 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperPIE: Hyperparameter Information Extraction from Scientific Publications
Dec 17, 2023Automatic extraction of information from publications is key to making scientific knowledge machine readable at a large scale. The extracted information can, for example, facilitate academic search, decision making, and knowledge graph construction. An important type of information not covered by existing approaches is hyperparameters. In this paper, we formalize and tackle hyperparameter information extraction (HyperPIE) as an entity recognition and relation extraction task. We create a labeled data set covering publications from a variety of computer science disciplines. Using this data set, we train and evaluate BERT-based fine-tuned models as well as five large language models: GPT-3.5, GALACTICA, Falcon, Vicuna, and WizardLM. For fine-tuned models, we develop a relation extraction approach that achieves an improvement of 29% F1 over a state-of-the-art baseline. For large language models, we develop an approach leveraging YAML output for structured data extraction, which achieves an average improvement of 5.5% F1 in entity recognition over using JSON. With our best performing model we extract hyperparameter information from a large number of unannotated papers, and analyze patterns across disciplines. All our data and source code is publicly available at https://github.com/IllDepence/hyperpie
JoeyS2T: Minimalistic Speech-to-Text Modeling with JoeyNMT
Oct 05, 2022
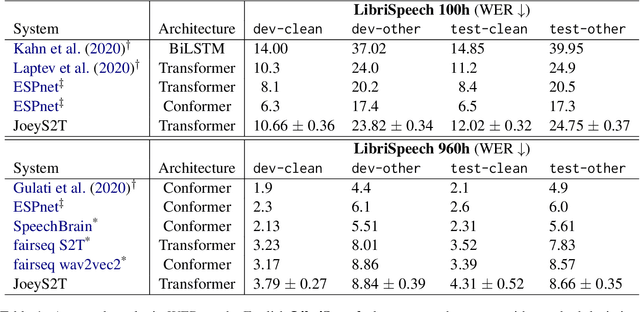
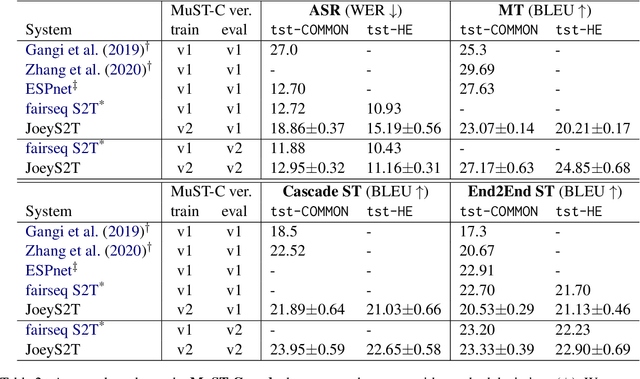

JoeyS2T is a JoeyNMT extension for speech-to-text tasks such as automatic speech recognition and end-to-end speech translation. It inherits the core philosophy of JoeyNMT, a minimalist NMT toolkit built on PyTorch, seeking simplicity and accessibility. JoeyS2T's workflow is self-contained, starting from data pre-processing, over model training and prediction to evaluation, and is seamlessly integrated into JoeyNMT's compact and simple code base. On top of JoeyNMT's state-of-the-art Transformer-based encoder-decoder architecture, JoeyS2T provides speech-oriented components such as convolutional layers, SpecAugment, CTC-loss, and WER evaluation. Despite its simplicity compared to prior implementations, JoeyS2T performs competitively on English speech recognition and English-to-German speech translation benchmarks. The implementation is accompanied by a walk-through tutorial and available on https://github.com/may-/joeys2t.
On-the-Fly Aligned Data Augmentation for Sequence-to-Sequence ASR
Apr 03, 2021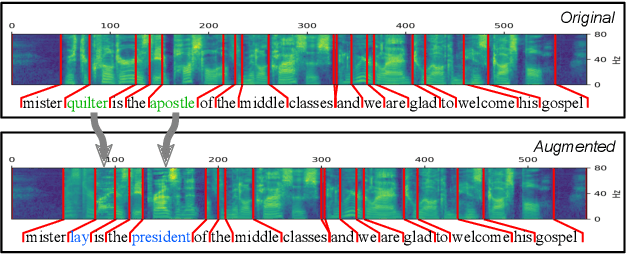
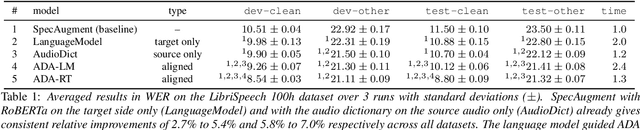
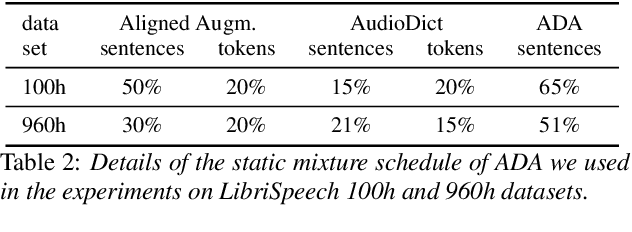

We propose an on-the-fly data augmentation method for automatic speech recognition (ASR) that uses alignment information to generate effective training samples. Our method, called Aligned Data Augmentation (ADA) for ASR, replaces transcribed tokens and the speech representations in an aligned manner to generate previously unseen training pairs. The speech representations are sampled from an audio dictionary that has been extracted from the training corpus and inject speaker variations into the training examples. The transcribed tokens are either predicted by a language model such that the augmented data pairs are semantically close to the original data, or randomly sampled. Both strategies result in training pairs that improve robustness in ASR training. Our experiments on a Seq-to-Seq architecture show that ADA can be applied on top of SpecAugment, and achieves about 9-23% and 4-15% relative improvements in WER over SpecAugment alone on LibriSpeech 100h and LibriSpeech 960h test datasets, respectively.
Sparse Perturbations for Improved Convergence in Stochastic Zeroth-Order Optimization
Jun 29, 2020



Interest in stochastic zeroth-order (SZO) methods has recently been revived in black-box optimization scenarios such as adversarial black-box attacks to deep neural networks. SZO methods only require the ability to evaluate the objective function at random input points, however, their weakness is the dependency of their convergence speed on the dimensionality of the function to be evaluated. We present a sparse SZO optimization method that reduces this factor to the expected dimensionality of the random perturbation during learning. We give a proof that justifies this reduction for sparse SZO optimization for non-convex functions without making any assumptions on sparsity of objective function or gradient. Furthermore, we present experimental results for neural networks on MNIST and CIFAR that show faster convergence in training loss and test accuracy, and a smaller distance of the gradient approximation to the true gradient in sparse SZO compared to dense SZO.