 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRisks of Cultural Erasure in Large Language Models
Jan 02, 2025



Large language models are increasingly being integrated into applications that shape the production and discovery of societal knowledge such as search, online education, and travel planning. As a result, language models will shape how people learn about, perceive and interact with global cultures making it important to consider whose knowledge systems and perspectives are represented in models. Recognizing this importance, increasingly work in Machine Learning and NLP has focused on evaluating gaps in global cultural representational distribution within outputs. However, more work is needed on developing benchmarks for cross-cultural impacts of language models that stem from a nuanced sociologically-aware conceptualization of cultural impact or harm. We join this line of work arguing for the need of metricizable evaluations of language technologies that interrogate and account for historical power inequities and differential impacts of representation on global cultures, particularly for cultures already under-represented in the digital corpora. We look at two concepts of erasure: omission: where cultures are not represented at all and simplification i.e. when cultural complexity is erased by presenting one-dimensional views of a rich culture. The former focuses on whether something is represented, and the latter on how it is represented. We focus our analysis on two task contexts with the potential to influence global cultural production. First, we probe representations that a language model produces about different places around the world when asked to describe these contexts. Second, we analyze the cultures represented in the travel recommendations produced by a set of language model applications. Our study shows ways in which the NLP community and application developers can begin to operationalize complex socio-cultural considerations into standard evaluations and benchmarks.
SeeGULL Multilingual: a Dataset of Geo-Culturally Situated Stereotypes
Mar 08, 2024



While generative multilingual models are rapidly being deployed, their safety and fairness evaluations are largely limited to resources collected in English. This is especially problematic for evaluations targeting inherently socio-cultural phenomena such as stereotyping, where it is important to build multi-lingual resources that reflect the stereotypes prevalent in respective language communities. However, gathering these resources, at scale, in varied languages and regions pose a significant challenge as it requires broad socio-cultural knowledge and can also be prohibitively expensive. To overcome this critical gap, we employ a recently introduced approach that couples LLM generations for scale with culturally situated validations for reliability, and build SeeGULL Multilingual, a global-scale multilingual dataset of social stereotypes, containing over 25K stereotypes, spanning 20 languages, with human annotations across 23 regions, and demonstrate its utility in identifying gaps in model evaluations. Content warning: Stereotypes shared in this paper can be offensive.
MiTTenS: A Dataset for Evaluating Misgendering in Translation
Jan 13, 2024



Misgendering is the act of referring to someone in a way that does not reflect their gender identity. Translation systems, including foundation models capable of translation, can produce errors that result in misgendering harms. To measure the extent of such potential harms when translating into and out of English, we introduce a dataset, MiTTenS, covering 26 languages from a variety of language families and scripts, including several traditionally underpresented in digital resources. The dataset is constructed with handcrafted passages that target known failure patterns, longer synthetically generated passages, and natural passages sourced from multiple domains. We demonstrate the usefulness of the dataset by evaluating both dedicated neural machine translation systems and foundation models, and show that all systems exhibit errors resulting in misgendering harms, even in high resource languages.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
AART: AI-Assisted Red-Teaming with Diverse Data Generation for New LLM-powered Applications
Nov 29, 2023Adversarial testing of large language models (LLMs) is crucial for their safe and responsible deployment. We introduce a novel approach for automated generation of adversarial evaluation datasets to test the safety of LLM generations on new downstream applications. We call it AI-assisted Red-Teaming (AART) - an automated alternative to current manual red-teaming efforts. AART offers a data generation and augmentation pipeline of reusable and customizable recipes that reduce human effort significantly and enable integration of adversarial testing earlier in new product development. AART generates evaluation datasets with high diversity of content characteristics critical for effective adversarial testing (e.g. sensitive and harmful concepts, specific to a wide range of cultural and geographic regions and application scenarios). The data generation is steered by AI-assisted recipes to define, scope and prioritize diversity within the application context. This feeds into a structured LLM-generation process that scales up evaluation priorities. Compared to some state-of-the-art tools, AART shows promising results in terms of concept coverage and data quality.
A Pretrainer's Guide to Training Data: Measuring the Effects of Data Age, Domain Coverage, Quality, & Toxicity
May 22, 2023



Pretraining is the preliminary and fundamental step in developing capable language models (LM). Despite this, pretraining data design is critically under-documented and often guided by empirically unsupported intuitions. To address this, we pretrain 28 1.5B parameter decoder-only models, training on data curated (1) at different times, (2) with varying toxicity and quality filters, and (3) with different domain compositions. First, we quantify the effect of pretraining data age. A temporal shift between evaluation data and pretraining data leads to performance degradation, which is not overcome by finetuning. Second, we explore the effect of quality and toxicity filters, showing a trade-off between performance on standard benchmarks and risk of toxic generations. Our findings indicate there does not exist a one-size-fits-all solution to filtering training data. We also find that the effects of different types of filtering are not predictable from text domain characteristics. Lastly, we empirically validate that the inclusion of heterogeneous data sources, like books and web, is broadly beneficial and warrants greater prioritization. These findings constitute the largest set of experiments to validate, quantify, and expose many undocumented intuitions about text pretraining, which we hope will help support more informed data-centric decisions in LM development.
PaLM 2 Technical Report
May 17, 2023



We introduce PaLM 2, a new state-of-the-art language model that has better multilingual and reasoning capabilities and is more compute-efficient than its predecessor PaLM. PaLM 2 is a Transformer-based model trained using a mixture of objectives. Through extensive evaluations on English and multilingual language, and reasoning tasks, we demonstrate that PaLM 2 has significantly improved quality on downstream tasks across different model sizes, while simultaneously exhibiting faster and more efficient inference compared to PaLM. This improved efficiency enables broader deployment while also allowing the model to respond faster, for a more natural pace of interaction. PaLM 2 demonstrates robust reasoning capabilities exemplified by large improvements over PaLM on BIG-Bench and other reasoning tasks. PaLM 2 exhibits stable performance on a suite of responsible AI evaluations, and enables inference-time control over toxicity without additional overhead or impact on other capabilities. Overall, PaLM 2 achieves state-of-the-art performance across a diverse set of tasks and capabilities. When discussing the PaLM 2 family, it is important to distinguish between pre-trained models (of various sizes), fine-tuned variants of these models, and the user-facing products that use these models. In particular, user-facing products typically include additional pre- and post-processing steps. Additionally, the underlying models may evolve over time. Therefore, one should not expect the performance of user-facing products to exactly match the results reported in this report.
PaLM: Scaling Language Modeling with Pathways
Apr 19, 2022



Large language models have been shown to achieve remarkable performance across a variety of natural language tasks using few-shot learning, which drastically reduces the number of task-specific training examples needed to adapt the model to a particular application. To further our understanding of the impact of scale on few-shot learning, we trained a 540-billion parameter, densely activated, Transformer language model, which we call Pathways Language Model PaLM. We trained PaLM on 6144 TPU v4 chips using Pathways, a new ML system which enables highly efficient training across multiple TPU Pods. We demonstrate continued benefits of scaling by achieving state-of-the-art few-shot learning results on hundreds of language understanding and generation benchmarks. On a number of these tasks, PaLM 540B achieves breakthrough performance, outperforming the finetuned state-of-the-art on a suite of multi-step reasoning tasks, and outperforming average human performance on the recently released BIG-bench benchmark. A significant number of BIG-bench tasks showed discontinuous improvements from model scale, meaning that performance steeply increased as we scaled to our largest model. PaLM also has strong capabilities in multilingual tasks and source code generation, which we demonstrate on a wide array of benchmarks. We additionally provide a comprehensive analysis on bias and toxicity, and study the extent of training data memorization with respect to model scale. Finally, we discuss the ethical considerations related to large language models and discuss potential mitigation strategies.
GLaM: Efficient Scaling of Language Models with Mixture-of-Experts
Dec 13, 2021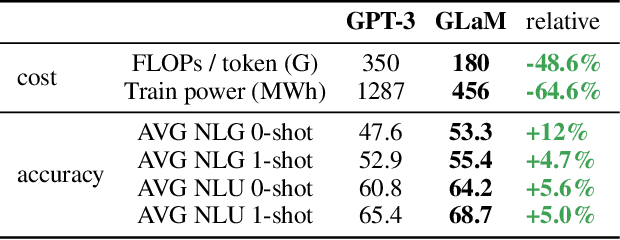
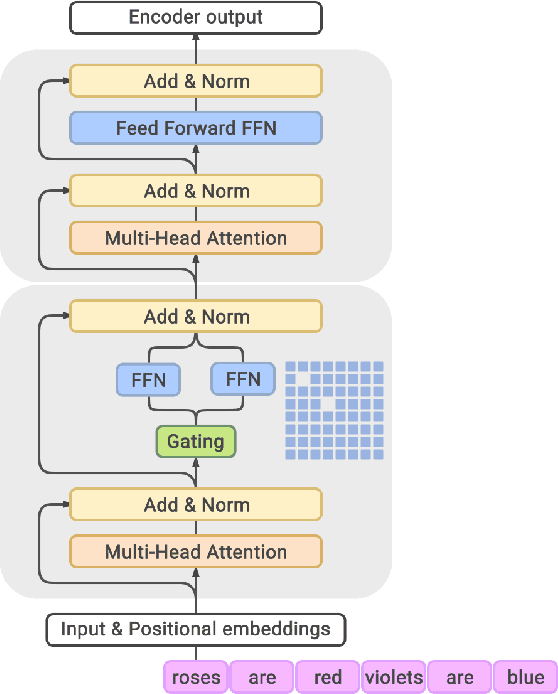
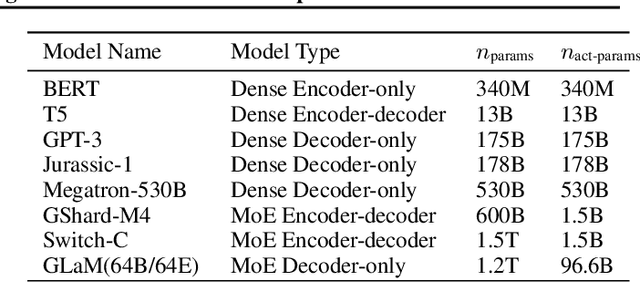
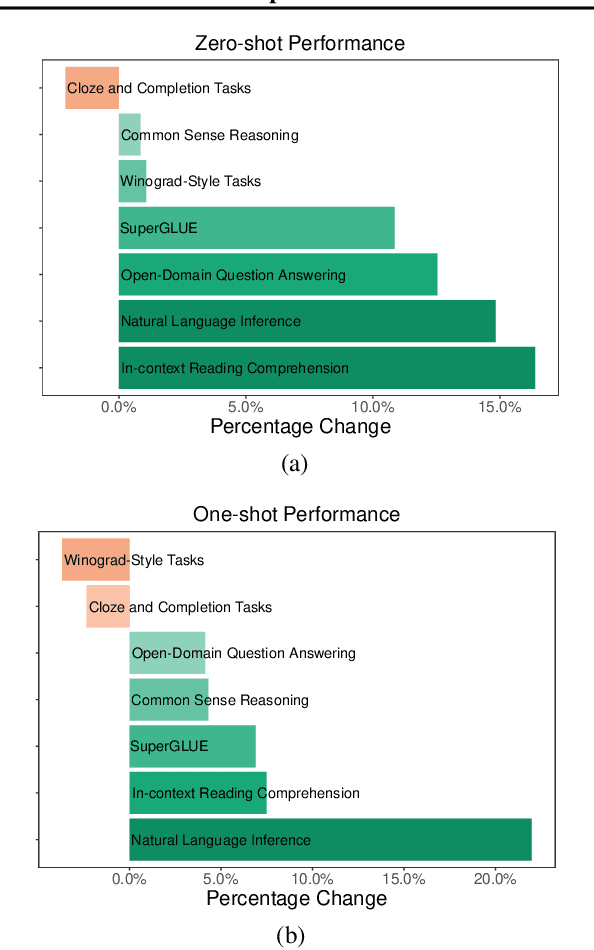
Scaling language models with more data, compute and parameters has driven significant progress in natural language processing. For example, thanks to scaling, GPT-3 was able to achieve strong results on in-context learning tasks. However, training these large dense models requires significant amounts of computing resources. In this paper, we propose and develop a family of language models named GLaM (Generalist Language Model), which uses a sparsely activated mixture-of-experts architecture to scale the model capacity while also incurring substantially less training cost compared to dense variants. The largest GLaM has 1.2 trillion parameters, which is approximately 7x larger than GPT-3. It consumes only 1/3 of the energy used to train GPT-3 and requires half of the computation flops for inference, while still achieving better overall zero-shot and one-shot performance across 29 NLP tasks.