 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSQuId: Measuring Speech Naturalness in Many Languages
Paper and Code
Oct 12, 2022

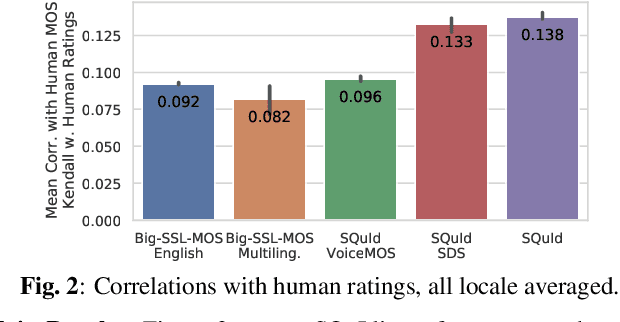
Much of text-to-speech research relies on human evaluation, which incurs heavy costs and slows down the development process. The problem is particularly acute in heavily multilingual applications, where recruiting and polling judges can take weeks. We introduce SQuId (Speech Quality Identification), a multilingual naturalness prediction model trained on over a million ratings and tested in 65 locales-the largest effort of this type to date. The main insight is that training one model on many locales consistently outperforms mono-locale baselines. We present our task, the model, and show that it outperforms a competitive baseline based on w2v-BERT and VoiceMOS by 50.0%. We then demonstrate the effectiveness of cross-locale transfer during fine-tuning and highlight its effect on zero-shot locales, i.e., locales for which there is no fine-tuning data. Through a series of analyses, we highlight the role of non-linguistic effects such as sound artifacts in cross-locale transfer. Finally, we present the effect of our design decision, e.g., model size, pre-training diversity, and language rebalancing with several ablation experiments.