 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemOpenAlex: The Scientific Landscape in 26 Billion RDF Triples
Aug 07, 2023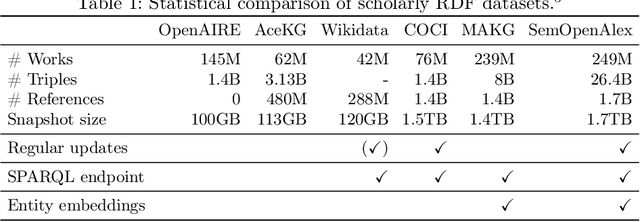
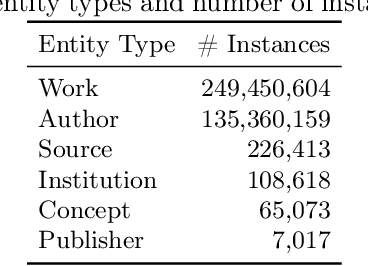
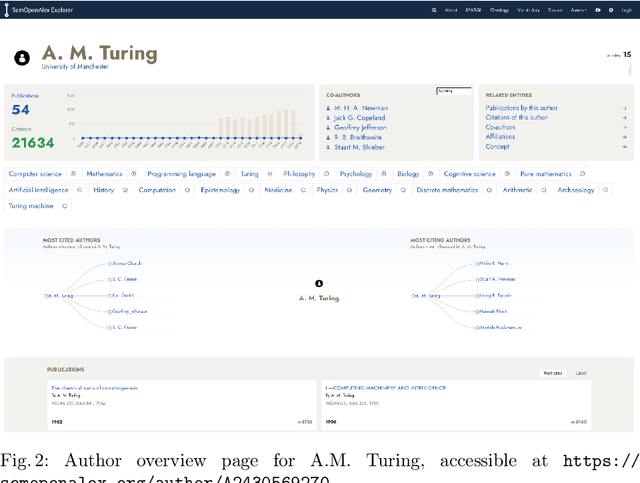
We present SemOpenAlex, an extensive RDF knowledge graph that contains over 26 billion triples about scientific publications and their associated entities, such as authors, institutions, journals, and concepts. SemOpenAlex is licensed under CC0, providing free and open access to the data. We offer the data through multiple channels, including RDF dump files, a SPARQL endpoint, and as a data source in the Linked Open Data cloud, complete with resolvable URIs and links to other data sources. Moreover, we provide embeddings for knowledge graph entities using high-performance computing. SemOpenAlex enables a broad range of use-case scenarios, such as exploratory semantic search via our website, large-scale scientific impact quantification, and other forms of scholarly big data analytics within and across scientific disciplines. Additionally, it enables academic recommender systems, such as recommending collaborators, publications, and venues, including explainability capabilities. Finally, SemOpenAlex can serve for RDF query optimization benchmarks, creating scholarly knowledge-guided language models, and as a hub for semantic scientific publishing.
unarXive 2022: All arXiv Publications Pre-Processed for NLP, Including Structured Full-Text and Citation Network
Mar 27, 2023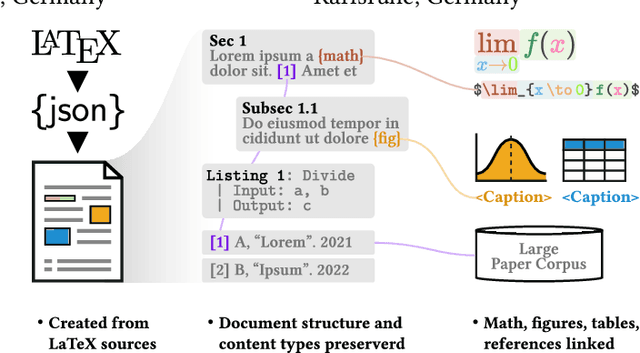
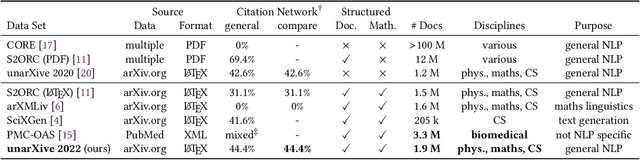
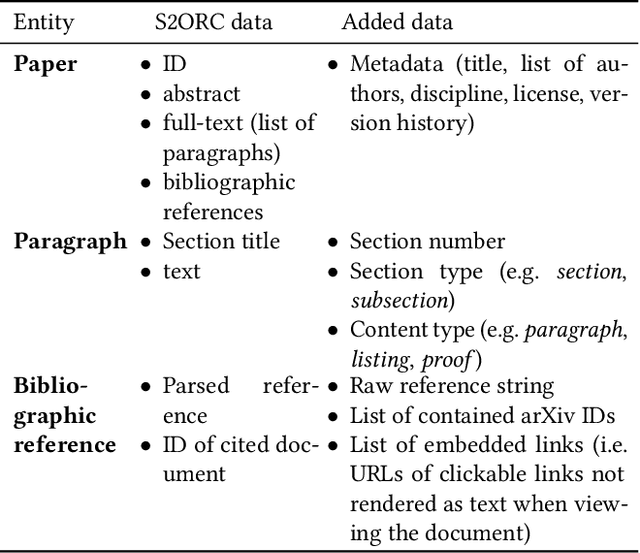
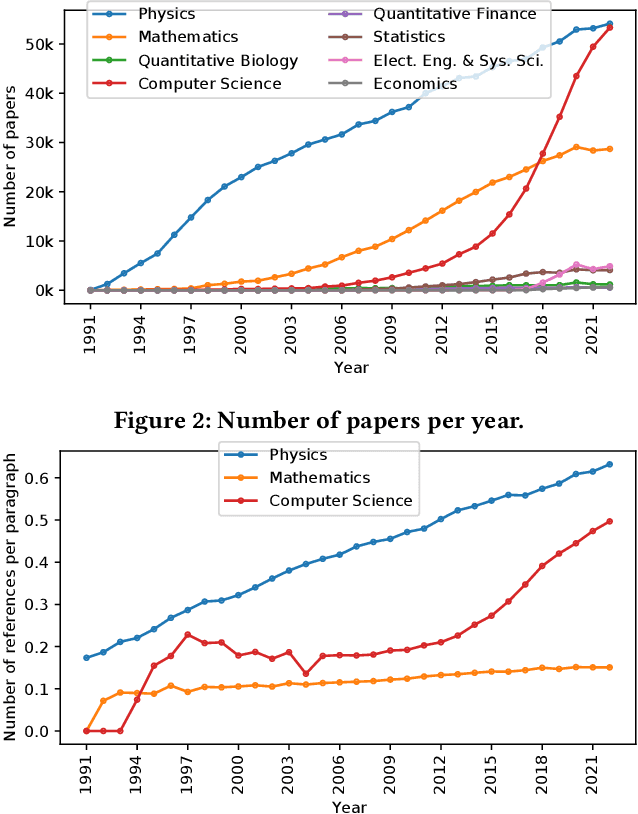
Large-scale data sets on scholarly publications are the basis for a variety of bibliometric analyses and natural language processing (NLP) applications. Especially data sets derived from publication's full-text have recently gained attention. While several such data sets already exist, we see key shortcomings in terms of their domain and time coverage, citation network completeness, and representation of full-text content. To address these points, we propose a new version of the data set unarXive. We base our data processing pipeline and output format on two existing data sets, and improve on each of them. Our resulting data set comprises 1.9 M publications spanning multiple disciplines and 32 years. It furthermore has a more complete citation network than its predecessors and retains a richer representation of document structure as well as non-textual publication content such as mathematical notation. In addition to the data set, we provide ready-to-use training/test data for citation recommendation and IMRaD classification. All data and source code is publicly available at https://github.com/IllDepence/unarXive.