 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEAHORSE: A Multilingual, Multifaceted Dataset for Summarization Evaluation
May 22, 2023
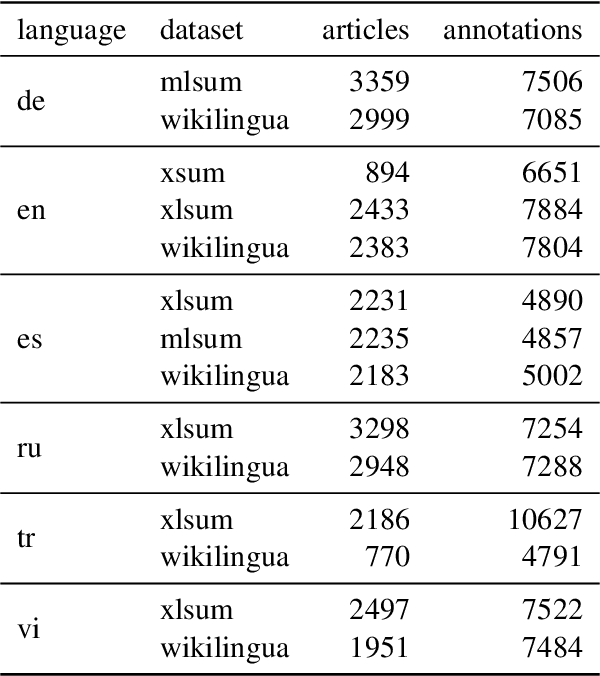
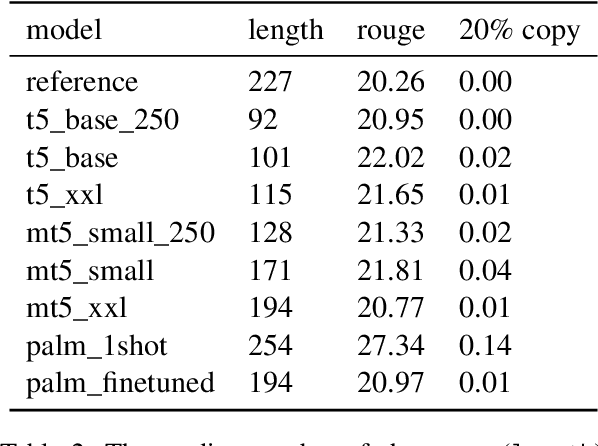
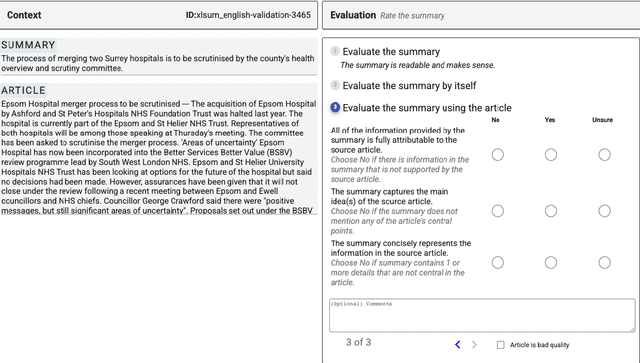
Reliable automatic evaluation of summarization systems is challenging due to the multifaceted and subjective nature of the task. This is especially the case for languages other than English, where human evaluations are scarce. In this work, we introduce SEAHORSE, a dataset for multilingual, multifaceted summarization evaluation. SEAHORSE consists of 96K summaries with human ratings along 6 quality dimensions: comprehensibility, repetition, grammar, attribution, main ideas, and conciseness, covering 6 languages, 9 systems and 4 datasets. As a result of its size and scope, SEAHORSE can serve both as a benchmark to evaluate learnt metrics, as well as a large-scale resource for training such metrics. We show that metrics trained with SEAHORSE achieve strong performance on the out-of-domain meta-evaluation benchmarks TRUE (Honovich et al., 2022) and mFACE (Aharoni et al., 2022). We make SEAHORSE publicly available for future research on multilingual and multifaceted summarization evaluation.
Extrapolative Controlled Sequence Generation via Iterative Refinement
Mar 08, 2023



We study the problem of extrapolative controlled generation, i.e., generating sequences with attribute values beyond the range seen in training. This task is of significant importance in automated design, especially drug discovery, where the goal is to design novel proteins that are \textit{better} (e.g., more stable) than existing sequences. Thus, by definition, the target sequences and their attribute values are out of the training distribution, posing challenges to existing methods that aim to directly generate the target sequence. Instead, in this work, we propose Iterative Controlled Extrapolation (ICE) which iteratively makes local edits to a sequence to enable extrapolation. We train the model on synthetically generated sequence pairs that demonstrate small improvement in the attribute value. Results on one natural language task (sentiment analysis) and two protein engineering tasks (ACE2 stability and AAV fitness) show that ICE considerably outperforms state-of-the-art approaches despite its simplicity. Our code and models are available at: https://github.com/vishakhpk/iter-extrapolation.
Reward Gaming in Conditional Text Generation
Nov 16, 2022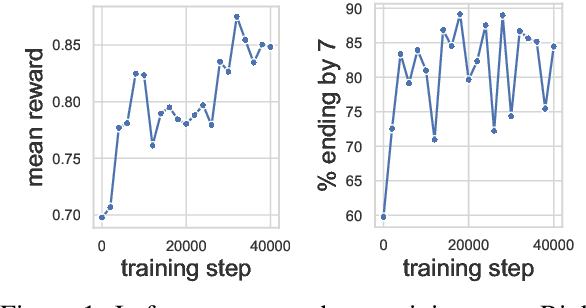

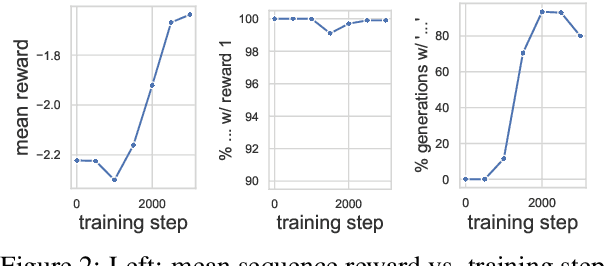
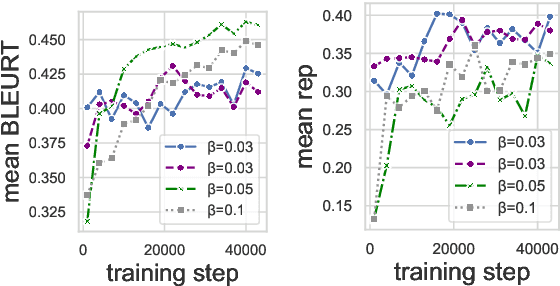
To align conditional text generation model outputs with desired behaviors, there has been an increasing focus on training the model using reinforcement learning (RL) with reward functions learned from human annotations. Under this framework, we identify three common cases where high rewards are incorrectly assigned to undesirable patterns: noise-induced spurious correlation, naturally occurring spurious correlation, and covariate shift. We show that even though learned metrics achieve high performance on the distribution of the data used to train the reward function, the undesirable patterns may be amplified during RL training of the text generation model. While there has been discussion about reward gaming in the RL or safety community, in this short discussion piece, we would like to highlight reward gaming in the NLG community using concrete conditional text generation examples and discuss potential fixes and areas for future work.
SQuId: Measuring Speech Naturalness in Many Languages
Oct 12, 2022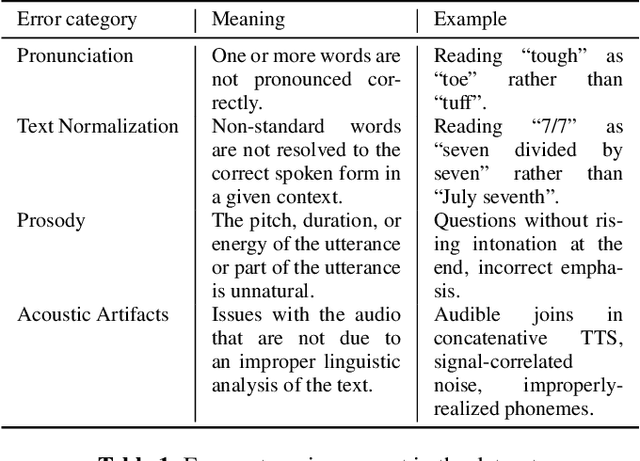
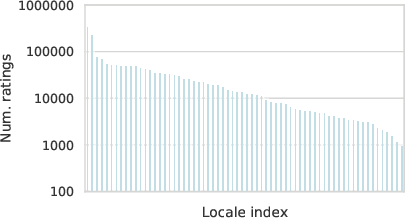

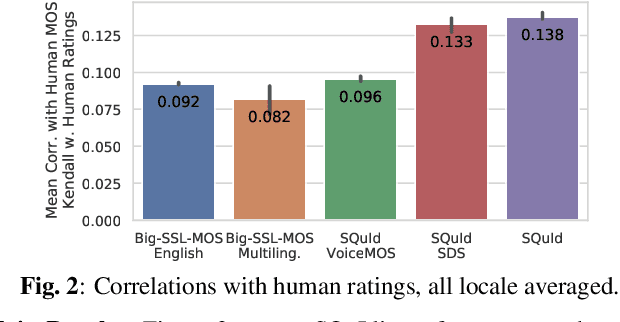
Much of text-to-speech research relies on human evaluation, which incurs heavy costs and slows down the development process. The problem is particularly acute in heavily multilingual applications, where recruiting and polling judges can take weeks. We introduce SQuId (Speech Quality Identification), a multilingual naturalness prediction model trained on over a million ratings and tested in 65 locales-the largest effort of this type to date. The main insight is that training one model on many locales consistently outperforms mono-locale baselines. We present our task, the model, and show that it outperforms a competitive baseline based on w2v-BERT and VoiceMOS by 50.0%. We then demonstrate the effectiveness of cross-locale transfer during fine-tuning and highlight its effect on zero-shot locales, i.e., locales for which there is no fine-tuning data. Through a series of analyses, we highlight the role of non-linguistic effects such as sound artifacts in cross-locale transfer. Finally, we present the effect of our design decision, e.g., model size, pre-training diversity, and language rebalancing with several ablation experiments.
Simple Recurrence Improves Masked Language Models
May 23, 2022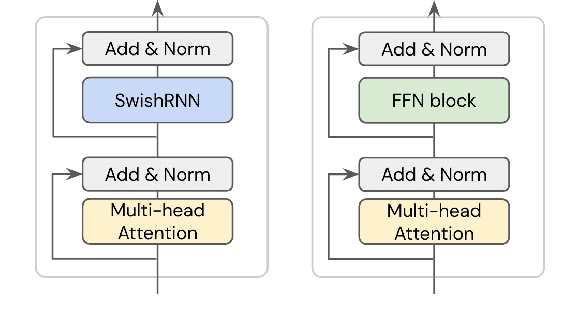

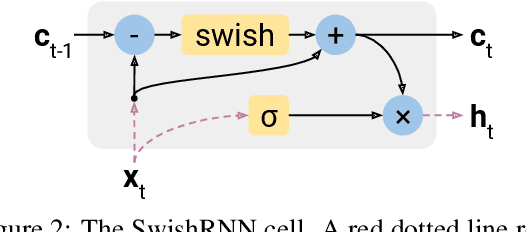

In this work, we explore whether modeling recurrence into the Transformer architecture can both be beneficial and efficient, by building an extremely simple recurrent module into the Transformer. We compare our model to baselines following the training and evaluation recipe of BERT. Our results confirm that recurrence can indeed improve Transformer models by a consistent margin, without requiring low-level performance optimizations, and while keeping the number of parameters constant. For example, our base model achieves an absolute improvement of 2.1 points averaged across 10 tasks and also demonstrates increased stability in fine-tuning over a range of learning rates.
Learning Compact Metrics for MT
Oct 12, 2021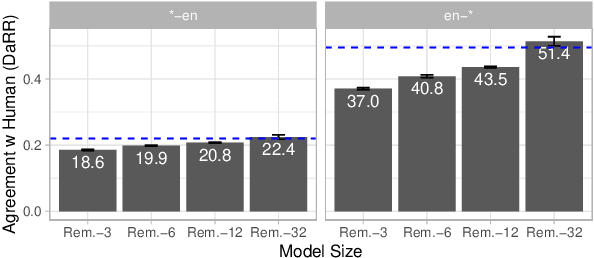
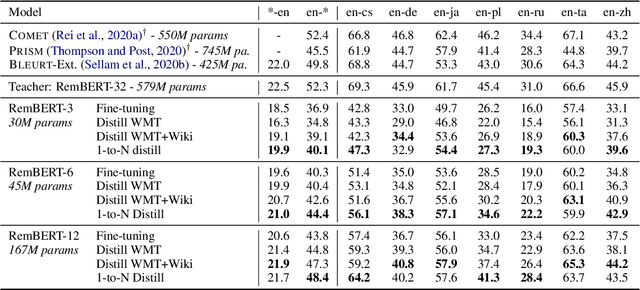
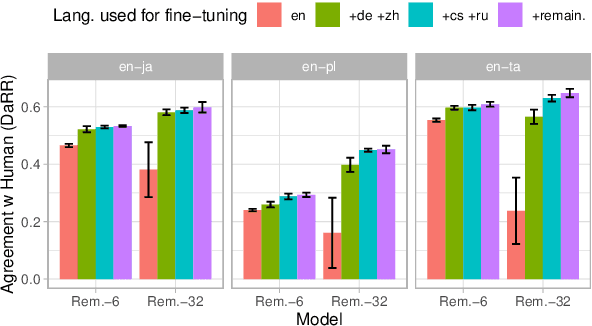
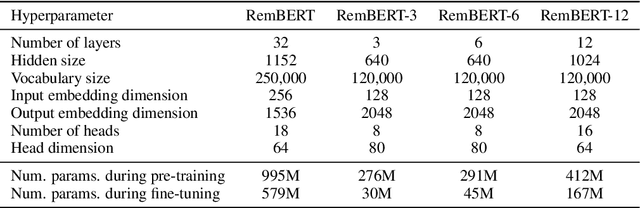
Recent developments in machine translation and multilingual text generation have led researchers to adopt trained metrics such as COMET or BLEURT, which treat evaluation as a regression problem and use representations from multilingual pre-trained models such as XLM-RoBERTa or mBERT. Yet studies on related tasks suggest that these models are most efficient when they are large, which is costly and impractical for evaluation. We investigate the trade-off between multilinguality and model capacity with RemBERT, a state-of-the-art multilingual language model, using data from the WMT Metrics Shared Task. We present a series of experiments which show that model size is indeed a bottleneck for cross-lingual transfer, then demonstrate how distillation can help addressing this bottleneck, by leveraging synthetic data generation and transferring knowledge from one teacher to multiple students trained on related languages. Our method yields up to 10.5% improvement over vanilla fine-tuning and reaches 92.6% of RemBERT's performance using only a third of its parameters.
Shatter: An Efficient Transformer Encoder with Single-Headed Self-Attention and Relative Sequence Partitioning
Aug 30, 2021


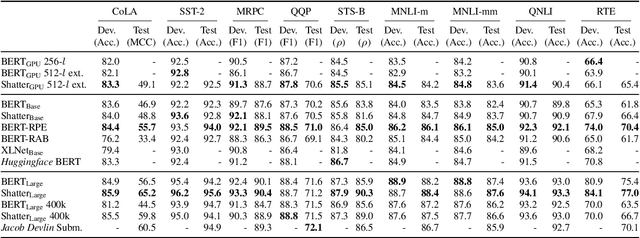
The highly popular Transformer architecture, based on self-attention, is the foundation of large pretrained models such as BERT, that have become an enduring paradigm in NLP. While powerful, the computational resources and time required to pretrain such models can be prohibitive. In this work, we present an alternative self-attention architecture, Shatter, that more efficiently encodes sequence information by softly partitioning the space of relative positions and applying different value matrices to different parts of the sequence. This mechanism further allows us to simplify the multi-headed attention in Transformer to single-headed. We conduct extensive experiments showing that Shatter achieves better performance than BERT, with pretraining being faster per step (15% on TPU), converging in fewer steps, and offering considerable memory savings (>50%). Put together, Shatter can be pretrained on 8 V100 GPUs in 7 days, and match the performance of BERT_Base -- making the cost of pretraining much more affordable.
Towards Continual Learning for Multilingual Machine Translation via Vocabulary Substitution
Mar 11, 2021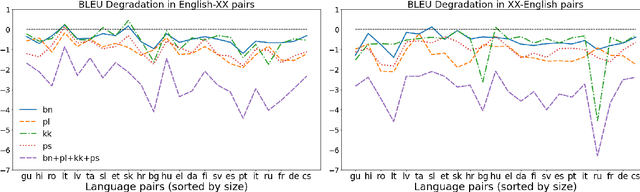



We propose a straightforward vocabulary adaptation scheme to extend the language capacity of multilingual machine translation models, paving the way towards efficient continual learning for multilingual machine translation. Our approach is suitable for large-scale datasets, applies to distant languages with unseen scripts, incurs only minor degradation on the translation performance for the original language pairs and provides competitive performance even in the case where we only possess monolingual data for the new languages.
Learning to Evaluate Translation Beyond English: BLEURT Submissions to the WMT Metrics 2020 Shared Task
Oct 19, 2020
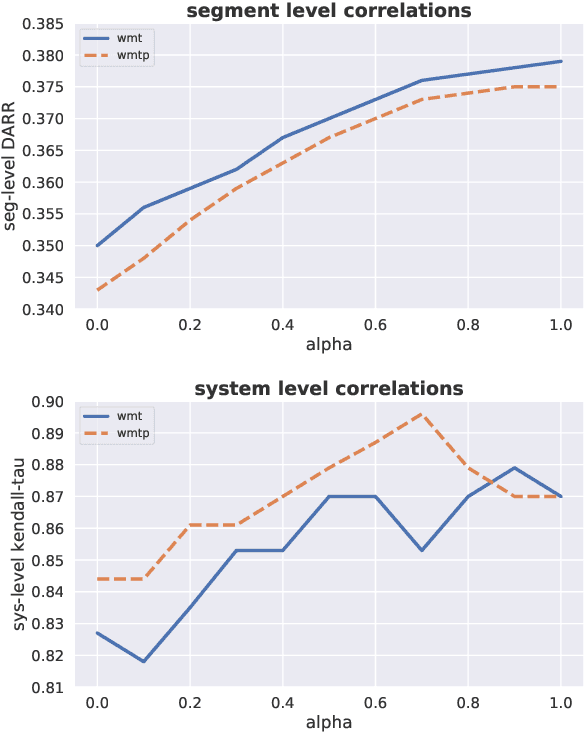

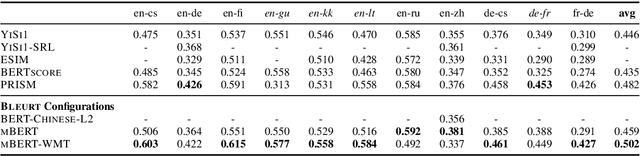
The quality of machine translation systems has dramatically improved over the last decade, and as a result, evaluation has become an increasingly challenging problem. This paper describes our contribution to the WMT 2020 Metrics Shared Task, the main benchmark for automatic evaluation of translation. We make several submissions based on BLEURT, a previously published metric based on transfer learning. We extend the metric beyond English and evaluate it on 14 language pairs for which fine-tuning data is available, as well as 4 "zero-shot" language pairs, for which we have no labelled examples. Additionally, we focus on English to German and demonstrate how to combine BLEURT's predictions with those of YiSi and use alternative reference translations to enhance the performance. Empirical results show that the models achieve competitive results on the WMT Metrics 2019 Shared Task, indicating their promise for the 2020 edition.
Harnessing Multilinguality in Unsupervised Machine Translation for Rare Languages
Sep 23, 2020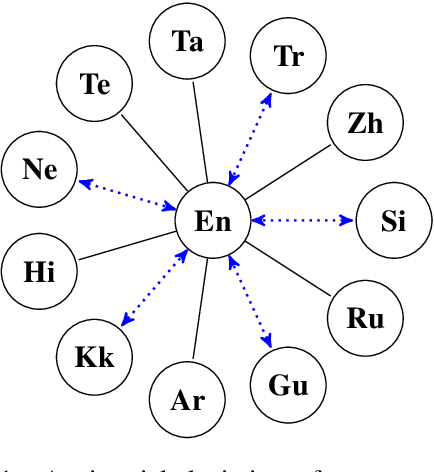



Unsupervised translation has reached impressive performance on resource-rich language pairs such as English-French and English-German. However, early studies have shown that in more realistic settings involving low-resource, rare languages, unsupervised translation performs poorly, achieving less than 3.0 BLEU. In this work, we show that multilinguality is critical to making unsupervised systems practical for low-resource settings. In particular, we present a single model for 5 low-resource languages (Gujarati, Kazakh, Nepali, Sinhala, and Turkish) to and from English directions, which leverages monolingual and auxiliary parallel data from other high-resource language pairs via a three-stage training scheme. We outperform all current state-of-the-art unsupervised baselines for these languages, achieving gains of up to 14.4 BLEU. Additionally, we outperform a large collection of supervised WMT submissions for various language pairs as well as match the performance of the current state-of-the-art supervised model for Nepali-English. We conduct a series of ablation studies to establish the robustness of our model under different degrees of data quality, as well as to analyze the factors which led to the superior performance of the proposed approach over traditional unsupervised models.