 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Residual Errors in Compensation-based LLM Quantization
Apr 09, 2026Methods based on weight compensation, which iteratively apply quantization and weight compensation to minimize the output error, have recently demonstrated remarkable success in quantizing Large Language Models (LLMs). The representative work, GPTQ, introduces several key techniques that make such iterative methods practical for LLMs with billions of parameters. GPTAQ extends this approach by introducing an asymmetric calibration process that aligns the output of each quantized layer with its full-precision counterpart, incorporating a residual error into the weight compensation framework. In this work, we revisit the formulation of the residual error. We identify a sub-optimal calibration objective in existing methods: during the intra-layer calibration process, they align the quantized output with the output from compensated weights, rather than the true output from the original full-precision model. Therefore, we redefine the objective to precisely align the quantized model's output with the original output of the full-precision model at each step. We then reveal that the residual error originates not only from the output difference of the preceding layer but also from the discrepancy between the compensated and original weights within each layer, which we name the 'compensation-aware error'. By inheriting the neuron decomposition technique from GPTAQ, we can efficiently incorporate this compensation-aware error into the weight update process. Extensive experiments on various LLMs and quantization settings demonstrate that our proposed enhancements integrate seamlessly with both GPTQ and GPTAQ, significantly improving their quantization performance. Our code is publicly available at https://github.com/list0830/ResComp.
SSVQ: Unleashing the Potential of Vector Quantization with Sign-Splitting
Mar 11, 2025



Vector Quantization (VQ) has emerged as a prominent weight compression technique, showcasing substantially lower quantization errors than uniform quantization across diverse models, particularly in extreme compression scenarios. However, its efficacy during fine-tuning is limited by the constraint of the compression format, where weight vectors assigned to the same codeword are restricted to updates in the same direction. Consequently, many quantized weights are compelled to move in directions contrary to their local gradient information. To mitigate this issue, we introduce a novel VQ paradigm, Sign-Splitting VQ (SSVQ), which decouples the sign bit of weights from the codebook. Our approach involves extracting the sign bits of uncompressed weights and performing clustering and compression on all-positive weights. We then introduce latent variables for the sign bit and jointly optimize both the signs and the codebook. Additionally, we implement a progressive freezing strategy for the learnable sign to ensure training stability. Extensive experiments on various modern models and tasks demonstrate that SSVQ achieves a significantly superior compression-accuracy trade-off compared to conventional VQ. Furthermore, we validate our algorithm on a hardware accelerator, showing that SSVQ achieves a 3$\times$ speedup over the 8-bit compressed model by reducing memory access.
MVQ:Towards Efficient DNN Compression and Acceleration with Masked Vector Quantization
Dec 13, 2024



Vector quantization(VQ) is a hardware-friendly DNN compression method that can reduce the storage cost and weight-loading datawidth of hardware accelerators. However, conventional VQ techniques lead to significant accuracy loss because the important weights are not well preserved. To tackle this problem, a novel approach called MVQ is proposed, which aims at better approximating important weights with a limited number of codewords. At the algorithm level, our approach removes the less important weights through N:M pruning and then minimizes the vector clustering error between the remaining weights and codewords by the masked k-means algorithm. Only distances between the unpruned weights and the codewords are computed, which are then used to update the codewords. At the architecture level, our accelerator implements vector quantization on an EWS (Enhanced weight stationary) CNN accelerator and proposes a sparse systolic array design to maximize the benefits brought by masked vector quantization.\\ Our algorithm is validated on various models for image classification, object detection, and segmentation tasks. Experimental results demonstrate that MVQ not only outperforms conventional vector quantization methods at comparable compression ratios but also reduces FLOPs. Under ASIC evaluation, our MVQ accelerator boosts energy efficiency by 2.3$\times$ and reduces the size of the systolic array by 55\% when compared with the base EWS accelerator. Compared to the previous sparse accelerators, MVQ achieves 1.73$\times$ higher energy efficiency.
Efficiency Meets Fidelity: A Novel Quantization Framework for Stable Diffusion
Dec 09, 2024



Text-to-image generation of Stable Diffusion models has achieved notable success due to its remarkable generation ability. However, the repetitive denoising process is computationally intensive during inference, which renders Diffusion models less suitable for real-world applications that require low latency and scalability. Recent studies have employed post-training quantization (PTQ) and quantization-aware training (QAT) methods to compress Diffusion models. Nevertheless, prior research has often neglected to examine the consistency between results generated by quantized models and those from floating-point models. This consistency is crucial in fields such as content creation, design, and edge deployment, as it can significantly enhance both efficiency and system stability for practitioners. To ensure that quantized models generate high-quality and consistent images, we propose an efficient quantization framework for Stable Diffusion models. Our approach features a Serial-to-Parallel calibration pipeline that addresses the consistency of both the calibration and inference processes, as well as ensuring training stability. Based on this pipeline, we further introduce a mix-precision quantization strategy, multi-timestep activation quantization, and time information precalculation techniques to ensure high-fidelity generation in comparison to floating-point models. Through extensive experiments with Stable Diffusion v1-4, v2-1, and XL 1.0, we have demonstrated that our method outperforms the current state-of-the-art techniques when tested on prompts from the COCO validation dataset and the Stable-Diffusion-Prompts dataset. Under W4A8 quantization settings, our approach enhances both distribution similarity and visual similarity by 45%-60%.
Stepwise Weighted Spike Coding for Deep Spiking Neural Networks
Aug 30, 2024Spiking Neural Networks (SNNs) seek to mimic the spiking behavior of biological neurons and are expected to play a key role in the advancement of neural computing and artificial intelligence. The efficiency of SNNs is often determined by the neural coding schemes. Existing coding schemes either cause huge delays and energy consumption or necessitate intricate neuron models and training techniques. To address these issues, we propose a novel Stepwise Weighted Spike (SWS) coding scheme to enhance the encoding of information in spikes. This approach compresses the spikes by weighting the significance of the spike in each step of neural computation, achieving high performance and low energy consumption. A Ternary Self-Amplifying (TSA) neuron model with a silent period is proposed for supporting SWS-based computing, aimed at minimizing the residual error resulting from stepwise weighting in neural computation. Our experimental results show that the SWS coding scheme outperforms the existing neural coding schemes in very deep SNNs, and significantly reduces operations and latency.
Thermal Infrared Image Inpainting via Edge-Aware Guidance
Oct 28, 2022



Image inpainting has achieved fundamental advances with deep learning. However, almost all existing inpainting methods aim to process natural images, while few target Thermal Infrared (TIR) images, which have widespread applications. When applied to TIR images, conventional inpainting methods usually generate distorted or blurry content. In this paper, we propose a novel task -- Thermal Infrared Image Inpainting, which aims to reconstruct missing regions of TIR images. Crucially, we propose a novel deep-learning-based model TIR-Fill. We adopt the edge generator to complete the canny edges of broken TIR images. The completed edges are projected to the normalization weights and biases to enhance edge awareness of the model. In addition, a refinement network based on gated convolution is employed to improve TIR image consistency. The experiments demonstrate that our method outperforms state-of-the-art image inpainting approaches on FLIR thermal dataset.
FDA-GAN: Flow-based Dual Attention GAN for Human Pose Transfer
Dec 01, 2021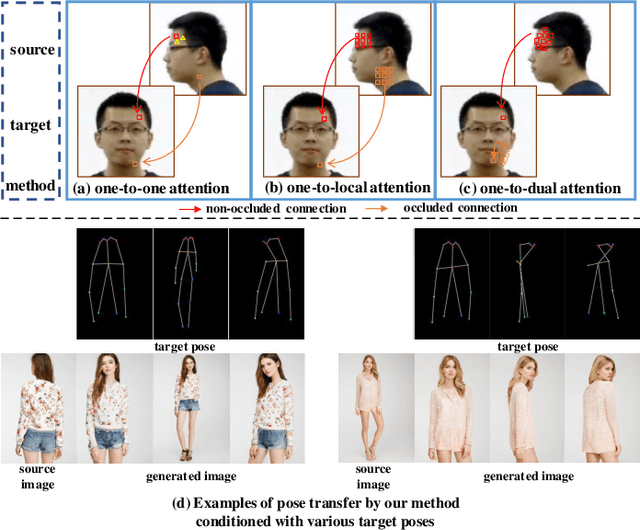


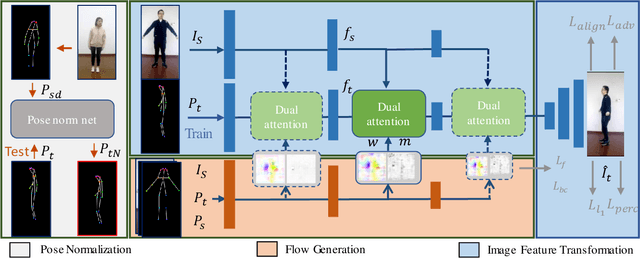
Human pose transfer aims at transferring the appearance of the source person to the target pose. Existing methods utilizing flow-based warping for non-rigid human image generation have achieved great success. However, they fail to preserve the appearance details in synthesized images since the spatial correlation between the source and target is not fully exploited. To this end, we propose the Flow-based Dual Attention GAN (FDA-GAN) to apply occlusion- and deformation-aware feature fusion for higher generation quality. Specifically, deformable local attention and flow similarity attention, constituting the dual attention mechanism, can derive the output features responsible for deformable- and occlusion-aware fusion, respectively. Besides, to maintain the pose and global position consistency in transferring, we design a pose normalization network for learning adaptive normalization from the target pose to the source person. Both qualitative and quantitative results show that our method outperforms state-of-the-art models in public iPER and DeepFashion datasets.
GLocal: Global Graph Reasoning and Local Structure Transfer for Person Image Generation
Dec 01, 2021
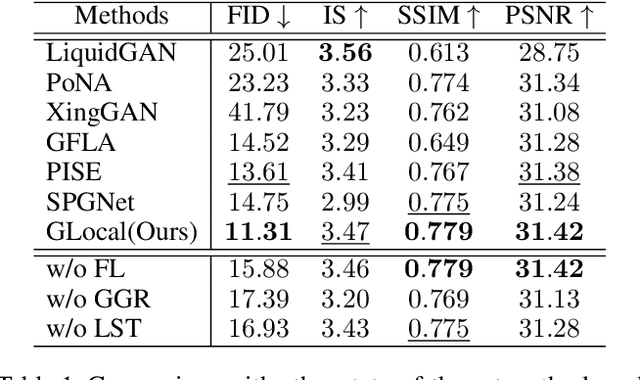
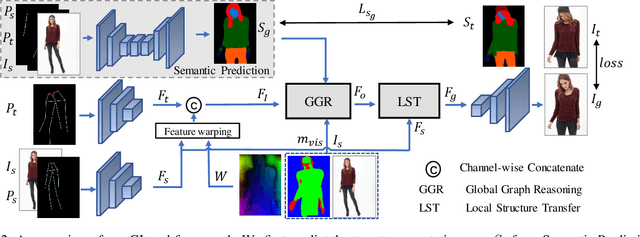
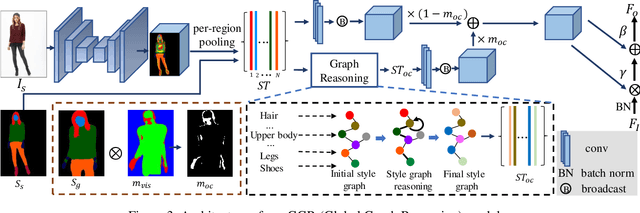
In this paper, we focus on person image generation, namely, generating person image under various conditions, e.g., corrupted texture or different pose. To address texture occlusion and large pose misalignment in this task, previous works just use the corresponding region's style to infer the occluded area and rely on point-wise alignment to reorganize the context texture information, lacking the ability to globally correlate the region-wise style codes and preserve the local structure of the source. To tackle these problems, we present a GLocal framework to improve the occlusion-aware texture estimation by globally reasoning the style inter-correlations among different semantic regions, which can also be employed to recover the corrupted images in texture inpainting. For local structural information preservation, we further extract the local structure of the source image and regain it in the generated image via local structure transfer. We benchmark our method to fully characterize its performance on DeepFashion dataset and present extensive ablation studies that highlight the novelty of our method.
An Ultra Fast Low Power Convolutional Neural Network Image Sensor with Pixel-level Computing
Jan 09, 2021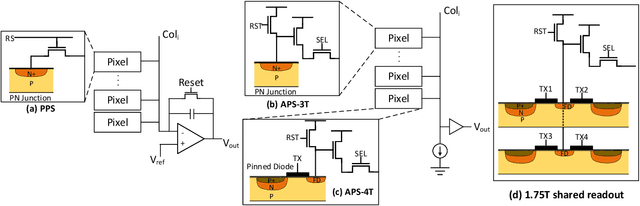
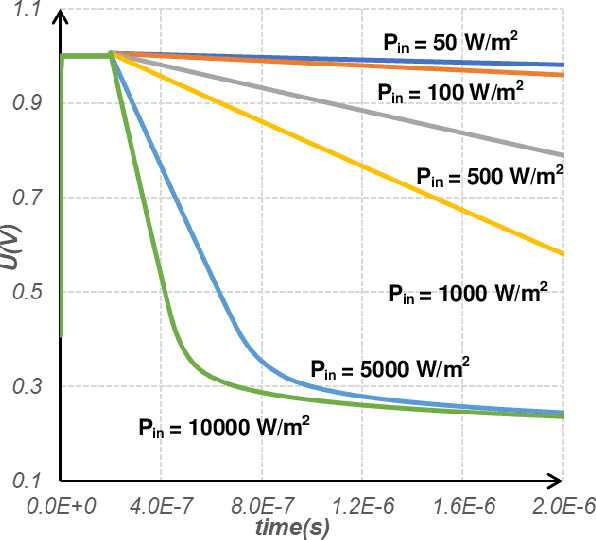
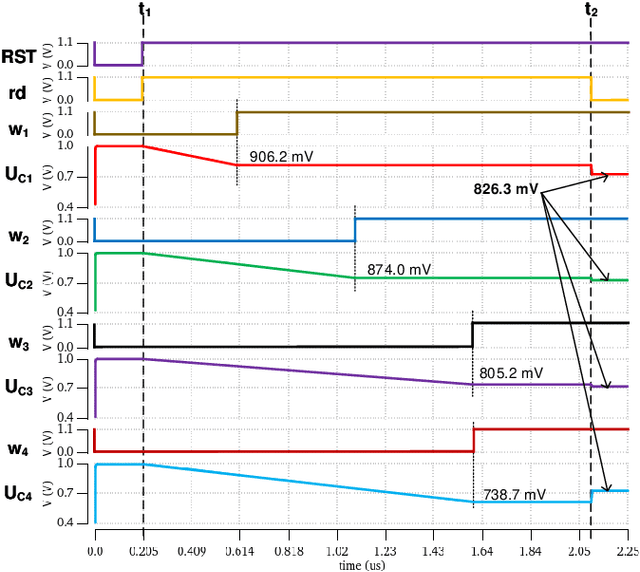
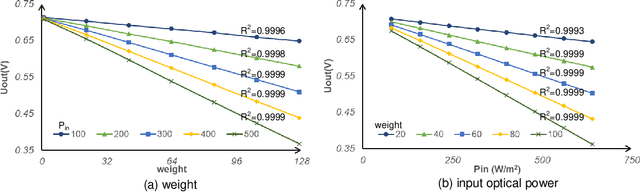
The separation of the data capture and analysis in modern vision systems has led to a massive amount of data transfer between the end devices and cloud computers, resulting in long latency, slow response, and high power consumption. Efficient hardware architectures are under focused development to enable Artificial Intelligence (AI) at the resource-limited end sensing devices. This paper proposes a Processing-In-Pixel (PIP) CMOS sensor architecture, which allows convolution operation before the column readout circuit to significantly improve the image reading speed with much lower power consumption. The simulation results show that the proposed architecture enables convolution operation (kernel size=3*3, stride=2, input channel=3, output channel=64) in a 1080P image sensor array with only 22.62 mW power consumption. In other words, the computational efficiency is 4.75 TOPS/w, which is about 3.6 times as higher as the state-of-the-art.
C2F-FWN: Coarse-to-Fine Flow Warping Network for Spatial-Temporal Consistent Motion Transfer
Dec 16, 2020
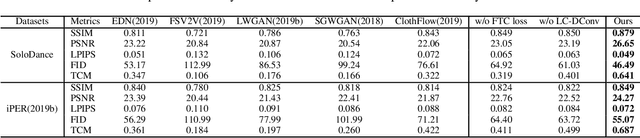
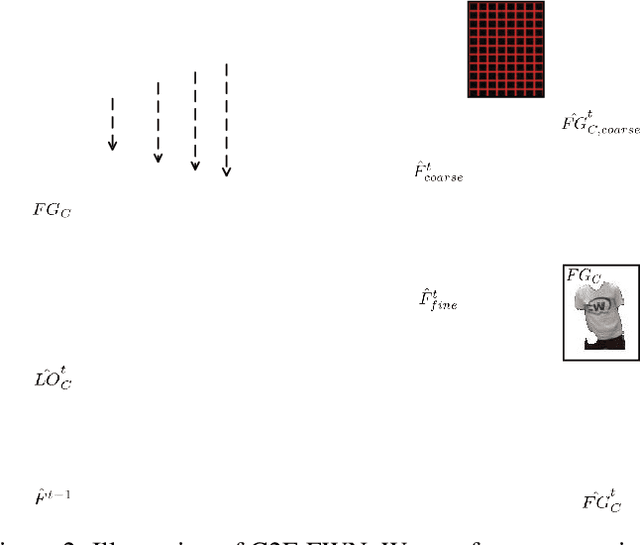
Human video motion transfer (HVMT) aims to synthesize videos that one person imitates other persons' actions. Although existing GAN-based HVMT methods have achieved great success, they either fail to preserve appearance details due to the loss of spatial consistency between synthesized and exemplary images, or generate incoherent video results due to the lack of temporal consistency among video frames. In this paper, we propose Coarse-to-Fine Flow Warping Network (C2F-FWN) for spatial-temporal consistent HVMT. Particularly, C2F-FWN utilizes coarse-to-fine flow warping and Layout-Constrained Deformable Convolution (LC-DConv) to improve spatial consistency, and employs Flow Temporal Consistency (FTC) Loss to enhance temporal consistency. In addition, provided with multi-source appearance inputs, C2F-FWN can support appearance attribute editing with great flexibility and efficiency. Besides public datasets, we also collected a large-scale HVMT dataset named SoloDance for evaluation. Extensive experiments conducted on our SoloDance dataset and the iPER dataset show that our approach outperforms state-of-art HVMT methods in terms of both spatial and temporal consistency. Source code and the SoloDance dataset are available at https://github.com/wswdx/C2F-FWN.