datasets. We can also measure differences in how works are received by measuring similarities and differences in co-reading patterns. Finally, by examining the complete networks of co-readership, we can observe changes in the overall structures of literary reception.
Modeling Legal Reasoning: LM Annotation at the Edge of Human Agreement
Oct 27, 2023Generative language models (LMs) are increasingly used for document class-prediction tasks and promise enormous improvements in cost and efficiency. Existing research often examines simple classification tasks, but the capability of LMs to classify on complex or specialized tasks is less well understood. We consider a highly complex task that is challenging even for humans: the classification of legal reasoning according to jurisprudential philosophy. Using a novel dataset of historical United States Supreme Court opinions annotated by a team of domain experts, we systematically test the performance of a variety of LMs. We find that generative models perform poorly when given instructions (i.e. prompts) equal to the instructions presented to human annotators through our codebook. Our strongest results derive from fine-tuning models on the annotated dataset; the best performing model is an in-domain model, LEGAL-BERT. We apply predictions from this fine-tuned model to study historical trends in jurisprudence, an exercise that both aligns with prominent qualitative historical accounts and points to areas of possible refinement in those accounts. Our findings generally sound a note of caution in the use of generative LMs on complex tasks without fine-tuning and point to the continued relevance of human annotation-intensive classification methods.
Grounding Characters and Places in Narrative Texts
May 27, 2023

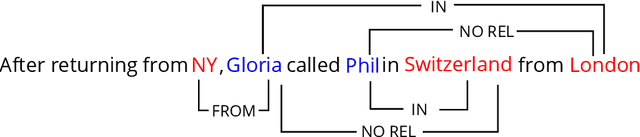

Tracking characters and locations throughout a story can help improve the understanding of its plot structure. Prior research has analyzed characters and locations from text independently without grounding characters to their locations in narrative time. Here, we address this gap by proposing a new spatial relationship categorization task. The objective of the task is to assign a spatial relationship category for every character and location co-mention within a window of text, taking into consideration linguistic context, narrative tense, and temporal scope. To this end, we annotate spatial relationships in approximately 2500 book excerpts and train a model using contextual embeddings as features to predict these relationships. When applied to a set of books, this model allows us to test several hypotheses on mobility and domestic space, revealing that protagonists are more mobile than non-central characters and that women as characters tend to occupy more interior space than men. Overall, our work is the first step towards joint modeling and analysis of characters and places in narrative text.