 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter-Efficient Multilingual Summarisation: An Empirical Study
Paper and Code

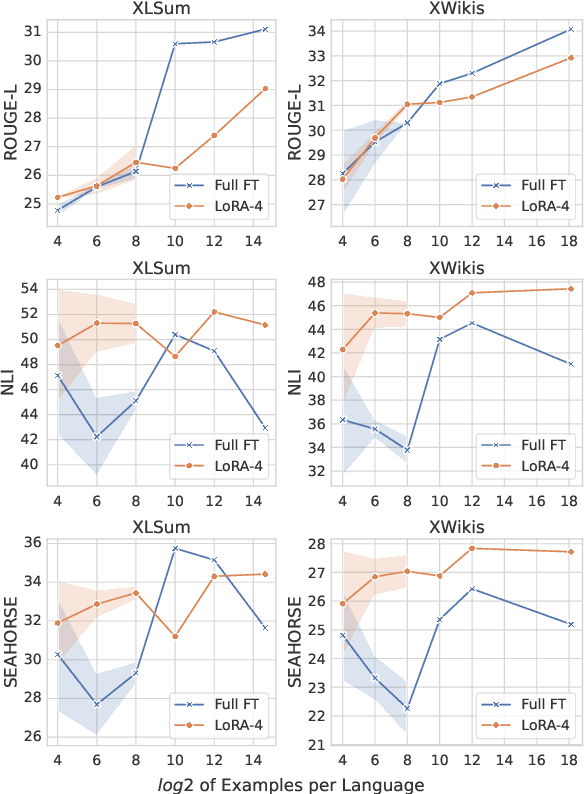
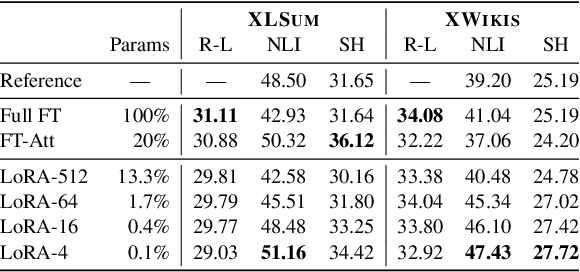

With the increasing prevalence of Large Language Models, traditional full fine-tuning approaches face growing challenges, especially in memory-intensive tasks. This paper investigates the potential of Parameter-Efficient Fine-Tuning, focusing on Low-Rank Adaptation (LoRA), for complex and under-explored multilingual summarisation tasks. We conduct an extensive study across different data availability scenarios, including full-data, low-data, and cross-lingual transfer, leveraging models of different sizes. Our findings reveal that LoRA lags behind full fine-tuning when trained with full data, however, it excels in low-data scenarios and cross-lingual transfer. Interestingly, as models scale up, the performance gap between LoRA and full fine-tuning diminishes. Additionally, we investigate effective strategies for few-shot cross-lingual transfer, finding that continued LoRA tuning achieves the best performance compared to both full fine-tuning and dynamic composition of language-specific LoRA modules.