 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Text Classification Data and Models Using Aggregated Input Salience
Nov 11, 2022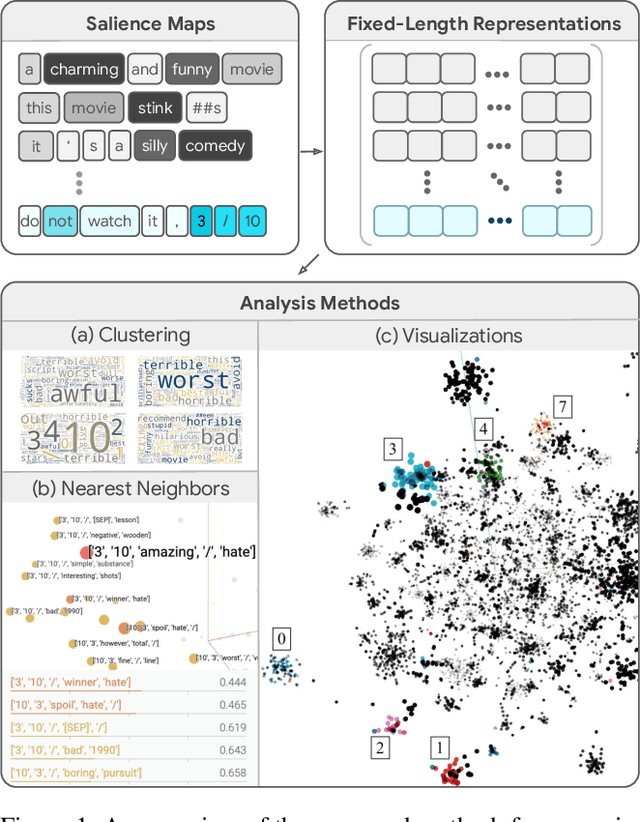
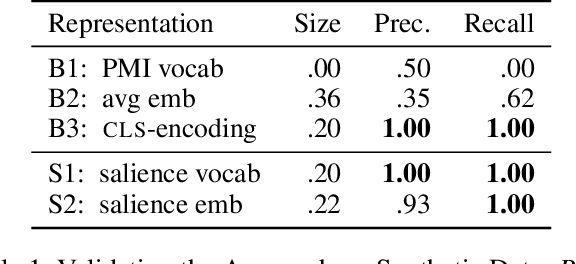

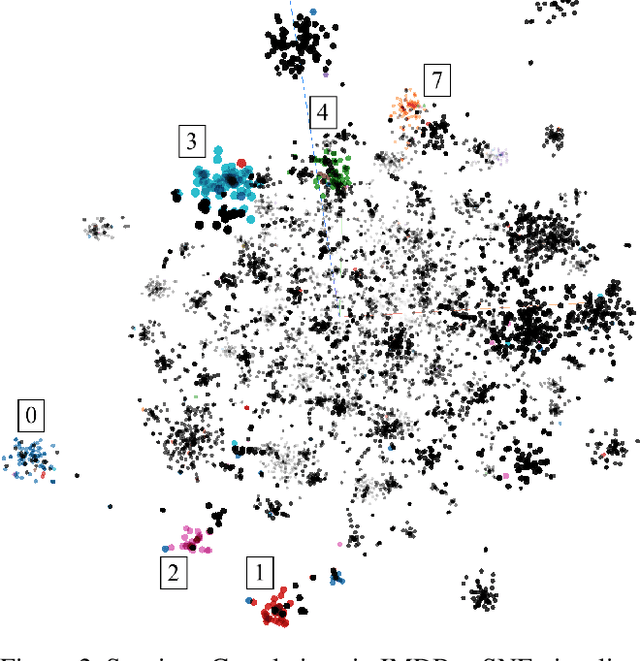
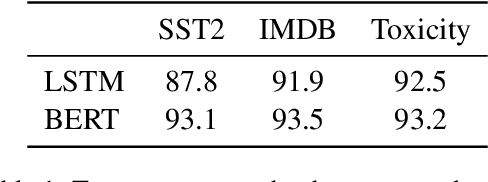
Realizing when a model is right for a wrong reason is not trivial and requires a significant effort by model developers. In some cases, an input salience method, which highlights the most important parts of the input, may reveal problematic reasoning. But scrutinizing highlights over many data instances is tedious and often infeasible. Furthermore, analyzing examples in isolation does not reveal general patterns in the data or in the model's behavior. In this paper we aim to address these issues and go from understanding single examples to understanding entire datasets and models. The methodology we propose is based on aggregated salience maps. Using this methodology we address multiple distinct but common model developer needs by showing how problematic data and model behavior can be identified -- a necessary first step for improving the model.
"Will You Find These Shortcuts?" A Protocol for Evaluating the Faithfulness of Input Salience Methods for Text Classification
Nov 14, 2021


Feature attribution a.k.a. input salience methods which assign an importance score to a feature are abundant but may produce surprisingly different results for the same model on the same input. While differences are expected if disparate definitions of importance are assumed, most methods claim to provide faithful attributions and point at the features most relevant for a model's prediction. Existing work on faithfulness evaluation is not conclusive and does not provide a clear answer as to how different methods are to be compared. Focusing on text classification and the model debugging scenario, our main contribution is a protocol for faithfulness evaluation that makes use of partially synthetic data to obtain ground truth for feature importance ranking. Following the protocol, we do an in-depth analysis of four standard salience method classes on a range of datasets and shortcuts for BERT and LSTM models and demonstrate that some of the most popular method configurations provide poor results even for simplest shortcuts. We recommend following the protocol for each new task and model combination to find the best method for identifying shortcuts.
Don't Search for a Search Method -- Simple Heuristics Suffice for Adversarial Text Attacks
Oct 04, 2021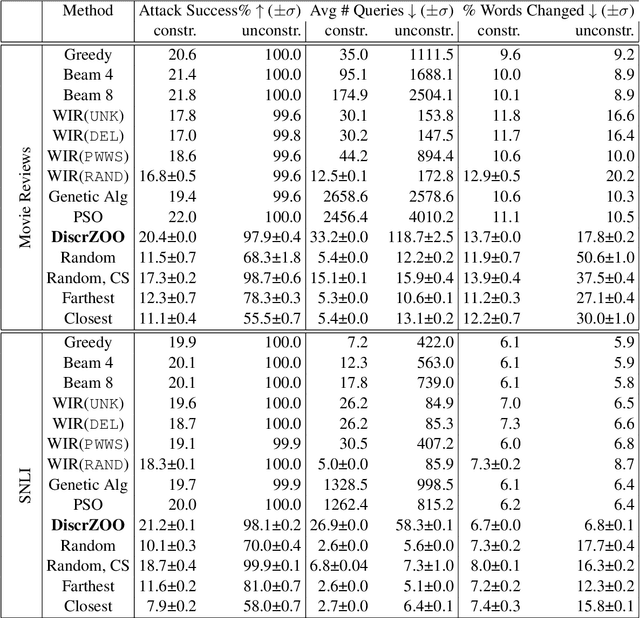
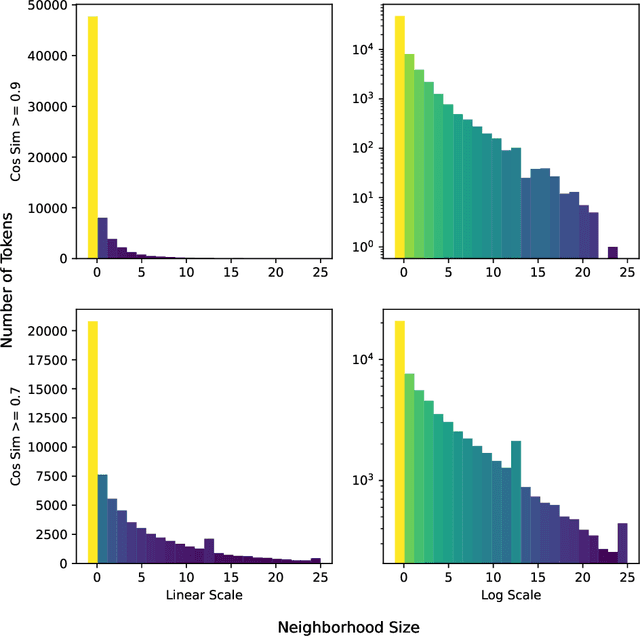
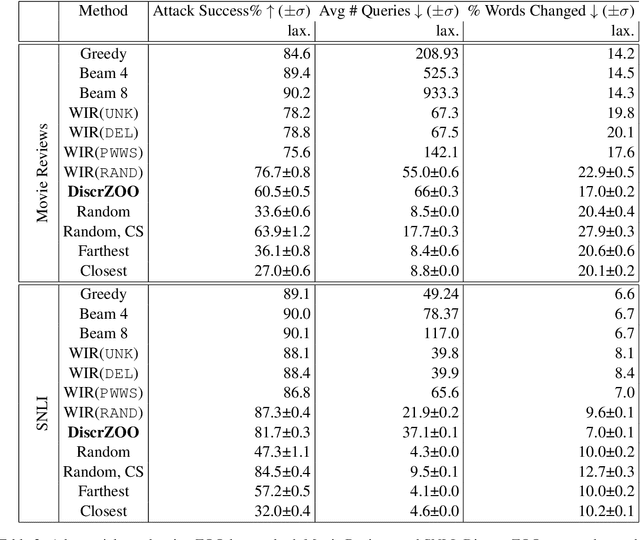
Recently more attention has been given to adversarial attacks on neural networks for natural language processing (NLP). A central research topic has been the investigation of search algorithms and search constraints, accompanied by benchmark algorithms and tasks. We implement an algorithm inspired by zeroth order optimization-based attacks and compare with the benchmark results in the TextAttack framework. Surprisingly, we find that optimization-based methods do not yield any improvement in a constrained setup and slightly benefit from approximate gradient information only in unconstrained setups where search spaces are larger. In contrast, simple heuristics exploiting nearest neighbors without querying the target function yield substantial success rates in constrained setups, and nearly full success rate in unconstrained setups, at an order of magnitude fewer queries. We conclude from these results that current TextAttack benchmark tasks are too easy and constraints are too strict, preventing meaningful research on black-box adversarial text attacks.
We Need to Talk About Random Splits
May 01, 2020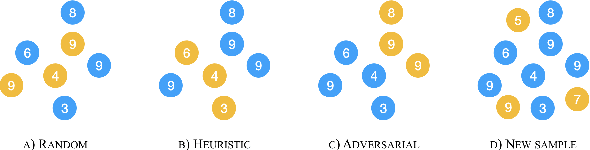

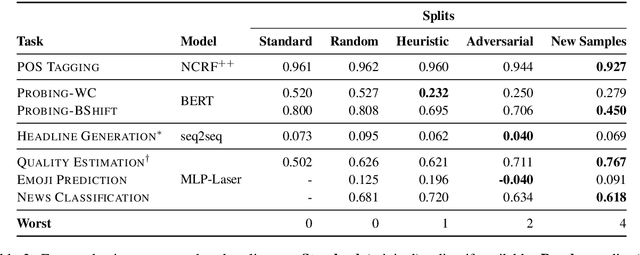
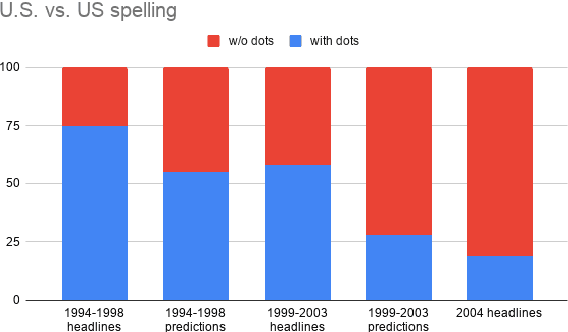
Gorman and Bedrick (2019) recently argued for using random splits rather than standard splits in NLP experiments. We argue that random splits, like standard splits, lead to overly optimistic performance estimates. In some cases, even worst-case splits under-estimate the error observed on new samples of in-domain data, i.e., the data that models should minimally generalize to at test time. This proves wrong the common conjecture that bias can be corrected for by re-weighting data (Shimodaira, 2000; Shah et al., 2020). Instead of using multiple random splits, we propose that future benchmarks instead include multiple, independent test sets.
Ultradense Word Embeddings by Orthogonal Transformation
May 08, 2016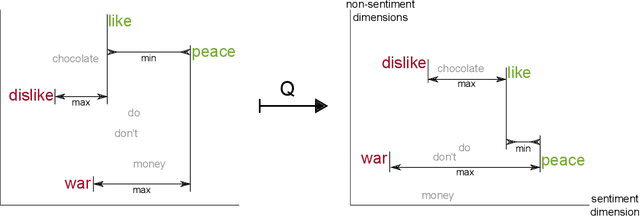
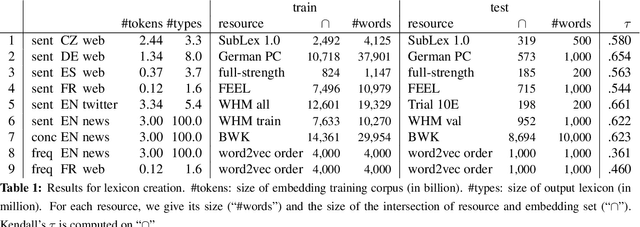

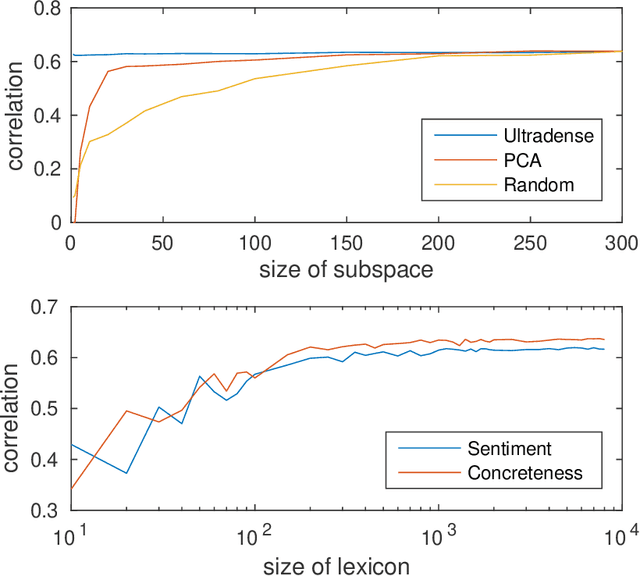
Embeddings are generic representations that are useful for many NLP tasks. In this paper, we introduce DENSIFIER, a method that learns an orthogonal transformation of the embedding space that focuses the information relevant for a task in an ultradense subspace of a dimensionality that is smaller by a factor of 100 than the original space. We show that ultradense embeddings generated by DENSIFIER reach state of the art on a lexicon creation task in which words are annotated with three types of lexical information - sentiment, concreteness and frequency. On the SemEval2015 10B sentiment analysis task we show that no information is lost when the ultradense subspace is used, but training is an order of magnitude more efficient due to the compactness of the ultradense space.
Attention-Based Convolutional Neural Network for Machine Comprehension
Feb 13, 2016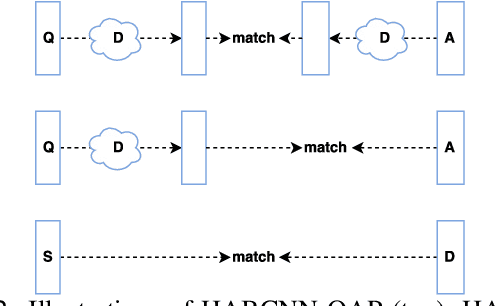
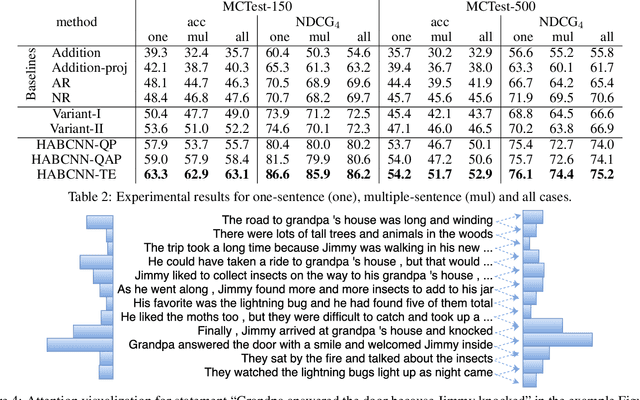
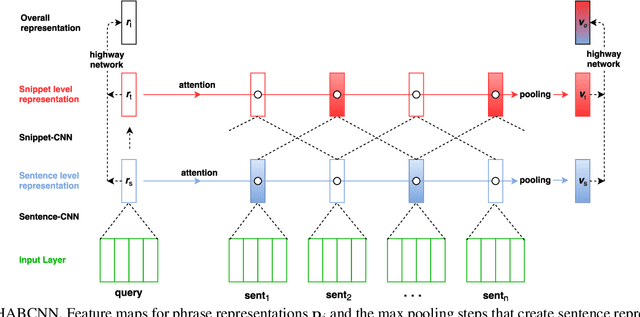
Understanding open-domain text is one of the primary challenges in natural language processing (NLP). Machine comprehension benchmarks evaluate the system's ability to understand text based on the text content only. In this work, we investigate machine comprehension on MCTest, a question answering (QA) benchmark. Prior work is mainly based on feature engineering approaches. We come up with a neural network framework, named hierarchical attention-based convolutional neural network (HABCNN), to address this task without any manually designed features. Specifically, we explore HABCNN for this task by two routes, one is through traditional joint modeling of passage, question and answer, one is through textual entailment. HABCNN employs an attention mechanism to detect key phrases, key sentences and key snippets that are relevant to answering the question. Experiments show that HABCNN outperforms prior deep learning approaches by a big margin.