 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperPIE: Hyperparameter Information Extraction from Scientific Publications
Dec 17, 2023Automatic extraction of information from publications is key to making scientific knowledge machine readable at a large scale. The extracted information can, for example, facilitate academic search, decision making, and knowledge graph construction. An important type of information not covered by existing approaches is hyperparameters. In this paper, we formalize and tackle hyperparameter information extraction (HyperPIE) as an entity recognition and relation extraction task. We create a labeled data set covering publications from a variety of computer science disciplines. Using this data set, we train and evaluate BERT-based fine-tuned models as well as five large language models: GPT-3.5, GALACTICA, Falcon, Vicuna, and WizardLM. For fine-tuned models, we develop a relation extraction approach that achieves an improvement of 29% F1 over a state-of-the-art baseline. For large language models, we develop an approach leveraging YAML output for structured data extraction, which achieves an average improvement of 5.5% F1 in entity recognition over using JSON. With our best performing model we extract hyperparameter information from a large number of unannotated papers, and analyze patterns across disciplines. All our data and source code is publicly available at https://github.com/IllDepence/hyperpie
A Quantitative Evaluation of Natural Language Question Interpretation for Question Answering Systems
Sep 20, 2018
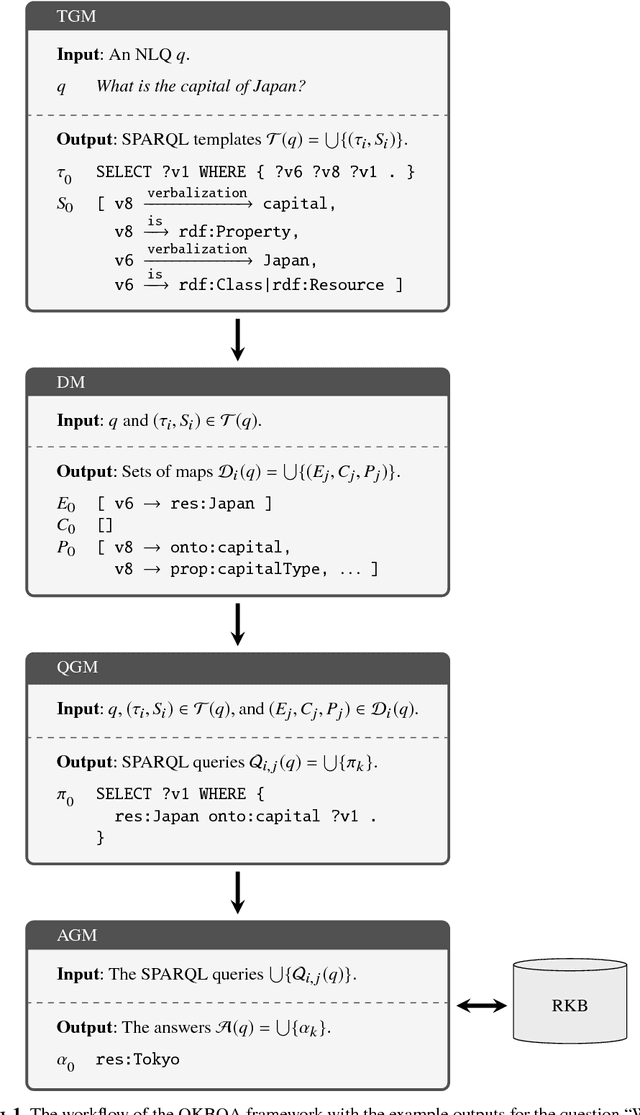
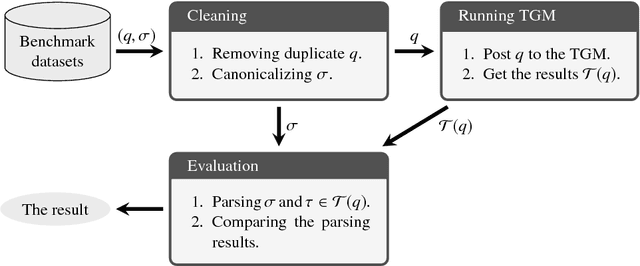

Systematic benchmark evaluation plays an important role in the process of improving technologies for Question Answering (QA) systems. While currently there are a number of existing evaluation methods for natural language (NL) QA systems, most of them consider only the final answers, limiting their utility within a black box style evaluation. Herein, we propose a subdivided evaluation approach to enable finer-grained evaluation of QA systems, and present an evaluation tool which targets the NL question (NLQ) interpretation step, an initial step of a QA pipeline. The results of experiments using two public benchmark datasets suggest that we can get a deeper insight about the performance of a QA system using the proposed approach, which should provide a better guidance for improving the systems, than using black box style approaches.