 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreeTalk: Emotional Topology-Free 3D Talking Heads
Mar 16, 2026Speech-driven 3D facial animation has advanced rapidly, yet most approaches remain tied to registered template meshes, preventing effective deployment on raw 3D scans with arbitrary topology. At the same time, modeling controllable emotional dynamics beyond lip articulation remains challenging, and is often tied to template-based parameterizations. We address these challenges by proposing FreeTalk, a two-stage framework for emotion-conditioned 3D talking-head animation that generalizes to unregistered face meshes with arbitrary vertex count and connectivity. First, Audio-To-Sparse (ATS) predicts a temporally coherent sequence of 3D landmark displacements from speech audio, conditioned on an emotion category and intensity. This sparse representation captures both articulatory and affective motion while remaining independent of mesh topology. Second, Sparse-To-Mesh (STM) transfers the predicted landmark motion to a target mesh by combining intrinsic surface features with landmark-to-vertex conditioning, producing dense per-vertex deformations without template fitting or correspondence supervision at test time. Extensive experiments show that FreeTalk matches specialized baselines when trained in-domain, while providing substantially improved robustness to unseen identities and mesh topologies. Code and pre-trained models will be made publicly available.
3D Face Reconstruction Error Decomposed: A Modular Benchmark for Fair and Fast Method Evaluation
May 23, 2025Computing the standard benchmark metric for 3D face reconstruction, namely geometric error, requires a number of steps, such as mesh cropping, rigid alignment, or point correspondence. Current benchmark tools are monolithic (they implement a specific combination of these steps), even though there is no consensus on the best way to measure error. We present a toolkit for a Modularized 3D Face reconstruction Benchmark (M3DFB), where the fundamental components of error computation are segregated and interchangeable, allowing one to quantify the effect of each. Furthermore, we propose a new component, namely correction, and present a computationally efficient approach that penalizes for mesh topology inconsistency. Using this toolkit, we test 16 error estimators with 10 reconstruction methods on two real and two synthetic datasets. Critically, the widely used ICP-based estimator provides the worst benchmarking performance, as it significantly alters the true ranking of the top-5 reconstruction methods. Notably, the correlation of ICP with the true error can be as low as 0.41. Moreover, non-rigid alignment leads to significant improvement (correlation larger than 0.90), highlighting the importance of annotating 3D landmarks on datasets. Finally, the proposed correction scheme, together with non-rigid warping, leads to an accuracy on a par with the best non-rigid ICP-based estimators, but runs an order of magnitude faster. Our open-source codebase is designed for researchers to easily compare alternatives for each component, thus helping accelerating progress in benchmarking for 3D face reconstruction and, furthermore, supporting the improvement of learned reconstruction methods, which depend on accurate error estimation for effective training.
Beyond Fixed Topologies: Unregistered Training and Comprehensive Evaluation Metrics for 3D Talking Heads
Oct 14, 2024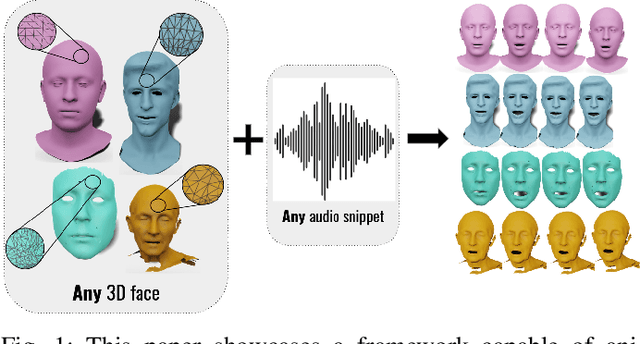
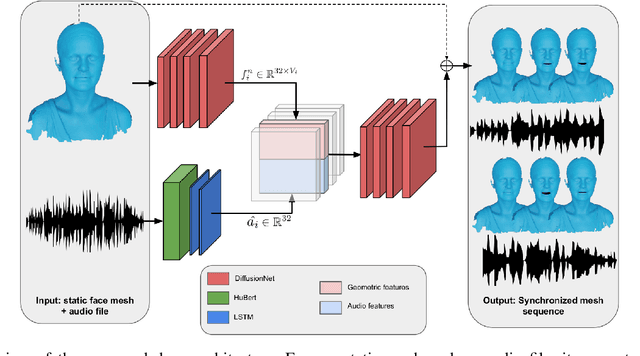
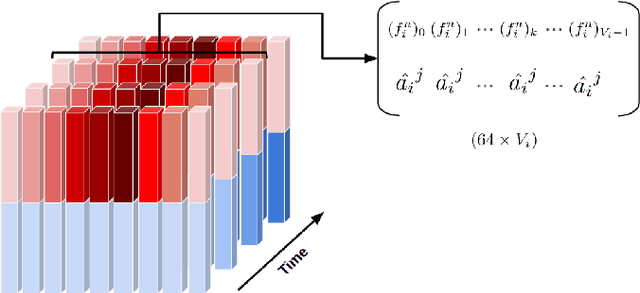

Generating speech-driven 3D talking heads presents numerous challenges; among those is dealing with varying mesh topologies. Existing methods require a registered setting, where all meshes share a common topology: a point-wise correspondence across all meshes the model can animate. While simplifying the problem, it limits applicability as unseen meshes must adhere to the training topology. This work presents a framework capable of animating 3D faces in arbitrary topologies, including real scanned data. Our approach relies on a model leveraging heat diffusion over meshes to overcome the fixed topology constraint. We explore two training settings: a supervised one, in which training sequences share a fixed topology within a sequence but any mesh can be animated at test time, and an unsupervised one, which allows effective training with varying mesh structures. Additionally, we highlight the limitations of current evaluation metrics and propose new metrics for better lip-syncing evaluation between speech and facial movements. Our extensive evaluation shows our approach performs favorably compared to fixed topology techniques, setting a new benchmark by offering a versatile and high-fidelity solution for 3D talking head generation.
EmoVOCA: Speech-Driven Emotional 3D Talking Heads
Mar 19, 2024



The domain of 3D talking head generation has witnessed significant progress in recent years. A notable challenge in this field consists in blending speech-related motions with expression dynamics, which is primarily caused by the lack of comprehensive 3D datasets that combine diversity in spoken sentences with a variety of facial expressions. Whereas literature works attempted to exploit 2D video data and parametric 3D models as a workaround, these still show limitations when jointly modeling the two motions. In this work, we address this problem from a different perspective, and propose an innovative data-driven technique that we used for creating a synthetic dataset, called EmoVOCA, obtained by combining a collection of inexpressive 3D talking heads and a set of 3D expressive sequences. To demonstrate the advantages of this approach, and the quality of the dataset, we then designed and trained an emotional 3D talking head generator that accepts a 3D face, an audio file, an emotion label, and an intensity value as inputs, and learns to animate the audio-synchronized lip movements with expressive traits of the face. Comprehensive experiments, both quantitative and qualitative, using our data and generator evidence superior ability in synthesizing convincing animations, when compared with the best performing methods in the literature. Our code and pre-trained model will be made available.
ScanTalk: 3D Talking Heads from Unregistered Scans
Mar 19, 2024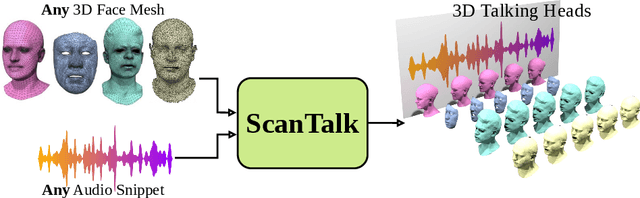

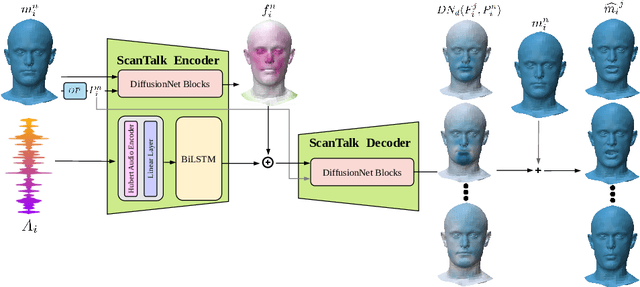

Speech-driven 3D talking heads generation has emerged as a significant area of interest among researchers, presenting numerous challenges. Existing methods are constrained by animating faces with fixed topologies, wherein point-wise correspondence is established, and the number and order of points remains consistent across all identities the model can animate. In this work, we present ScanTalk, a novel framework capable of animating 3D faces in arbitrary topologies including scanned data. Our approach relies on the DiffusionNet architecture to overcome the fixed topology constraint, offering promising avenues for more flexible and realistic 3D animations. By leveraging the power of DiffusionNet, ScanTalk not only adapts to diverse facial structures but also maintains fidelity when dealing with scanned data, thereby enhancing the authenticity and versatility of generated 3D talking heads. Through comprehensive comparisons with state-of-the-art methods, we validate the efficacy of our approach, demonstrating its capacity to generate realistic talking heads comparable to existing techniques. While our primary objective is to develop a generic method free from topological constraints, all state-of-the-art methodologies are bound by such limitations. Code for reproducing our results, and the pre-trained model will be made available.
Learning Landmarks Motion from Speech for Speaker-Agnostic 3D Talking Heads Generation
Jun 02, 2023



This paper presents a novel approach for generating 3D talking heads from raw audio inputs. Our method grounds on the idea that speech related movements can be comprehensively and efficiently described by the motion of a few control points located on the movable parts of the face, i.e., landmarks. The underlying musculoskeletal structure then allows us to learn how their motion influences the geometrical deformations of the whole face. The proposed method employs two distinct models to this aim: the first one learns to generate the motion of a sparse set of landmarks from the given audio. The second model expands such landmarks motion to a dense motion field, which is utilized to animate a given 3D mesh in neutral state. Additionally, we introduce a novel loss function, named Cosine Loss, which minimizes the angle between the generated motion vectors and the ground truth ones. Using landmarks in 3D talking head generation offers various advantages such as consistency, reliability, and obviating the need for manual-annotation. Our approach is designed to be identity-agnostic, enabling high-quality facial animations for any users without additional data or training.