 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature-based morphological analysis of shape graph data
Feb 18, 2026This paper introduces and demonstrates a computational pipeline for the statistical analysis of shape graph datasets, namely geometric networks embedded in 2D or 3D spaces. Unlike traditional abstract graphs, our purpose is not only to retrieve and distinguish variations in the connectivity structure of the data but also geometric differences of the network branches. Our proposed approach relies on the extraction of a specifically curated and explicit set of topological, geometric and directional features, designed to satisfy key invariance properties. We leverage the resulting feature representation for tasks such as group comparison, clustering and classification on cohorts of shape graphs. The effectiveness of this representation is evaluated on several real-world datasets including urban road/street networks, neuronal traces and astrocyte imaging. These results are benchmarked against several alternative methods, both feature-based and not.
Fast $k$-means clustering in Riemannian manifolds via Fréchet maps: Applications to large-dimensional SPD matrices
Nov 12, 2025We introduce a novel, efficient framework for clustering data on high-dimensional, non-Euclidean manifolds that overcomes the computational challenges associated with standard intrinsic methods. The key innovation is the use of the $p$-Fréchet map $F^p : \mathcal{M} \to \mathbb{R}^\ell$ -- defined on a generic metric space $\mathcal{M}$ -- which embeds the manifold data into a lower-dimensional Euclidean space $\mathbb{R}^\ell$ using a set of reference points $\{r_i\}_{i=1}^\ell$, $r_i \in \mathcal{M}$. Once embedded, we can efficiently and accurately apply standard Euclidean clustering techniques such as k-means. We rigorously analyze the mathematical properties of $F^p$ in the Euclidean space and the challenging manifold of $n \times n$ symmetric positive definite matrices $\mathit{SPD}(n)$. Extensive numerical experiments using synthetic and real $\mathit{SPD}(n)$ data demonstrate significant performance gains: our method reduces runtime by up to two orders of magnitude compared to intrinsic manifold-based approaches, all while maintaining high clustering accuracy, including scenarios where existing alternative methods struggle or fail.
Diffeomorphic Latent Neural Operators for Data-Efficient Learning of Solutions to Partial Differential Equations
Nov 29, 2024



A computed approximation of the solution operator to a system of partial differential equations (PDEs) is needed in various areas of science and engineering. Neural operators have been shown to be quite effective at predicting these solution generators after training on high-fidelity ground truth data (e.g. numerical simulations). However, in order to generalize well to unseen spatial domains, neural operators must be trained on an extensive amount of geometrically varying data samples that may not be feasible to acquire or simulate in certain contexts (e.g., patient-specific medical data, large-scale computationally intensive simulations.) We propose that in order to learn a PDE solution operator that can generalize across multiple domains without needing to sample enough data expressive enough for all possible geometries, we can train instead a latent neural operator on just a few ground truth solution fields diffeomorphically mapped from different geometric/spatial domains to a fixed reference configuration. Furthermore, the form of the solutions is dependent on the choice of mapping to and from the reference domain. We emphasize that preserving properties of the differential operator when constructing these mappings can significantly reduce the data requirement for achieving an accurate model due to the regularity of the solution fields that the latent neural operator is training on. We provide motivating numerical experimentation that demonstrates an extreme case of this consideration by exploiting the conformal invariance of the Laplacian
Diffeomorphic Latent Neural Operator Learning for Data-Efficient Predictions of Solutions to Partial Differential Equations
Nov 27, 2024A computed approximation of the solution operator to a system of partial differential equations (PDEs) is needed in various areas of science and engineering. Neural operators have been shown to be quite effective at predicting these solution generators after training on high-fidelity ground truth data (e.g. numerical simulations). However, in order to generalize well to unseen spatial domains, neural operators must be trained on an extensive amount of geometrically varying data samples that may not be feasible to acquire or simulate in certain contexts (i.e., patient-specific medical data, large-scale computationally intensive simulations.) We propose that in order to learn a PDE solution operator that can generalize across multiple domains without needing to sample enough data expressive enough for all possible geometries, we can train instead a latent neural operator on just a few ground truth solution fields diffeomorphically mapped from different geometric/spatial domains to a fixed reference configuration. Furthermore, the form of the solutions is dependent on the choice of mapping to and from the reference domain. We emphasize that preserving properties of the differential operator when constructing these mappings can significantly reduce the data requirement for achieving an accurate model due to the regularity of the solution fields that the latent neural operator is training on. We provide motivating numerical experimentation that demonstrates an extreme case of this consideration by exploiting the conformal invariance of the Laplacian
Self Supervised Networks for Learning Latent Space Representations of Human Body Scans and Motions
Nov 05, 2024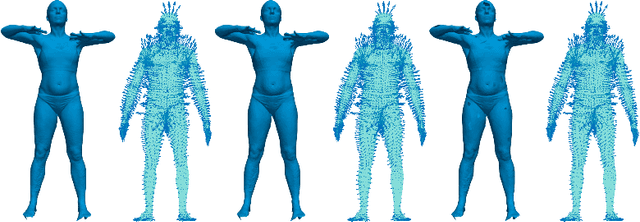

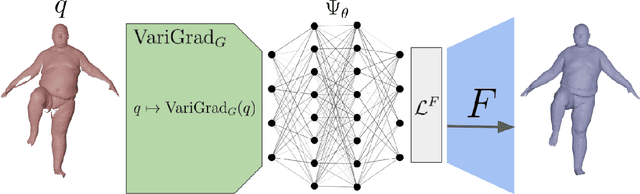

This paper introduces self-supervised neural network models to tackle several fundamental problems in the field of 3D human body analysis and processing. First, we propose VariShaPE (Varifold Shape Parameter Estimator), a novel architecture for the retrieval of latent space representations of body shapes and poses. This network offers a fast and robust method to estimate the embedding of arbitrary unregistered meshes into the latent space. Second, we complement the estimation of latent codes with MoGeN (Motion Geometry Network) a framework that learns the geometry on the latent space itself. This is achieved by lifting the body pose parameter space into a higher dimensional Euclidean space in which body motion mini-sequences from a training set of 4D data can be approximated by simple linear interpolation. Using the SMPL latent space representation we illustrate how the combination of these network models, once trained, can be used to perform a variety of tasks with very limited computational cost. This includes operations such as motion interpolation, extrapolation and transfer as well as random shape and pose generation.
DIMON: Learning Solution Operators of Partial Differential Equations on a Diffeomorphic Family of Domains
Feb 11, 2024



The solution of a PDE over varying initial/boundary conditions on multiple domains is needed in a wide variety of applications, but it is computationally expensive if the solution is computed de novo whenever the initial/boundary conditions of the domain change. We introduce a general operator learning framework, called DIffeomorphic Mapping Operator learNing (DIMON) to learn approximate PDE solutions over a family of domains $\{\Omega_{\theta}}_\theta$, that learns the map from initial/boundary conditions and domain $\Omega_\theta$ to the solution of the PDE, or to specified functionals thereof. DIMON is based on transporting a given problem (initial/boundary conditions and domain $\Omega_{\theta}$) to a problem on a reference domain $\Omega_{0}$, where training data from multiple problems is used to learn the map to the solution on $\Omega_{0}$, which is then re-mapped to the original domain $\Omega_{\theta}$. We consider several problems to demonstrate the performance of the framework in learning both static and time-dependent PDEs on non-rigid geometries; these include solving the Laplace equation, reaction-diffusion equations, and a multiscale PDE that characterizes the electrical propagation on the left ventricle. This work paves the way toward the fast prediction of PDE solutions on a family of domains and the application of neural operators in engineering and precision medicine.
Basis restricted elastic shape analysis on the space of unregistered surfaces
Nov 07, 2023This paper introduces a new mathematical and numerical framework for surface analysis derived from the general setting of elastic Riemannian metrics on shape spaces. Traditionally, those metrics are defined over the infinite dimensional manifold of immersed surfaces and satisfy specific invariance properties enabling the comparison of surfaces modulo shape preserving transformations such as reparametrizations. The specificity of the approach we develop is to restrict the space of allowable transformations to predefined finite dimensional bases of deformation fields. These are estimated in a data-driven way so as to emulate specific types of surface transformations observed in a training set. The use of such bases allows to simplify the representation of the corresponding shape space to a finite dimensional latent space. However, in sharp contrast with methods involving e.g. mesh autoencoders, the latent space is here equipped with a non-Euclidean Riemannian metric precisely inherited from the family of aforementioned elastic metrics. We demonstrate how this basis restricted model can be then effectively implemented to perform a variety of tasks on surface meshes which, importantly, does not assume these to be pre-registered (i.e. with given point correspondences) or to even have a consistent mesh structure. We specifically validate our approach on human body shape and pose data as well as human face scans, and show how it generally outperforms state-of-the-art methods on problems such as shape registration, interpolation, motion transfer or random pose generation.
BaRe-ESA: A Riemannian Framework for Unregistered Human Body Shapes
Nov 23, 2022



We present BaRe-ESA, a novel Riemannian framework for human body scan representation, interpolation and extrapolation. BaRe-ESA operates directly on unregistered meshes, i.e., without the need to establish prior point to point correspondences or to assume a consistent mesh structure. Our method relies on a latent space representation, which is equipped with a Riemannian (non-Euclidean) metric associated to an invariant higher-order metric on the space of surfaces. Experimental results on the FAUST and DFAUST datasets show that BaRe-ESA brings significant improvements with respect to previous solutions in terms of shape registration, interpolation and extrapolation. The efficiency and strength of our model is further demonstrated in applications such as motion transfer and random generation of body shape and pose.
A Diffeomorphic Flow-based Variational Framework for Multi-speaker Emotion Conversion
Nov 09, 2022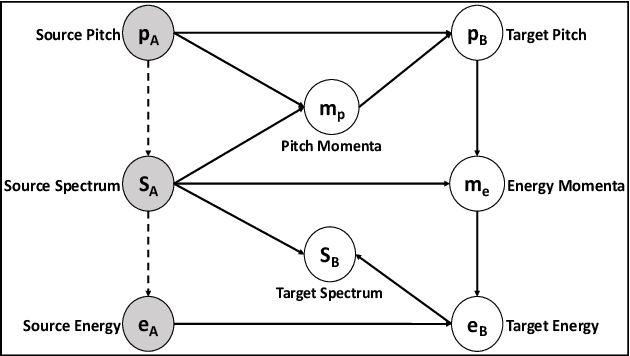
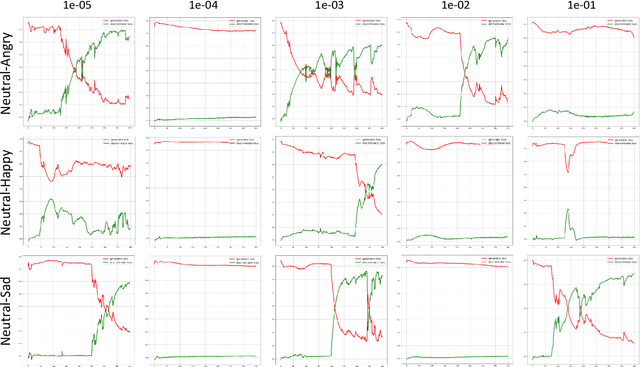
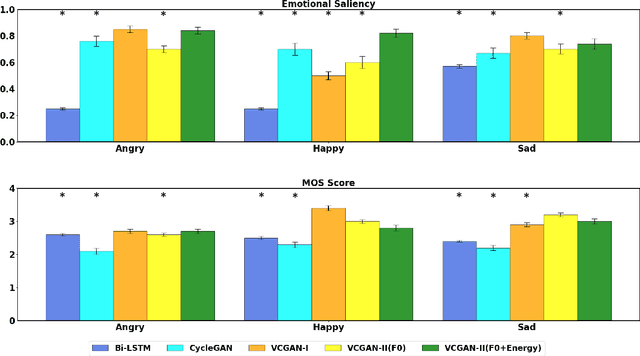
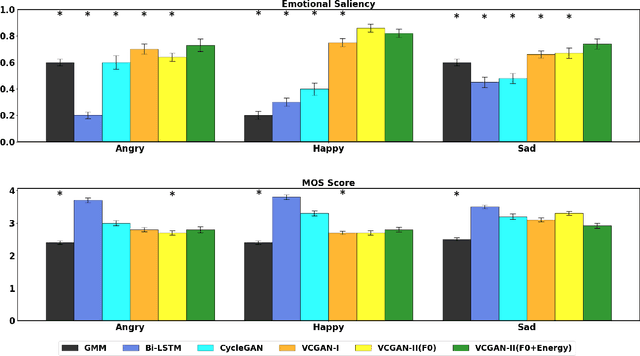
This paper introduces a new framework for non-parallel emotion conversion in speech. Our framework is based on two key contributions. First, we propose a stochastic version of the popular CycleGAN model. Our modified loss function introduces a Kullback Leibler (KL) divergence term that aligns the source and target data distributions learned by the generators, thus overcoming the limitations of sample wise generation. By using a variational approximation to this stochastic loss function, we show that our KL divergence term can be implemented via a paired density discriminator. We term this new architecture a variational CycleGAN (VCGAN). Second, we model the prosodic features of target emotion as a smooth and learnable deformation of the source prosodic features. This approach provides implicit regularization that offers key advantages in terms of better range alignment to unseen and out of distribution speakers. We conduct rigorous experiments and comparative studies to demonstrate that our proposed framework is fairly robust with high performance against several state-of-the-art baselines.
Elastic shape analysis of surfaces with second-order Sobolev metrics: a comprehensive numerical framework
Apr 08, 2022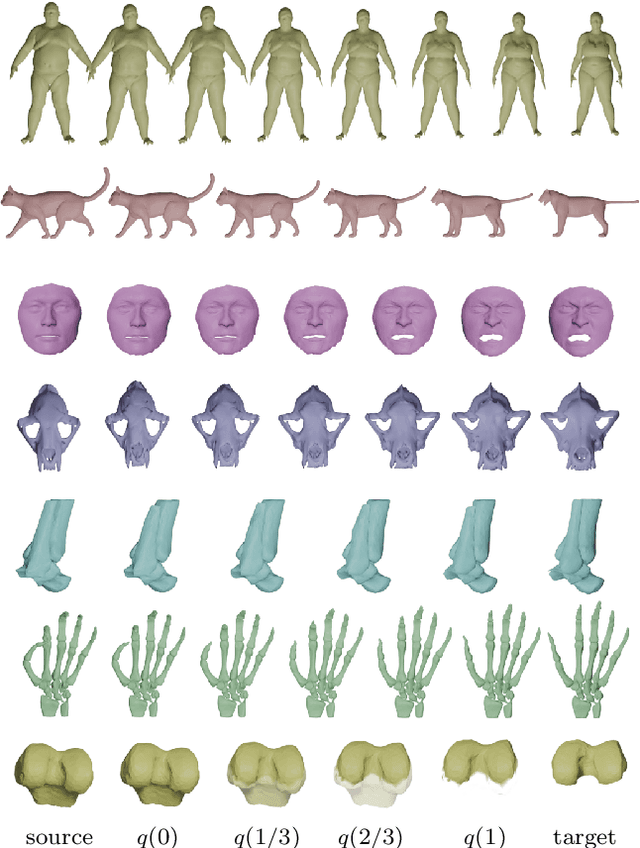
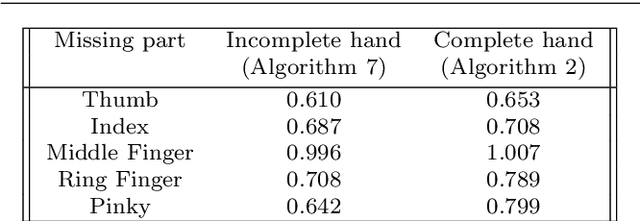

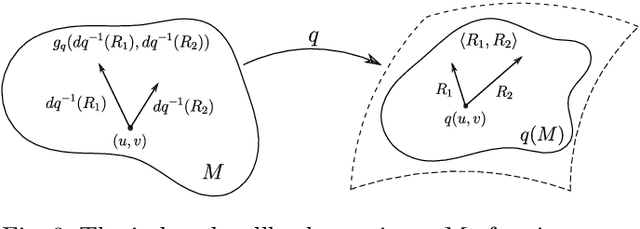
This paper introduces a set of numerical methods for Riemannian shape analysis of 3D surfaces within the setting of invariant (elastic) second-order Sobolev metrics. More specifically, we address the computation of geodesics and geodesic distances between parametrized or unparametrized immersed surfaces represented as 3D meshes. Building on this, we develop tools for the statistical shape analysis of sets of surfaces, including methods for estimating Karcher means and performing tangent PCA on shape populations, and for computing parallel transport along paths of surfaces. Our proposed approach fundamentally relies on a relaxed variational formulation for the geodesic matching problem via the use of varifold fidelity terms, which enable us to enforce reparametrization independence when computing geodesics between unparametrized surfaces, while also yielding versatile algorithms that allow us to compare surfaces with varying sampling or mesh structures. Importantly, we demonstrate how our relaxed variational framework can be extended to tackle partially observed data. The different benefits of our numerical pipeline are illustrated over various examples, synthetic and real.