Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWe Need to Talk About Random Splits
Paper and Code

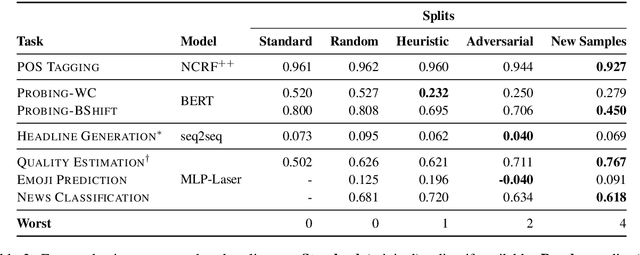
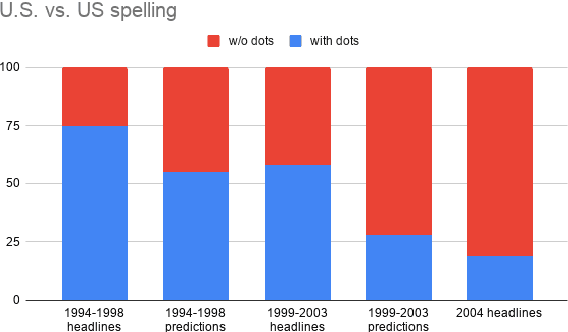
Gorman and Bedrick (2019) recently argued for using random splits rather than standard splits in NLP experiments. We argue that random splits, like standard splits, lead to overly optimistic performance estimates. In some cases, even worst-case splits under-estimate the error observed on new samples of in-domain data, i.e., the data that models should minimally generalize to at test time. This proves wrong the common conjecture that bias can be corrected for by re-weighting data (Shimodaira, 2000; Shah et al., 2020). Instead of using multiple random splits, we propose that future benchmarks instead include multiple, independent test sets.
View paper on