Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrect Me If You Can: Learning from Error Corrections and Markings
Paper and Code
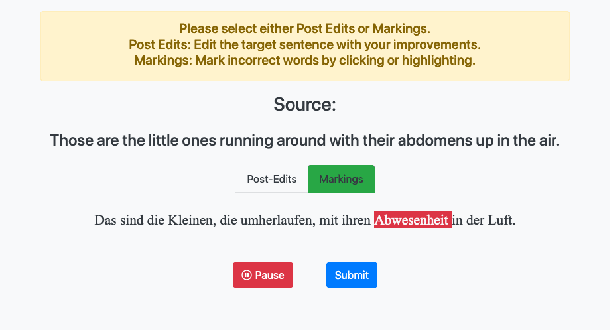



Sequence-to-sequence learning involves a trade-off between signal strength and annotation cost of training data. For example, machine translation data range from costly expert-generated translations that enable supervised learning, to weak quality-judgment feedback that facilitate reinforcement learning. We present the first user study on annotation cost and machine learnability for the less popular annotation mode of error markings. We show that error markings for translations of TED talks from English to German allow precise credit assignment while requiring significantly less human effort than correcting/post-editing, and that error-marked data can be used successfully to fine-tune neural machine translation models.
* To appear at EAMT 2020 (Research Track)
View paper on