 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStronger Random Baselines for In-Context Learning
Apr 19, 2024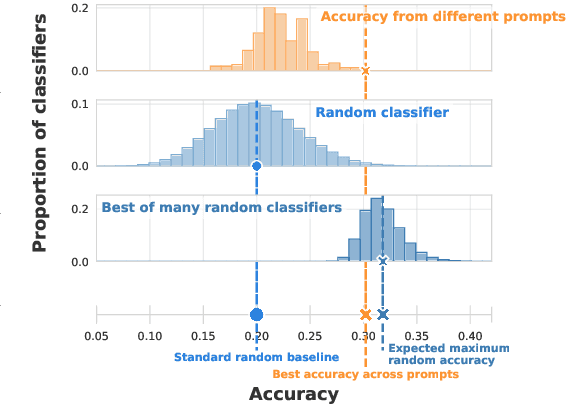
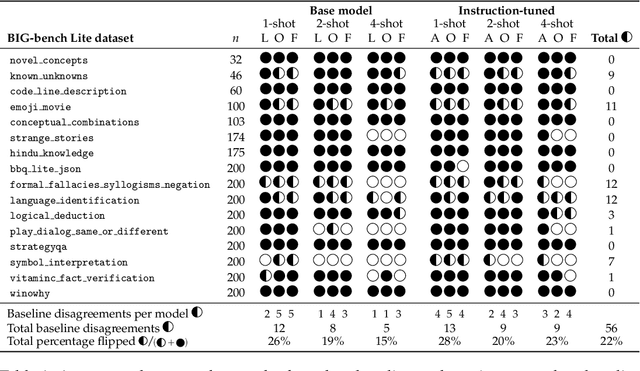
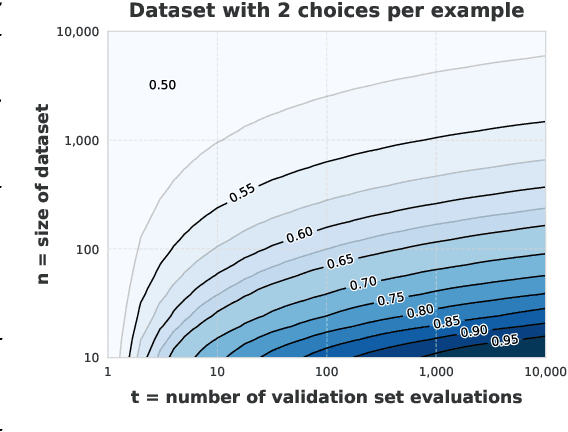
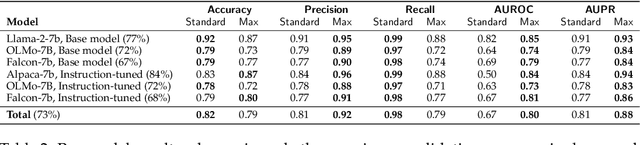
Evaluating the in-context learning classification performance of language models poses challenges due to small dataset sizes, extensive prompt-selection using the validation set, and intentionally difficult tasks that lead to near-random performance. The standard random baseline -- the expected accuracy of guessing labels uniformly at random -- is stable when the evaluation set is used only once or when the dataset is large. We account for the common practice of validation set reuse and existing small datasets with a stronger random baseline: the expected maximum accuracy across multiple random classifiers. When choosing the best prompt demonstrations across six quantized language models applied to 16 BIG-bench Lite tasks, more than 20\% of the few-shot results that exceed the standard baseline do not exceed this stronger random baseline. When held-out test sets are available, this stronger baseline is also a better predictor of held-out performance than the standard baseline, avoiding unnecessary test set evaluations. This maximum random baseline provides an easily calculated drop-in replacement for the standard baseline.
The Afterlives of Shakespeare and Company in Online Social Readership
Jan 14, 2024



The growth of social reading platforms such as Goodreads and LibraryThing enables us to analyze reading activity at very large scale and in remarkable detail. But twenty-first century systems give us a perspective only on contemporary readers. Meanwhile, the digitization of the lending library records of Shakespeare and Company provides a window into the reading activity of an earlier, smaller community in interwar Paris. In this article, we explore the extent to which we can make comparisons between the Shakespeare and Company and Goodreads communities. By quantifying similarities and differences, we can identify patterns in how works have risen or fallen in popularity across these datasets. We can also measure differences in how works are received by measuring similarities and differences in co-reading patterns. Finally, by examining the complete networks of co-readership, we can observe changes in the overall structures of literary reception.
Data Similarity is Not Enough to Explain Language Model Performance
Nov 15, 2023Large language models achieve high performance on many but not all downstream tasks. The interaction between pretraining data and task data is commonly assumed to determine this variance: a task with data that is more similar to a model's pretraining data is assumed to be easier for that model. We test whether distributional and example-specific similarity measures (embedding-, token- and model-based) correlate with language model performance through a large-scale comparison of the Pile and C4 pretraining datasets with downstream benchmarks. Similarity correlates with performance for multilingual datasets, but in other benchmarks, we surprisingly find that similarity metrics are not correlated with accuracy or even each other. This suggests that the relationship between pretraining data and downstream tasks is more complex than often assumed.
A Pretrainer's Guide to Training Data: Measuring the Effects of Data Age, Domain Coverage, Quality, & Toxicity
May 22, 2023



Pretraining is the preliminary and fundamental step in developing capable language models (LM). Despite this, pretraining data design is critically under-documented and often guided by empirically unsupported intuitions. To address this, we pretrain 28 1.5B parameter decoder-only models, training on data curated (1) at different times, (2) with varying toxicity and quality filters, and (3) with different domain compositions. First, we quantify the effect of pretraining data age. A temporal shift between evaluation data and pretraining data leads to performance degradation, which is not overcome by finetuning. Second, we explore the effect of quality and toxicity filters, showing a trade-off between performance on standard benchmarks and risk of toxic generations. Our findings indicate there does not exist a one-size-fits-all solution to filtering training data. We also find that the effects of different types of filtering are not predictable from text domain characteristics. Lastly, we empirically validate that the inclusion of heterogeneous data sources, like books and web, is broadly beneficial and warrants greater prioritization. These findings constitute the largest set of experiments to validate, quantify, and expose many undocumented intuitions about text pretraining, which we hope will help support more informed data-centric decisions in LM development.
Comparing Text Representations: A Theory-Driven Approach
Sep 15, 2021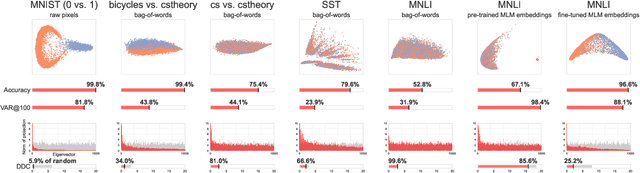



Much of the progress in contemporary NLP has come from learning representations, such as masked language model (MLM) contextual embeddings, that turn challenging problems into simple classification tasks. But how do we quantify and explain this effect? We adapt general tools from computational learning theory to fit the specific characteristics of text datasets and present a method to evaluate the compatibility between representations and tasks. Even though many tasks can be easily solved with simple bag-of-words (BOW) representations, BOW does poorly on hard natural language inference tasks. For one such task we find that BOW cannot distinguish between real and randomized labelings, while pre-trained MLM representations show 72x greater distinction between real and random labelings than BOW. This method provides a calibrated, quantitative measure of the difficulty of a classification-based NLP task, enabling comparisons between representations without requiring empirical evaluations that may be sensitive to initializations and hyperparameters. The method provides a fresh perspective on the patterns in a dataset and the alignment of those patterns with specific labels.
Domain-Specific Lexical Grounding in Noisy Visual-Textual Documents
Oct 30, 2020



Images can give us insights into the contextual meanings of words, but current image-text grounding approaches require detailed annotations. Such granular annotation is rare, expensive, and unavailable in most domain-specific contexts. In contrast, unlabeled multi-image, multi-sentence documents are abundant. Can lexical grounding be learned from such documents, even though they have significant lexical and visual overlap? Working with a case study dataset of real estate listings, we demonstrate the challenge of distinguishing highly correlated grounded terms, such as "kitchen" and "bedroom", and introduce metrics to assess this document similarity. We present a simple unsupervised clustering-based method that increases precision and recall beyond object detection and image tagging baselines when evaluated on labeled subsets of the dataset. The proposed method is particularly effective for local contextual meanings of a word, for example associating "granite" with countertops in the real estate dataset and with rocky landscapes in a Wikipedia dataset.
Automated Process Incorporating Machine Learning Segmentation and Correlation of Oral Diseases with Systemic Health
Oct 25, 2018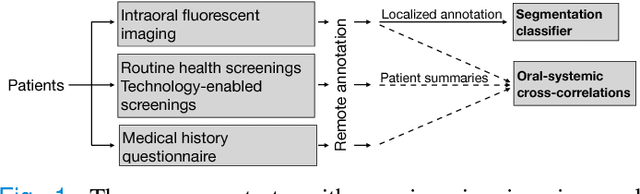

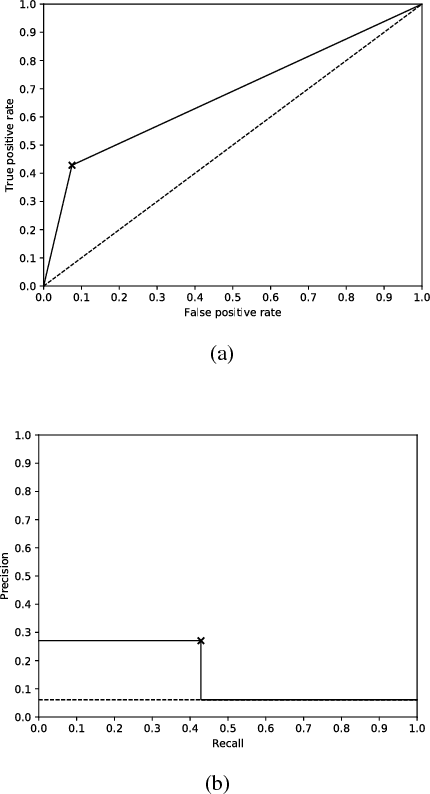
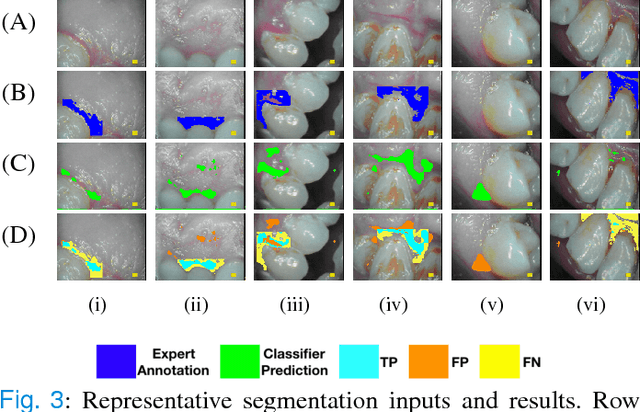
Imaging fluorescent disease biomarkers in tissues and skin is a non-invasive method to screen for health conditions. We report an automated process that combines intraoral fluorescent porphyrin biomarker imaging, clinical examinations and machine learning for correlation of systemic health conditions with periodontal disease. 1215 intraoral fluorescent images, from 284 consenting adults aged 18-90, were analyzed using a machine learning classifier that can segment periodontal inflammation. The classifier achieved an AUC of 0.677 with precision and recall of 0.271 and 0.429, respectively, indicating a learned association between disease signatures in collected images. Periodontal diseases were more prevalent among males (p=0.0012) and older subjects (p=0.0224) in the screened population. Physicians independently examined the collected images, assigning localized modified gingival indices (MGIs). MGIs and periodontal disease were then cross-correlated with responses to a medical history questionnaire, blood pressure and body mass index measurements, and optic nerve, tympanic membrane, neurological, and cardiac rhythm imaging examinations. Gingivitis and early periodontal disease were associated with subjects diagnosed with optic nerve abnormalities (p <0.0001) in their retinal scans. We also report significant co-occurrences of periodontal disease in subjects reporting swollen joints (p=0.0422) and a family history of eye disease (p=0.0337). These results indicate cross-correlation of poor periodontal health with systemic health outcomes and stress the importance of oral health screenings at the primary care level. Our screening process and analysis method, using images and machine learning, can be generalized for automated diagnoses and systemic health screenings for other diseases.