 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePost-edits Are Preferences Too
Oct 03, 2024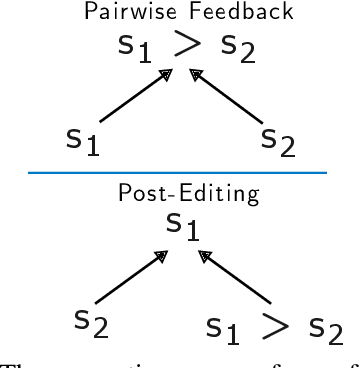
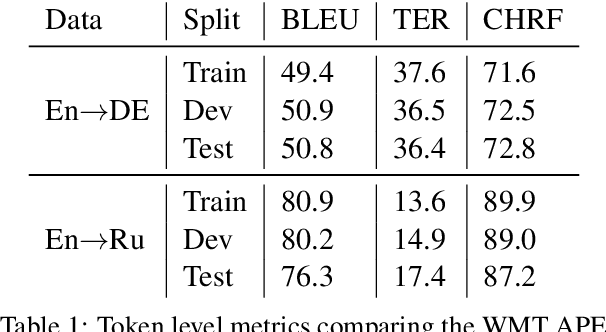
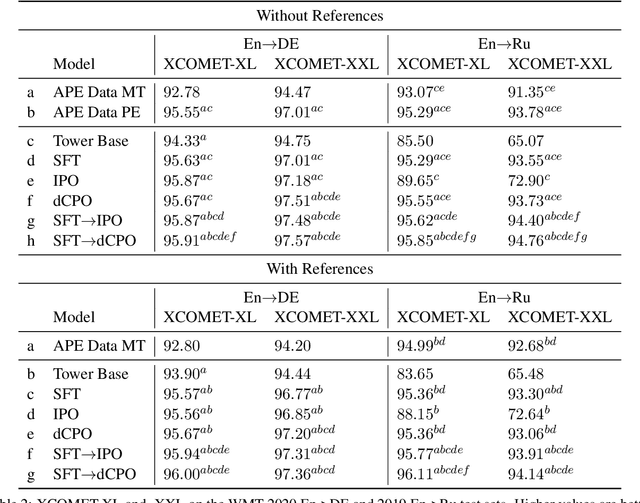
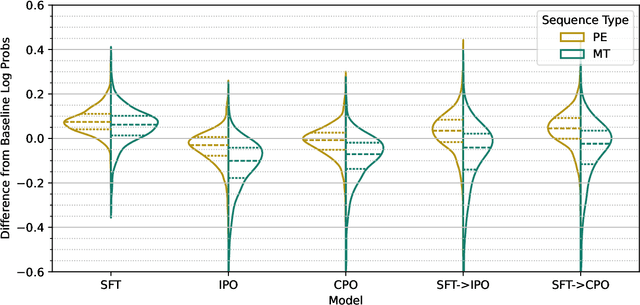
Preference Optimization (PO) techniques are currently one of the state of the art techniques for fine-tuning large language models (LLMs) on pairwise preference feedback from human annotators. However, in machine translation, this sort of feedback can be difficult to solicit. Additionally, Kreutzer et al. (2018) have shown that, for machine translation, pairwise preferences are less reliable than other forms of human feedback, such as 5-point ratings. We examine post-edits to see if they can be a source of reliable human preferences by construction. In PO, a human annotator is shown sequences $s_1$ and $s_2$ and asked for a preference judgment, %$s_1 > s_2$; while for post-editing, editors \emph{create} $s_1$ and know that it should be better than $s_2$. We attempt to use these implicit preferences for PO and show that it helps the model move towards post-edit-like hypotheses and away from machine translation-like hypotheses. Furthermore, we show that best results are obtained by pre-training the model with supervised fine-tuning (SFT) on post-edits in order to promote post-edit-like hypotheses to the top output ranks.
Prompting Large Language Models with Human Error Markings for Self-Correcting Machine Translation
Jun 04, 2024


While large language models (LLMs) pre-trained on massive amounts of unpaired language data have reached the state-of-the-art in machine translation (MT) of general domain texts, post-editing (PE) is still required to correct errors and to enhance term translation quality in specialized domains. In this paper we present a pilot study of enhancing translation memories (TM) produced by PE (source segments, machine translations, and reference translations, henceforth called PE-TM) for the needs of correct and consistent term translation in technical domains. We investigate a light-weight two-step scenario where, at inference time, a human translator marks errors in the first translation step, and in a second step a few similar examples are extracted from the PE-TM to prompt an LLM. Our experiment shows that the additional effort of augmenting translations with human error markings guides the LLM to focus on a correction of the marked errors, yielding consistent improvements over automatic PE (APE) and MT from scratch.
Enhancing Supervised Learning with Contrastive Markings in Neural Machine Translation Training
Jul 17, 2023Supervised learning in Neural Machine Translation (NMT) typically follows a teacher forcing paradigm where reference tokens constitute the conditioning context in the model's prediction, instead of its own previous predictions. In order to alleviate this lack of exploration in the space of translations, we present a simple extension of standard maximum likelihood estimation by a contrastive marking objective. The additional training signals are extracted automatically from reference translations by comparing the system hypothesis against the reference, and used for up/down-weighting correct/incorrect tokens. The proposed new training procedure requires one additional translation pass over the training set per epoch, and does not alter the standard inference setup. We show that training with contrastive markings yields improvements on top of supervised learning, and is especially useful when learning from postedits where contrastive markings indicate human error corrections to the original hypotheses. Code is publicly released.
Don't Search for a Search Method -- Simple Heuristics Suffice for Adversarial Text Attacks
Oct 04, 2021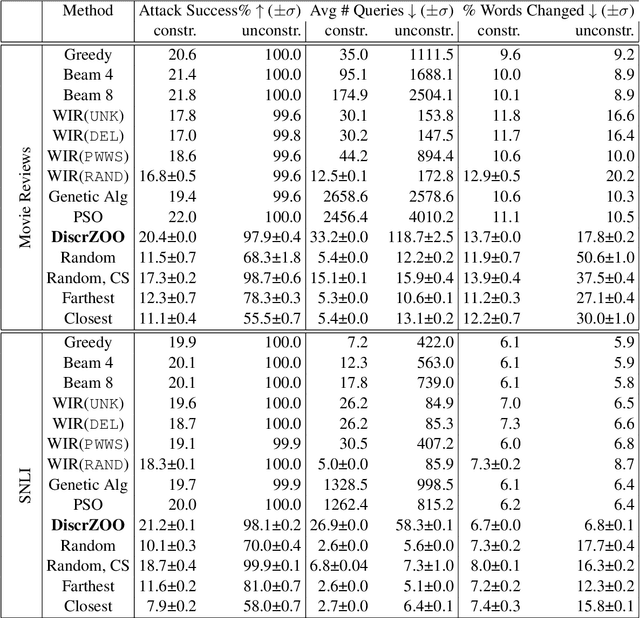
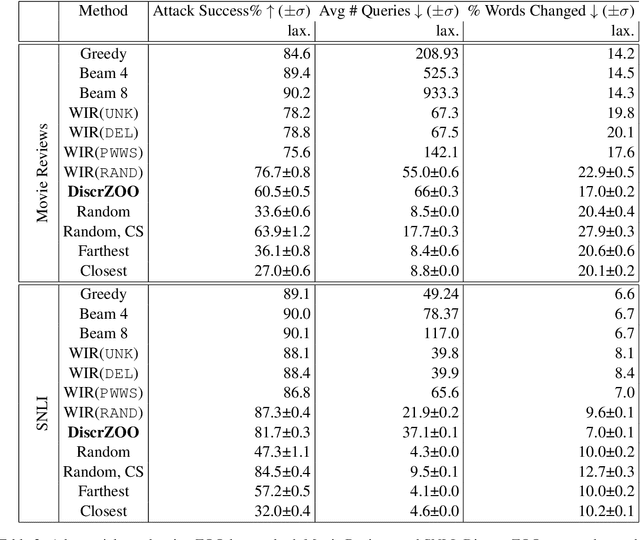
Recently more attention has been given to adversarial attacks on neural networks for natural language processing (NLP). A central research topic has been the investigation of search algorithms and search constraints, accompanied by benchmark algorithms and tasks. We implement an algorithm inspired by zeroth order optimization-based attacks and compare with the benchmark results in the TextAttack framework. Surprisingly, we find that optimization-based methods do not yield any improvement in a constrained setup and slightly benefit from approximate gradient information only in unconstrained setups where search spaces are larger. In contrast, simple heuristics exploiting nearest neighbors without querying the target function yield substantial success rates in constrained setups, and nearly full success rate in unconstrained setups, at an order of magnitude fewer queries. We conclude from these results that current TextAttack benchmark tasks are too easy and constraints are too strict, preventing meaningful research on black-box adversarial text attacks.
Sparse Perturbations for Improved Convergence in Stochastic Zeroth-Order Optimization
Jun 29, 2020



Interest in stochastic zeroth-order (SZO) methods has recently been revived in black-box optimization scenarios such as adversarial black-box attacks to deep neural networks. SZO methods only require the ability to evaluate the objective function at random input points, however, their weakness is the dependency of their convergence speed on the dimensionality of the function to be evaluated. We present a sparse SZO optimization method that reduces this factor to the expected dimensionality of the random perturbation during learning. We give a proof that justifies this reduction for sparse SZO optimization for non-convex functions without making any assumptions on sparsity of objective function or gradient. Furthermore, we present experimental results for neural networks on MNIST and CIFAR that show faster convergence in training loss and test accuracy, and a smaller distance of the gradient approximation to the true gradient in sparse SZO compared to dense SZO.
Correct Me If You Can: Learning from Error Corrections and Markings
Apr 23, 2020



Sequence-to-sequence learning involves a trade-off between signal strength and annotation cost of training data. For example, machine translation data range from costly expert-generated translations that enable supervised learning, to weak quality-judgment feedback that facilitate reinforcement learning. We present the first user study on annotation cost and machine learnability for the less popular annotation mode of error markings. We show that error markings for translations of TED talks from English to German allow precise credit assignment while requiring significantly less human effort than correcting/post-editing, and that error-marked data can be used successfully to fine-tune neural machine translation models.