 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperPIE: Hyperparameter Information Extraction from Scientific Publications
Dec 17, 2023Automatic extraction of information from publications is key to making scientific knowledge machine readable at a large scale. The extracted information can, for example, facilitate academic search, decision making, and knowledge graph construction. An important type of information not covered by existing approaches is hyperparameters. In this paper, we formalize and tackle hyperparameter information extraction (HyperPIE) as an entity recognition and relation extraction task. We create a labeled data set covering publications from a variety of computer science disciplines. Using this data set, we train and evaluate BERT-based fine-tuned models as well as five large language models: GPT-3.5, GALACTICA, Falcon, Vicuna, and WizardLM. For fine-tuned models, we develop a relation extraction approach that achieves an improvement of 29% F1 over a state-of-the-art baseline. For large language models, we develop an approach leveraging YAML output for structured data extraction, which achieves an average improvement of 5.5% F1 in entity recognition over using JSON. With our best performing model we extract hyperparameter information from a large number of unannotated papers, and analyze patterns across disciplines. All our data and source code is publicly available at https://github.com/IllDepence/hyperpie
CoCon: A Data Set on Combined Contextualized Research Artifact Use
Mar 27, 2023In the wake of information overload in academia, methodologies and systems for search, recommendation, and prediction to aid researchers in identifying relevant research are actively studied and developed. Existing work, however, is limited in terms of granularity, focusing only on the level of papers or a single type of artifact, such as data sets. To enable more holistic analyses and systems dealing with academic publications and their content, we propose CoCon, a large scholarly data set reflecting the combined use of research artifacts, contextualized in academic publications' full-text. Our data set comprises 35 k artifacts (data sets, methods, models, and tasks) and 340 k publications. We additionally formalize a link prediction task for "combined research artifact use prediction" and provide code to utilize analyses of and the development of ML applications on our data. All data and code is publicly available at https://github.com/IllDepence/contextgraph.
unarXive 2022: All arXiv Publications Pre-Processed for NLP, Including Structured Full-Text and Citation Network
Mar 27, 2023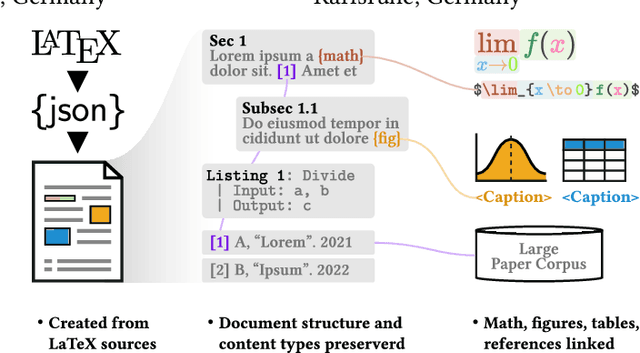
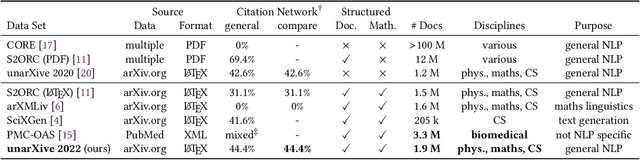
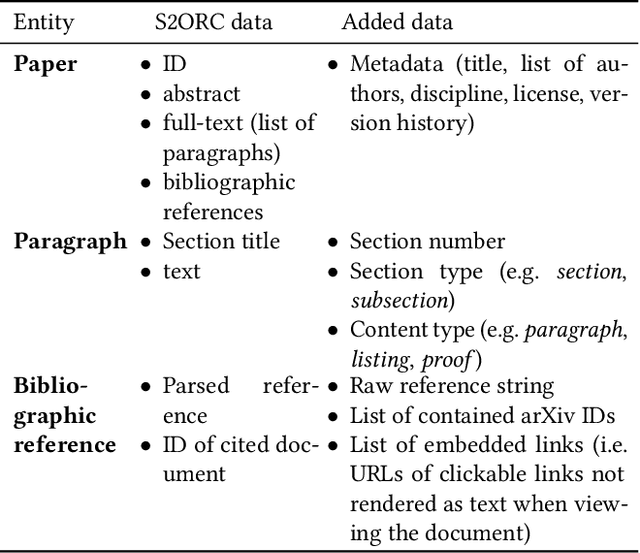
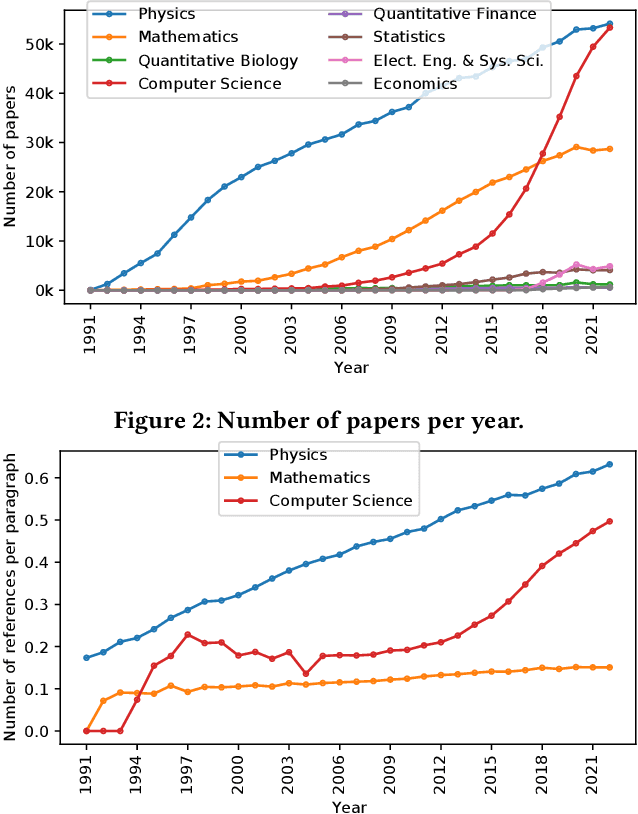
Large-scale data sets on scholarly publications are the basis for a variety of bibliometric analyses and natural language processing (NLP) applications. Especially data sets derived from publication's full-text have recently gained attention. While several such data sets already exist, we see key shortcomings in terms of their domain and time coverage, citation network completeness, and representation of full-text content. To address these points, we propose a new version of the data set unarXive. We base our data processing pipeline and output format on two existing data sets, and improve on each of them. Our resulting data set comprises 1.9 M publications spanning multiple disciplines and 32 years. It furthermore has a more complete citation network than its predecessors and retains a richer representation of document structure as well as non-textual publication content such as mathematical notation. In addition to the data set, we provide ready-to-use training/test data for citation recommendation and IMRaD classification. All data and source code is publicly available at https://github.com/IllDepence/unarXive.
Cross-Lingual Citations in English Papers: A Large-Scale Analysis of Prevalence, Usage, and Impact
Nov 10, 2021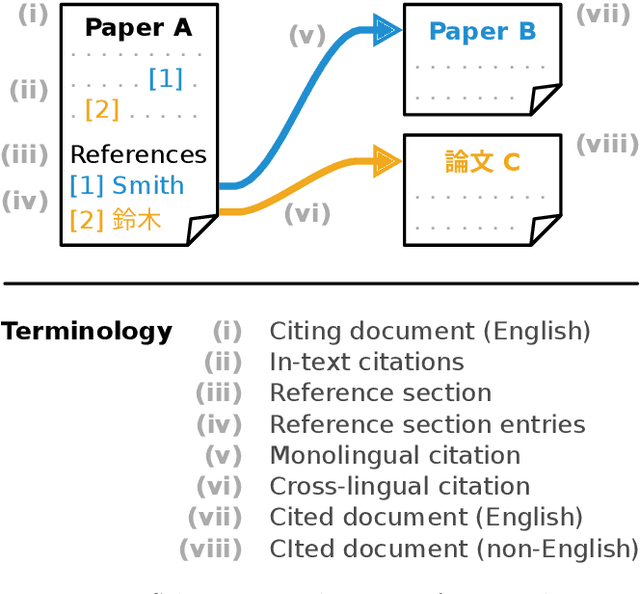

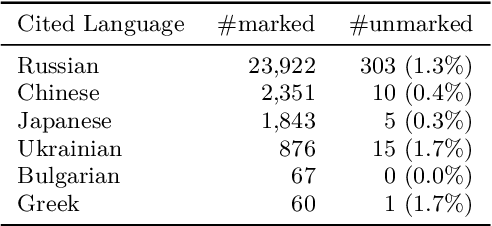
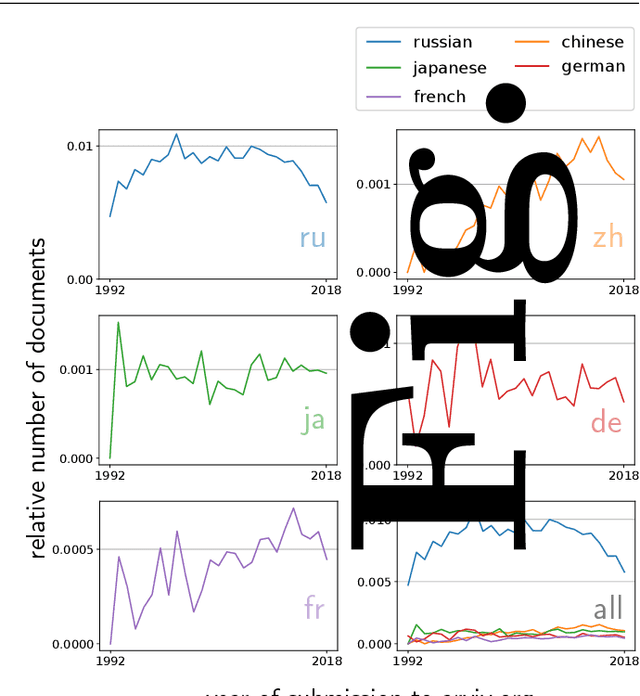
Citation information in scholarly data is an important source of insight into the reception of publications and the scholarly discourse. Outcomes of citation analyses and the applicability of citation based machine learning approaches heavily depend on the completeness of such data. One particular shortcoming of scholarly data nowadays is that non-English publications are often not included in data sets, or that language metadata is not available. Because of this, citations between publications of differing languages (cross-lingual citations) have only been studied to a very limited degree. In this paper, we present an analysis of cross-lingual citations based on over one million English papers, spanning three scientific disciplines and a time span of three decades. Our investigation covers differences between cited languages and disciplines, trends over time, and the usage characteristics as well as impact of cross-lingual citations. Among our findings are an increasing rate of citations to publications written in Chinese, citations being primarily to local non-English languages, and consistency in citation intent between cross- and monolingual citations. To facilitate further research, we make our collected data and source code publicly available.