Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple Recurrence Improves Masked Language Models
Paper and Code
May 23, 2022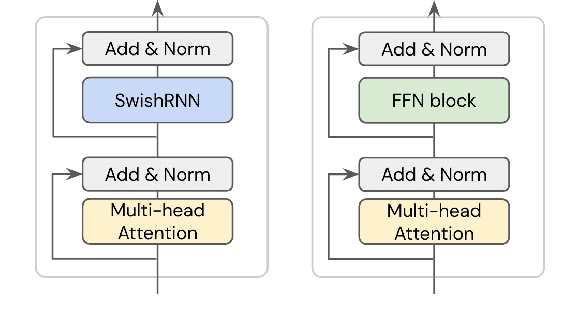

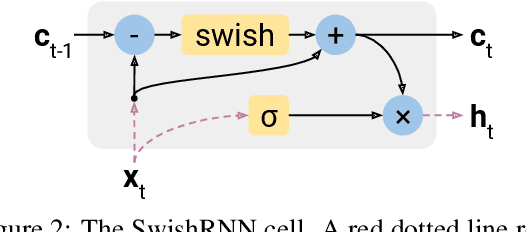

In this work, we explore whether modeling recurrence into the Transformer architecture can both be beneficial and efficient, by building an extremely simple recurrent module into the Transformer. We compare our model to baselines following the training and evaluation recipe of BERT. Our results confirm that recurrence can indeed improve Transformer models by a consistent margin, without requiring low-level performance optimizations, and while keeping the number of parameters constant. For example, our base model achieves an absolute improvement of 2.1 points averaged across 10 tasks and also demonstrates increased stability in fine-tuning over a range of learning rates.
View paper on