 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZeros can be Informative: Masked Binary U-Net for Image Segmentation on Tensor Cores
Jan 15, 2026Real-time image segmentation is a key enabler for AR/VR, robotics, drones, and autonomous systems, where tight accuracy, latency, and energy budgets must be met on resource-constrained edge devices. While U-Net offers a favorable balance of accuracy and efficiency compared to large transformer-based models, achieving real-time performance on high-resolution input remains challenging due to compute, memory, and power limits. Extreme quantization, particularly binary networks, is appealing for its hardware-friendly operations. However, two obstacles limit practicality: (1) severe accuracy degradation, and (2) a lack of end-to-end implementations that deliver efficiency on general-purpose GPUs. We make two empirical observations that guide our design. (1) An explicit zero state is essential: training with zero masking to binary U-Net weights yields noticeable sparsity. (2) Quantization sensitivity is uniform across layers. Motivated by these findings, we introduce Masked Binary U-Net (MBU-Net), obtained through a cost-aware masking strategy that prioritizes masking where it yields the highest accuracy-per-cost, reconciling accuracy with near-binary efficiency. To realize these gains in practice, we develop a GPU execution framework that maps MBU-Net to Tensor Cores via a subtractive bit-encoding scheme, efficiently implementing masked binary weights with binary activations. This design leverages native binary Tensor Core BMMA instructions, enabling high throughput and energy savings on widely available GPUs. Across 3 segmentation benchmarks, MBU-Net attains near full-precision accuracy (3% average drop) while delivering 2.04x speedup and 3.54x energy reductions over a 16-bit floating point U-Net.
An Ultra Fast Low Power Convolutional Neural Network Image Sensor with Pixel-level Computing
Jan 09, 2021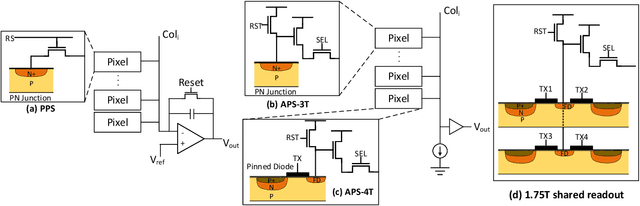
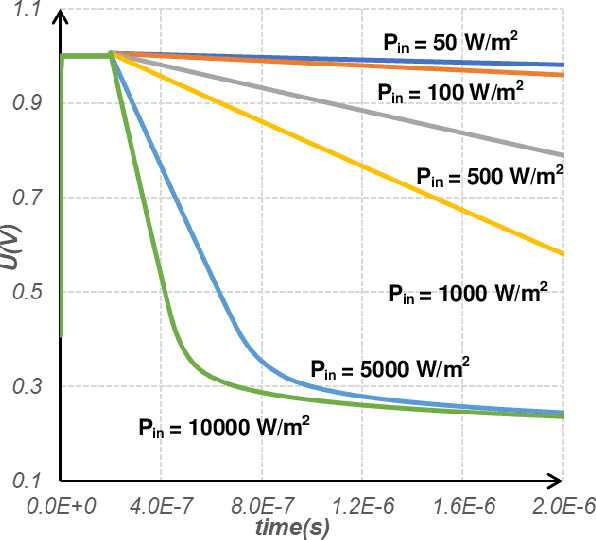
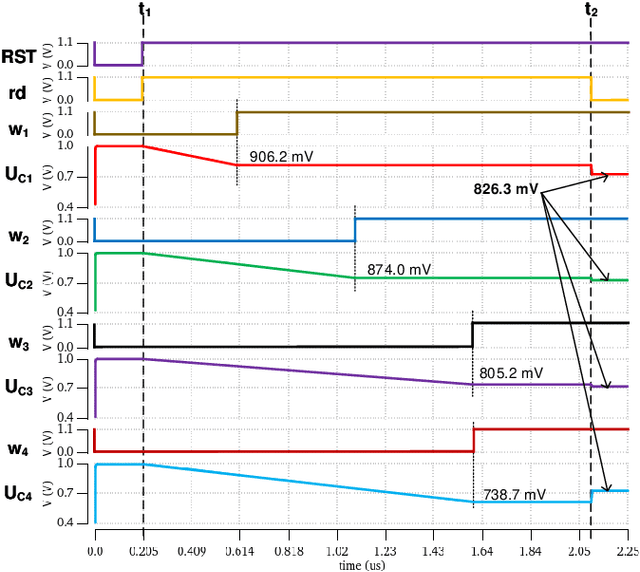
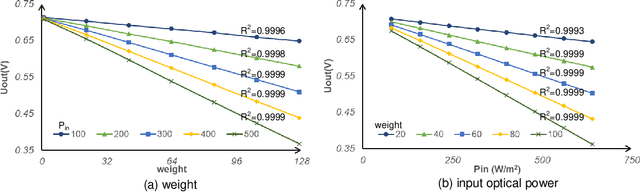
The separation of the data capture and analysis in modern vision systems has led to a massive amount of data transfer between the end devices and cloud computers, resulting in long latency, slow response, and high power consumption. Efficient hardware architectures are under focused development to enable Artificial Intelligence (AI) at the resource-limited end sensing devices. This paper proposes a Processing-In-Pixel (PIP) CMOS sensor architecture, which allows convolution operation before the column readout circuit to significantly improve the image reading speed with much lower power consumption. The simulation results show that the proposed architecture enables convolution operation (kernel size=3*3, stride=2, input channel=3, output channel=64) in a 1080P image sensor array with only 22.62 mW power consumption. In other words, the computational efficiency is 4.75 TOPS/w, which is about 3.6 times as higher as the state-of-the-art.