 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiTTenS: A Dataset for Evaluating Misgendering in Translation
Jan 13, 2024



Misgendering is the act of referring to someone in a way that does not reflect their gender identity. Translation systems, including foundation models capable of translation, can produce errors that result in misgendering harms. To measure the extent of such potential harms when translating into and out of English, we introduce a dataset, MiTTenS, covering 26 languages from a variety of language families and scripts, including several traditionally underpresented in digital resources. The dataset is constructed with handcrafted passages that target known failure patterns, longer synthetically generated passages, and natural passages sourced from multiple domains. We demonstrate the usefulness of the dataset by evaluating both dedicated neural machine translation systems and foundation models, and show that all systems exhibit errors resulting in misgendering harms, even in high resource languages.
Parameter-Efficient Multilingual Summarisation: An Empirical Study
Nov 14, 2023
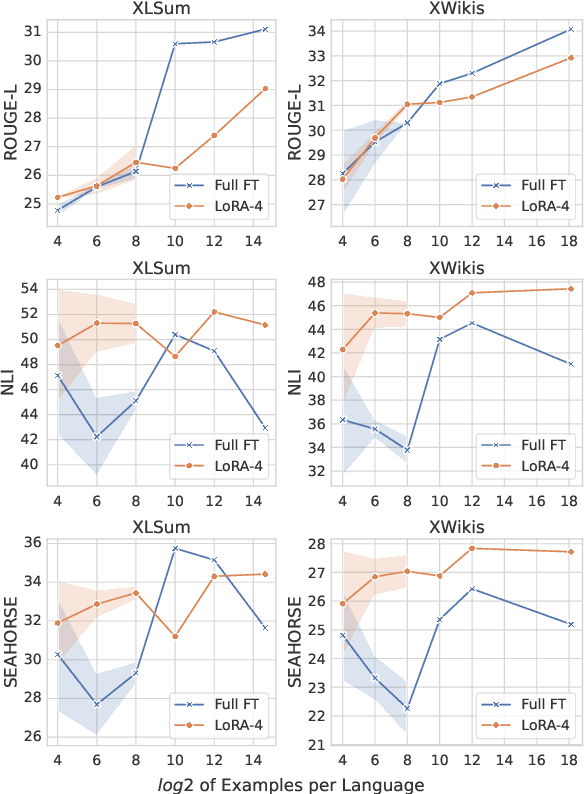
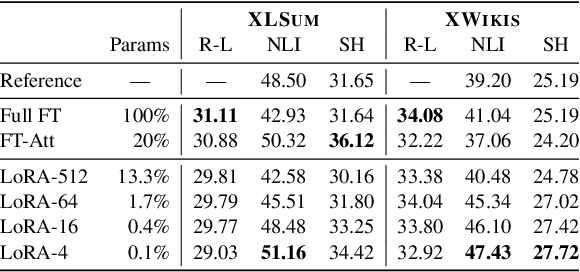

With the increasing prevalence of Large Language Models, traditional full fine-tuning approaches face growing challenges, especially in memory-intensive tasks. This paper investigates the potential of Parameter-Efficient Fine-Tuning, focusing on Low-Rank Adaptation (LoRA), for complex and under-explored multilingual summarisation tasks. We conduct an extensive study across different data availability scenarios, including full-data, low-data, and cross-lingual transfer, leveraging models of different sizes. Our findings reveal that LoRA lags behind full fine-tuning when trained with full data, however, it excels in low-data scenarios and cross-lingual transfer. Interestingly, as models scale up, the performance gap between LoRA and full fine-tuning diminishes. Additionally, we investigate effective strategies for few-shot cross-lingual transfer, finding that continued LoRA tuning achieves the best performance compared to both full fine-tuning and dynamic composition of language-specific LoRA modules.
Dissecting Recall of Factual Associations in Auto-Regressive Language Models
Apr 28, 2023



Transformer-based language models (LMs) are known to capture factual knowledge in their parameters. While previous work looked into where factual associations are stored, only little is known about how they are retrieved internally during inference. We investigate this question through the lens of information flow. Given a subject-relation query, we study how the model aggregates information about the subject and relation to predict the correct attribute. With interventions on attention edges, we first identify two critical points where information propagates to the prediction: one from the relation positions followed by another from the subject positions. Next, by analyzing the information at these points, we unveil a three-step internal mechanism for attribute extraction. First, the representation at the last-subject position goes through an enrichment process, driven by the early MLP sublayers, to encode many subject-related attributes. Second, information from the relation propagates to the prediction. Third, the prediction representation "queries" the enriched subject to extract the attribute. Perhaps surprisingly, this extraction is typically done via attention heads, which often encode subject-attribute mappings in their parameters. Overall, our findings introduce a comprehensive view of how factual associations are stored and extracted internally in LMs, facilitating future research on knowledge localization and editing.
Scaling Vision Transformers to 22 Billion Parameters
Feb 10, 2023



The scaling of Transformers has driven breakthrough capabilities for language models. At present, the largest large language models (LLMs) contain upwards of 100B parameters. Vision Transformers (ViT) have introduced the same architecture to image and video modelling, but these have not yet been successfully scaled to nearly the same degree; the largest dense ViT contains 4B parameters (Chen et al., 2022). We present a recipe for highly efficient and stable training of a 22B-parameter ViT (ViT-22B) and perform a wide variety of experiments on the resulting model. When evaluated on downstream tasks (often with a lightweight linear model on frozen features), ViT-22B demonstrates increasing performance with scale. We further observe other interesting benefits of scale, including an improved tradeoff between fairness and performance, state-of-the-art alignment to human visual perception in terms of shape/texture bias, and improved robustness. ViT-22B demonstrates the potential for "LLM-like" scaling in vision, and provides key steps towards getting there.
Simple Recurrence Improves Masked Language Models
May 23, 2022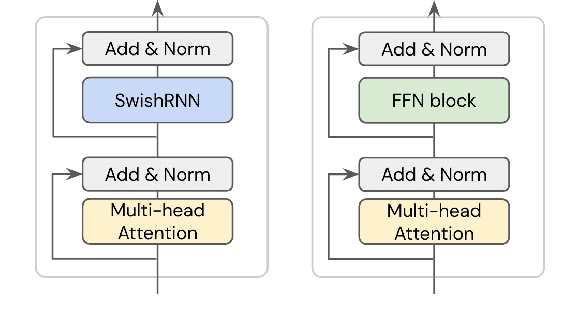

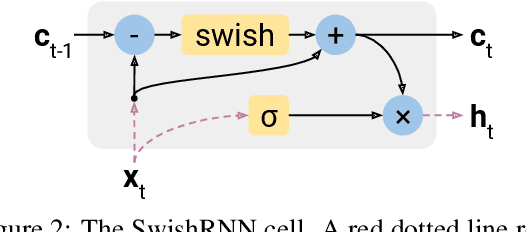

In this work, we explore whether modeling recurrence into the Transformer architecture can both be beneficial and efficient, by building an extremely simple recurrent module into the Transformer. We compare our model to baselines following the training and evaluation recipe of BERT. Our results confirm that recurrence can indeed improve Transformer models by a consistent margin, without requiring low-level performance optimizations, and while keeping the number of parameters constant. For example, our base model achieves an absolute improvement of 2.1 points averaged across 10 tasks and also demonstrates increased stability in fine-tuning over a range of learning rates.
Scaling Up Models and Data with $\texttt{t5x}$ and $\texttt{seqio}$
Mar 31, 2022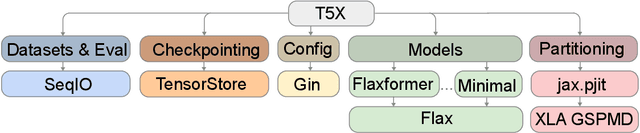
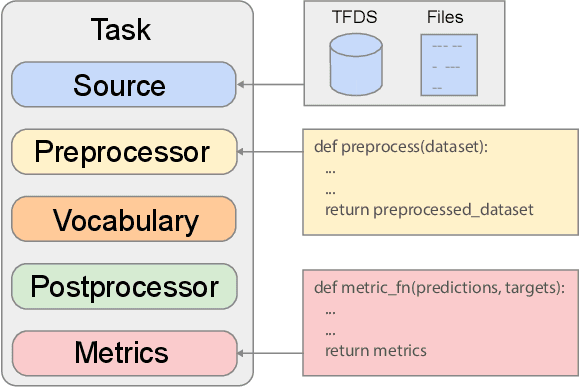
Recent neural network-based language models have benefited greatly from scaling up the size of training datasets and the number of parameters in the models themselves. Scaling can be complicated due to various factors including the need to distribute computation on supercomputer clusters (e.g., TPUs), prevent bottlenecks when infeeding data, and ensure reproducible results. In this work, we present two software libraries that ease these issues: $\texttt{t5x}$ simplifies the process of building and training large language models at scale while maintaining ease of use, and $\texttt{seqio}$ provides a task-based API for simple creation of fast and reproducible training data and evaluation pipelines. These open-source libraries have been used to train models with hundreds of billions of parameters on datasets with multiple terabytes of training data. Along with the libraries, we release configurations and instructions for T5-like encoder-decoder models as well as GPT-like decoder-only architectures. $\texttt{t5x}$ and $\texttt{seqio}$ are open source and available at https://github.com/google-research/t5x and https://github.com/google/seqio, respectively.
Diagnosing AI Explanation Methods with Folk Concepts of Behavior
Jan 27, 2022
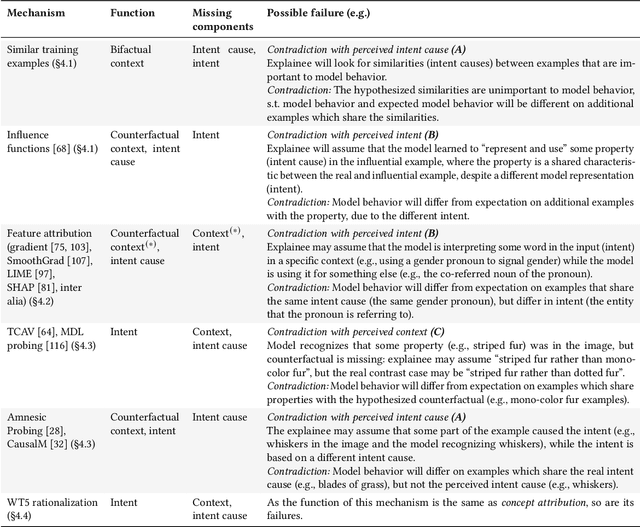
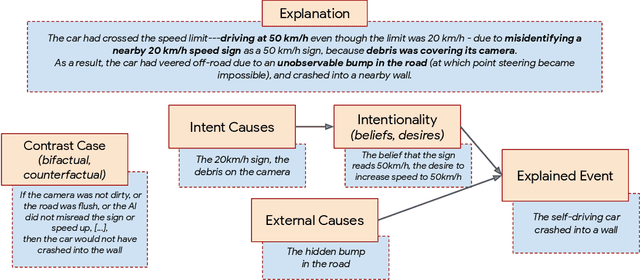

When explaining AI behavior to humans, how is the communicated information being comprehended by the human explainee, and does it match what the explanation attempted to communicate? When can we say that an explanation is explaining something? We aim to provide an answer by leveraging theory of mind literature about the folk concepts that humans use to understand behavior. We establish a framework of social attribution by the human explainee, which describes the function of explanations: the concrete information that humans comprehend from them. Specifically, effective explanations should be coherent (communicate information which generalizes to other contrast cases), complete (communicating an explicit contrast case, objective causes, and subjective causes), and interactive (surfacing and resolving contradictions to the generalization property through iterations). We demonstrate that many XAI mechanisms can be mapped to folk concepts of behavior. This allows us to uncover their modes of failure that prevent current methods from explaining effectively, and what is necessary to enable coherent explanations.
"Will You Find These Shortcuts?" A Protocol for Evaluating the Faithfulness of Input Salience Methods for Text Classification
Nov 14, 2021
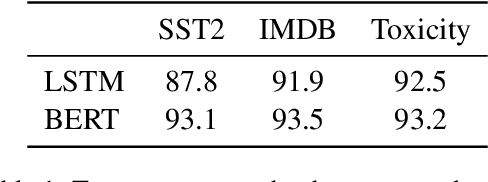


Feature attribution a.k.a. input salience methods which assign an importance score to a feature are abundant but may produce surprisingly different results for the same model on the same input. While differences are expected if disparate definitions of importance are assumed, most methods claim to provide faithful attributions and point at the features most relevant for a model's prediction. Existing work on faithfulness evaluation is not conclusive and does not provide a clear answer as to how different methods are to be compared. Focusing on text classification and the model debugging scenario, our main contribution is a protocol for faithfulness evaluation that makes use of partially synthetic data to obtain ground truth for feature importance ranking. Following the protocol, we do an in-depth analysis of four standard salience method classes on a range of datasets and shortcuts for BERT and LSTM models and demonstrate that some of the most popular method configurations provide poor results even for simplest shortcuts. We recommend following the protocol for each new task and model combination to find the best method for identifying shortcuts.
Autoregressive Diffusion Models
Oct 05, 2021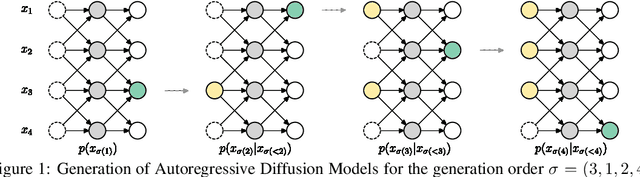

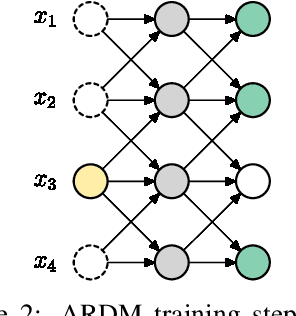

We introduce Autoregressive Diffusion Models (ARDMs), a model class encompassing and generalizing order-agnostic autoregressive models (Uria et al., 2014) and absorbing discrete diffusion (Austin et al., 2021), which we show are special cases of ARDMs under mild assumptions. ARDMs are simple to implement and easy to train. Unlike standard ARMs, they do not require causal masking of model representations, and can be trained using an efficient objective similar to modern probabilistic diffusion models that scales favourably to highly-dimensional data. At test time, ARDMs support parallel generation which can be adapted to fit any given generation budget. We find that ARDMs require significantly fewer steps than discrete diffusion models to attain the same performance. Finally, we apply ARDMs to lossless compression, and show that they are uniquely suited to this task. Contrary to existing approaches based on bits-back coding, ARDMs obtain compelling results not only on complete datasets, but also on compressing single data points. Moreover, this can be done using a modest number of network calls for (de)compression due to the model's adaptable parallel generation.
The MultiBERTs: BERT Reproductions for Robustness Analysis
Jun 30, 2021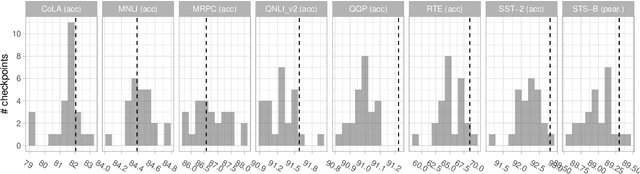
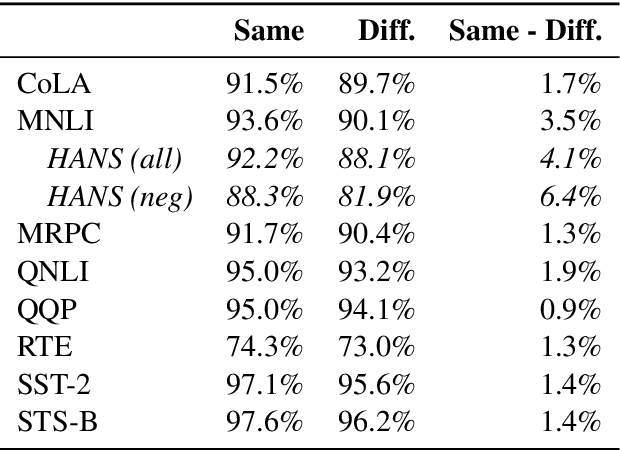
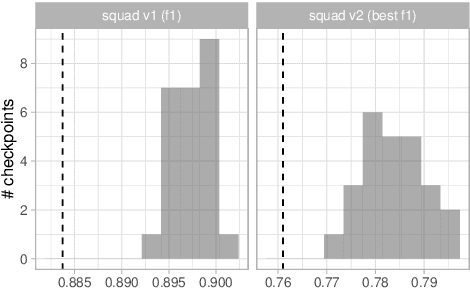
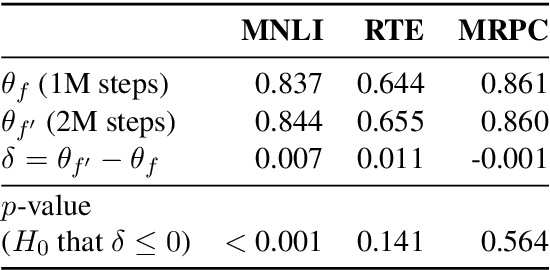
Experiments with pretrained models such as BERT are often based on a single checkpoint. While the conclusions drawn apply to the artifact (i.e., the particular instance of the model), it is not always clear whether they hold for the more general procedure (which includes the model architecture, training data, initialization scheme, and loss function). Recent work has shown that re-running pretraining can lead to substantially different conclusions about performance, suggesting that alternative evaluations are needed to make principled statements about procedures. To address this question, we introduce MultiBERTs: a set of 25 BERT-base checkpoints, trained with similar hyper-parameters as the original BERT model but differing in random initialization and data shuffling. The aim is to enable researchers to draw robust and statistically justified conclusions about pretraining procedures. The full release includes 25 fully trained checkpoints, as well as statistical guidelines and a code library implementing our recommended hypothesis testing methods. Finally, for five of these models we release a set of 28 intermediate checkpoints in order to support research on learning dynamics.