 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Fixed Topologies: Unregistered Training and Comprehensive Evaluation Metrics for 3D Talking Heads
Paper and Code
Oct 14, 2024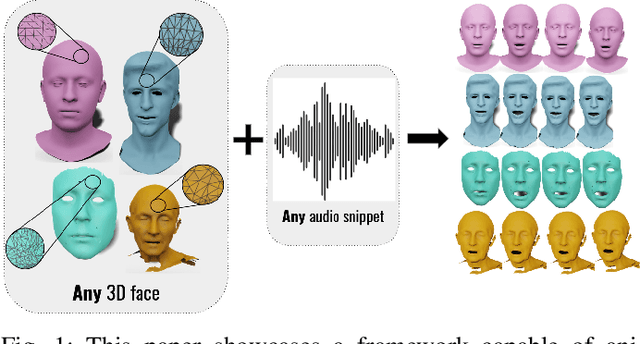
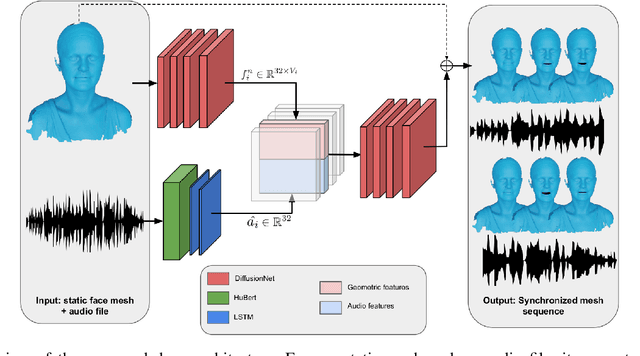
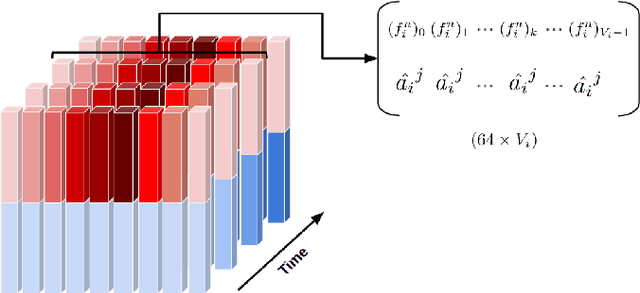

Generating speech-driven 3D talking heads presents numerous challenges; among those is dealing with varying mesh topologies. Existing methods require a registered setting, where all meshes share a common topology: a point-wise correspondence across all meshes the model can animate. While simplifying the problem, it limits applicability as unseen meshes must adhere to the training topology. This work presents a framework capable of animating 3D faces in arbitrary topologies, including real scanned data. Our approach relies on a model leveraging heat diffusion over meshes to overcome the fixed topology constraint. We explore two training settings: a supervised one, in which training sequences share a fixed topology within a sequence but any mesh can be animated at test time, and an unsupervised one, which allows effective training with varying mesh structures. Additionally, we highlight the limitations of current evaluation metrics and propose new metrics for better lip-syncing evaluation between speech and facial movements. Our extensive evaluation shows our approach performs favorably compared to fixed topology techniques, setting a new benchmark by offering a versatile and high-fidelity solution for 3D talking head generation.