 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREACT 2026: The Fourth Multiple Appropriate Facial Reaction Generation Challenge: Personalised MAFRG and Appropriate EEG Reaction Prediction
Jun 06, 2026In dyadic interactions, various human facial reactions could be appropriate for responding to each human speaker behaviour. Following the successful organisation of the REACT 2023, 2024 and 2025 challenge series, a body of generative deep learning (DL) models have been developed for the problem of multiple appropriate facial reaction generation (MAFRG). This year, we propose the REACT 2026 challenge encouraging the development and benchmarking of Machine Learning (ML) models that can generate multiple personalised, appropriate, diverse, realistic and synchronised human-style facial reactions expressed by a specific human listener for responding to each given speaker behaviour. As a key of the challenge, we continuously provide challenge participants with MARS dataset introduced by REACT 2025 but additionally provide individual-level Big-Five personality labels and EEG recordings. This introduces a new one-to-many personalised facial reaction generation setting combining human expressive behavioural, affective and neurophysiological signals, which remains largely unexplored in current dyadic interaction modelling. This paper also presents the challenge guidelines and new baselines on the four proposed sub-challenges: Offline generic and personalised MAFRG as well as Online generic and personalised MAFRG, respectively, which are publicly available at https://github.com/reactmultimodalchallenge/baseline_react2026.
FreeTalk: Emotional Topology-Free 3D Talking Heads
Mar 16, 2026Speech-driven 3D facial animation has advanced rapidly, yet most approaches remain tied to registered template meshes, preventing effective deployment on raw 3D scans with arbitrary topology. At the same time, modeling controllable emotional dynamics beyond lip articulation remains challenging, and is often tied to template-based parameterizations. We address these challenges by proposing FreeTalk, a two-stage framework for emotion-conditioned 3D talking-head animation that generalizes to unregistered face meshes with arbitrary vertex count and connectivity. First, Audio-To-Sparse (ATS) predicts a temporally coherent sequence of 3D landmark displacements from speech audio, conditioned on an emotion category and intensity. This sparse representation captures both articulatory and affective motion while remaining independent of mesh topology. Second, Sparse-To-Mesh (STM) transfers the predicted landmark motion to a target mesh by combining intrinsic surface features with landmark-to-vertex conditioning, producing dense per-vertex deformations without template fitting or correspondence supervision at test time. Extensive experiments show that FreeTalk matches specialized baselines when trained in-domain, while providing substantially improved robustness to unseen identities and mesh topologies. Code and pre-trained models will be made publicly available.
DEGMC: Denoising Diffusion Models Based on Riemannian Equivariant Group Morphological Convolutions
Feb 10, 2026In this work, we address two major issues in recent Denoising Diffusion Probabilistic Models (DDPM): {\bf 1)} geometric key feature extraction and {\bf 2)} network equivariance. Since the DDPM prediction network relies on the U-net architecture, which is theoretically only translation equivariant, we introduce a geometric approach combined with an equivariance property of the more general Euclidean group, which includes rotations, reflections, and permutations. We introduce the notion of group morphological convolutions in Riemannian manifolds, which are derived from the viscosity solutions of first-order Hamilton-Jacobi-type partial differential equations (PDEs) that act as morphological multiscale dilations and erosions. We add a convection term to the model and solve it using the method of characteristics. This helps us better capture nonlinearities, represent thin geometric structures, and incorporate symmetries into the learning process. Experimental results on the MNIST, RotoMNIST, and CIFAR-10 datasets show noticeable improvements compared to the baseline DDPM model.
Localized Latent Editing for Dose-Response Modeling in Botulinum Toxin Injection Planning
Jan 27, 2026Botulinum toxin (Botox) injections are the gold standard for managing facial asymmetry and aesthetic rejuvenation, yet determining the optimal dosage remains largely intuitive, often leading to suboptimal outcomes. We propose a localized latent editing framework that simulates Botulinum Toxin injection effects for injection planning through dose-response modeling. Our key contribution is a Region-Specific Latent Axis Discovery method that learns localized muscle relaxation trajectories in StyleGAN2's latent space, enabling precise control over specific facial regions without global side effects. By correlating these localized latent trajectories with injected toxin units, we learn a predictive dose-response model. We rigorously compare two approaches: direct metric regression versus image-based generative simulation on a clinical dataset of N=360 images from 46 patients. On a hold-out test set, our framework demonstrates moderate-to-strong structural correlations for geometric asymmetry metrics, confirming that the generative model correctly captures the direction of morphological changes. While biological variability limits absolute precision, we introduce a hybrid "Human-in-the-Loop" workflow where clinicians interactively refine simulations, bridging the gap between pathological reconstruction and cosmetic planning.
A Non-Invasive 3D Gait Analysis Framework for Quantifying Psychomotor Retardation in Major Depressive Disorder
Jan 27, 2026Predicting the status of Major Depressive Disorder (MDD) from objective, non-invasive methods is an active research field. Yet, extracting automatically objective, interpretable features for a detailed analysis of the patient state remains largely unexplored. Among MDD's symptoms, Psychomotor retardation (PMR) is a core item, yet its clinical assessment remains largely subjective. While 3D motion capture offers an objective alternative, its reliance on specialized hardware often precludes routine clinical use. In this paper, we propose a non-invasive computational framework that transforms monocular RGB video into clinically relevant 3D gait kinematics. Our pipeline uses Gravity-View Coordinates along with a novel trajectory-correction algorithm that leverages the closed-loop topology of our adapted Timed Up and Go (TUG) protocol to mitigate monocular depth errors. This novel pipeline enables the extraction of 297 explicit gait biomechanical biomarkers from a single camera capture. To address the challenges of small clinical datasets, we introduce a stability-based machine learning framework that identifies robust motor signatures while preventing overfitting. Validated on the CALYPSO dataset, our method achieves an 83.3% accuracy in detecting PMR and explains 64% of the variance in overall depression severity (R^2=0.64). Notably, our study reveals a strong link between reduced ankle propulsion and restricted pelvic mobility to the depressive motor phenotype. These results demonstrate that physical movement serves as a robust proxy for the cognitive state, offering a transparent and scalable tool for the objective monitoring of depression in standard clinical environments.
REACT 2025: the Third Multiple Appropriate Facial Reaction Generation Challenge
May 22, 2025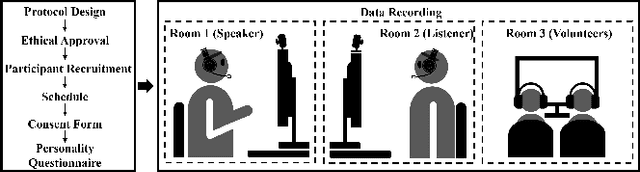

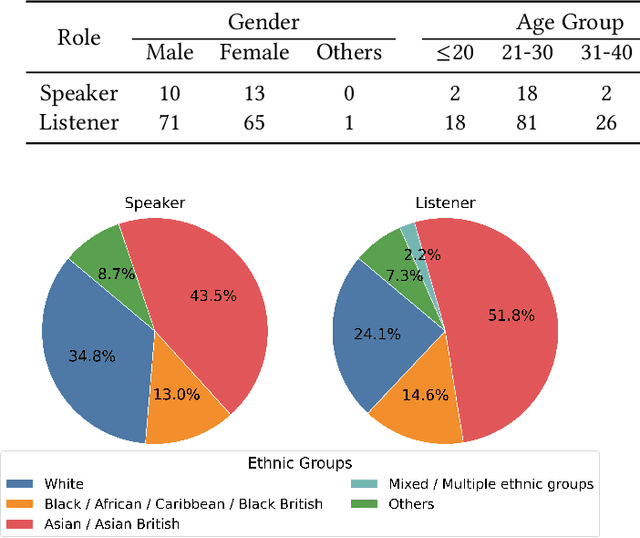
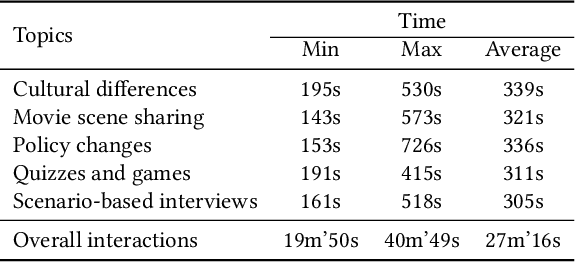
In dyadic interactions, a broad spectrum of human facial reactions might be appropriate for responding to each human speaker behaviour. Following the successful organisation of the REACT 2023 and REACT 2024 challenges, we are proposing the REACT 2025 challenge encouraging the development and benchmarking of Machine Learning (ML) models that can be used to generate multiple appropriate, diverse, realistic and synchronised human-style facial reactions expressed by human listeners in response to an input stimulus (i.e., audio-visual behaviours expressed by their corresponding speakers). As a key of the challenge, we provide challenge participants with the first natural and large-scale multi-modal MAFRG dataset (called MARS) recording 137 human-human dyadic interactions containing a total of 2856 interaction sessions covering five different topics. In addition, this paper also presents the challenge guidelines and the performance of our baselines on the two proposed sub-challenges: Offline MAFRG and Online MAFRG, respectively. The challenge baseline code is publicly available at https://github.com/reactmultimodalchallenge/baseline_react2025
Wearable-Derived Behavioral and Physiological Biomarkers for Classifying Unipolar and Bipolar Depression Severity
Apr 17, 2025Depression is a complex mental disorder characterized by a diverse range of observable and measurable indicators that go beyond traditional subjective assessments. Recent research has increasingly focused on objective, passive, and continuous monitoring using wearable devices to gain more precise insights into the physiological and behavioral aspects of depression. However, most existing studies primarily distinguish between healthy and depressed individuals, adopting a binary classification that fails to capture the heterogeneity of depressive disorders. In this study, we leverage wearable devices to predict depression subtypes-specifically unipolar and bipolar depression-aiming to identify distinctive biomarkers that could enhance diagnostic precision and support personalized treatment strategies. To this end, we introduce the CALYPSO dataset, designed for non-invasive detection of depression subtypes and symptomatology through physiological and behavioral signals, including blood volume pulse, electrodermal activity, body temperature, and three-axis acceleration. Additionally, we establish a benchmark on the dataset using well-known features and standard machine learning methods. Preliminary results indicate that features related to physical activity, extracted from accelerometer data, are the most effective in distinguishing between unipolar and bipolar depression, achieving an accuracy of $96.77\%$. Temperature-based features also showed high discriminative power, reaching an accuracy of $93.55\%$. These findings highlight the potential of physiological and behavioral monitoring for improving the classification of depressive subtypes, paving the way for more tailored clinical interventions.
Measuring Anxiety Levels with Head Motion Patterns in Severe Depression Population
Feb 12, 2025Depression and anxiety are prevalent mental health disorders that frequently cooccur, with anxiety significantly influencing both the manifestation and treatment of depression. An accurate assessment of anxiety levels in individuals with depression is crucial to develop effective and personalized treatment plans. This study proposes a new noninvasive method for quantifying anxiety severity by analyzing head movements -specifically speed, acceleration, and angular displacement - during video-recorded interviews with patients suffering from severe depression. Using data from a new CALYPSO Depression Dataset, we extracted head motion characteristics and applied regression analysis to predict clinically evaluated anxiety levels. Our results demonstrate a high level of precision, achieving a mean absolute error (MAE) of 0.35 in predicting the severity of psychological anxiety based on head movement patterns. This indicates that our approach can enhance the understanding of anxiety's role in depression and assist psychiatrists in refining treatment strategies for individuals.
Partial Non-rigid Deformations and interpolations of Human Body Surfaces
Dec 03, 2024



Non-rigid shape deformations pose significant challenges, and most existing methods struggle to handle partial deformations effectively. We present Partial Non-rigid Deformations and interpolations of the human body Surfaces (PaNDAS), a new method to learn local and global deformations of 3D surface meshes by building on recent deep models. Unlike previous approaches, our method enables restricting deformations to specific parts of the shape in a versatile way and allows for mixing and combining various poses from the database, all while not requiring any optimization at inference time. We demonstrate that the proposed framework can be used to generate new shapes, interpolate between parts of shapes, and perform other shape manipulation tasks with state-of-the-art accuracy and greater locality across various types of human surface data. Code and data will be made available soon.
Beyond Fixed Topologies: Unregistered Training and Comprehensive Evaluation Metrics for 3D Talking Heads
Oct 14, 2024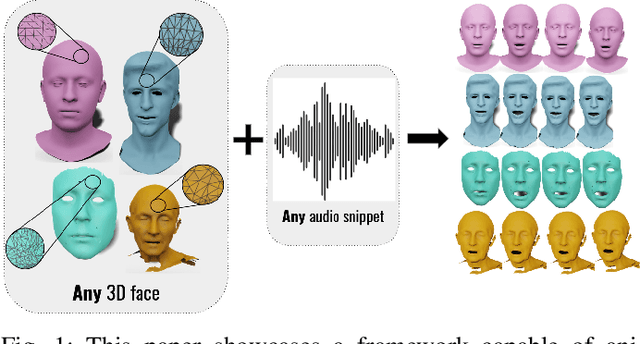
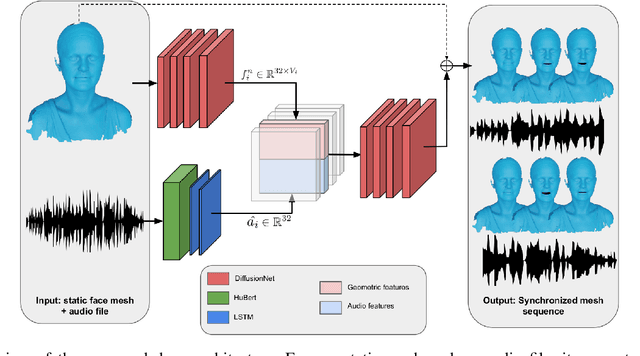
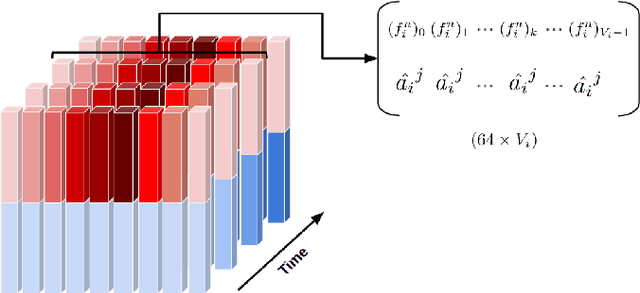

Generating speech-driven 3D talking heads presents numerous challenges; among those is dealing with varying mesh topologies. Existing methods require a registered setting, where all meshes share a common topology: a point-wise correspondence across all meshes the model can animate. While simplifying the problem, it limits applicability as unseen meshes must adhere to the training topology. This work presents a framework capable of animating 3D faces in arbitrary topologies, including real scanned data. Our approach relies on a model leveraging heat diffusion over meshes to overcome the fixed topology constraint. We explore two training settings: a supervised one, in which training sequences share a fixed topology within a sequence but any mesh can be animated at test time, and an unsupervised one, which allows effective training with varying mesh structures. Additionally, we highlight the limitations of current evaluation metrics and propose new metrics for better lip-syncing evaluation between speech and facial movements. Our extensive evaluation shows our approach performs favorably compared to fixed topology techniques, setting a new benchmark by offering a versatile and high-fidelity solution for 3D talking head generation.