 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Ultra-Fast Cardiovascular Imaging Across Heterogeneous Clinical Environments with a Generalist Foundation Model and Multimodal Database
Dec 25, 2025Multimodal cardiovascular magnetic resonance (CMR) imaging provides comprehensive and non-invasive insights into cardiovascular disease (CVD) diagnosis and underlying mechanisms. Despite decades of advancements, its widespread clinical adoption remains constrained by prolonged scan times and heterogeneity across medical environments. This underscores the urgent need for a generalist reconstruction foundation model for ultra-fast CMR imaging, one capable of adapting across diverse imaging scenarios and serving as the essential substrate for all downstream analyses. To enable this goal, we curate MMCMR-427K, the largest and most comprehensive multimodal CMR k-space database to date, comprising 427,465 multi-coil k-space data paired with structured metadata across 13 international centers, 12 CMR modalities, 15 scanners, and 17 CVD categories in populations across three continents. Building on this unprecedented resource, we introduce CardioMM, a generalist reconstruction foundation model capable of dynamically adapting to heterogeneous fast CMR imaging scenarios. CardioMM unifies semantic contextual understanding with physics-informed data consistency to deliver robust reconstructions across varied scanners, protocols, and patient presentations. Comprehensive evaluations demonstrate that CardioMM achieves state-of-the-art performance in the internal centers and exhibits strong zero-shot generalization to unseen external settings. Even at imaging acceleration up to 24x, CardioMM reliably preserves key cardiac phenotypes, quantitative myocardial biomarkers, and diagnostic image quality, enabling a substantial increase in CMR examination throughput without compromising clinical integrity. Together, our open-access MMCMR-427K database and CardioMM framework establish a scalable pathway toward high-throughput, high-quality, and clinically accessible cardiovascular imaging.
Enhancing Relation Extraction via Supervised Rationale Verification and Feedback
Dec 10, 2024Despite the rapid progress that existing automated feedback methods have made in correcting the output of large language models (LLMs), these methods cannot be well applied to the relation extraction (RE) task due to their designated feedback objectives and correction manner. To address this problem, we propose a novel automated feedback framework for RE, which presents a rationale supervisor to verify the rationale and provide re-selected demonstrations as feedback to correct the initial prediction. Specifically, we first design a causal intervention and observation method for to collect biased/unbiased rationales for contrastive training the rationale supervisor. Then, we present a verification-feedback-correction procedure to iteratively enhance LLMs' capability of handling the RE task. Extensive experiments prove that our proposed framework significantly outperforms existing methods.
Unlock the Power of Frozen LLMs in Knowledge Graph Completion
Aug 13, 2024



Classical knowledge graph completion (KGC) methods rely solely on structural information, struggling with the inherent sparsity of knowledge graphs (KGs). Large Language Models (LLMs) learn extensive knowledge from large corpora with powerful context modeling, which is ideal for mitigating the limitations of previous methods. Directly fine-tuning LLMs offers great capability but comes at the cost of huge time and memory consumption, while utilizing frozen LLMs yields suboptimal results. In this work, we aim to leverage LLMs for KGC effectively and efficiently. We capture the context-aware hidden states of knowledge triples by employing prompts to stimulate the intermediate layers of LLMs. We then train a data-efficient classifier on these hidden states to harness the inherent capabilities of frozen LLMs in KGC. We also generate entity descriptions with subgraph sampling on KGs, reducing the ambiguity of triplets and enriching the knowledge representation. Extensive experiments on standard benchmarks showcase the efficiency and effectiveness of our approach. We outperform classical KGC methods on most datasets and match the performance of fine-tuned LLMs. Additionally, compared to fine-tuned LLMs, we boost GPU memory efficiency by \textbf{$188\times$} and speed up training+inference by \textbf{$13.48\times$}.
AceMap: Knowledge Discovery through Academic Graph
Mar 05, 2024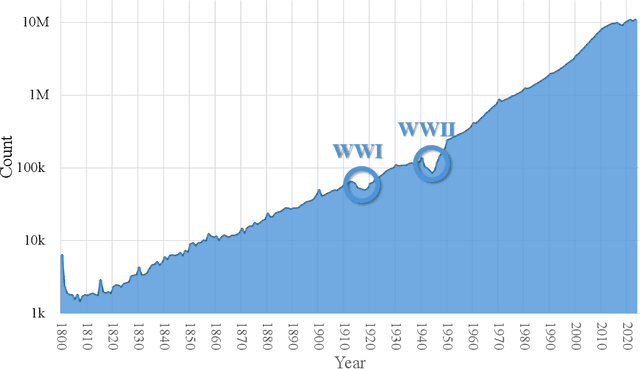
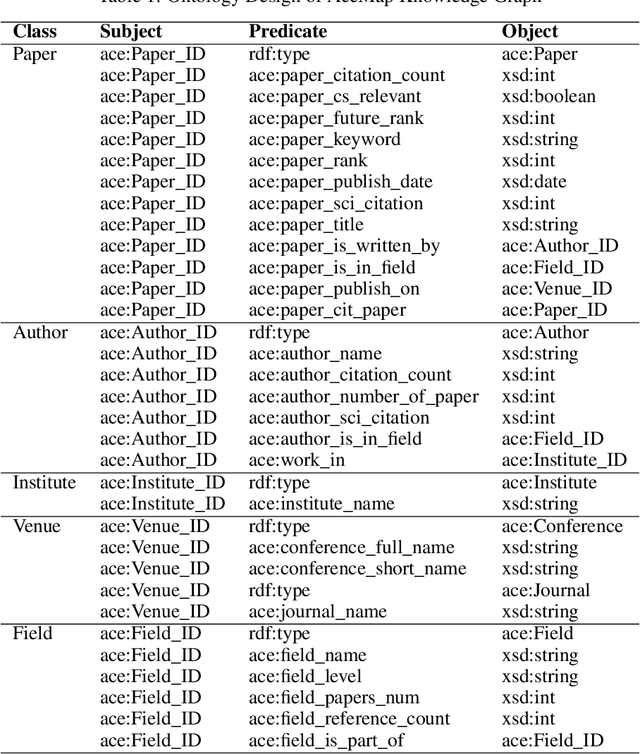
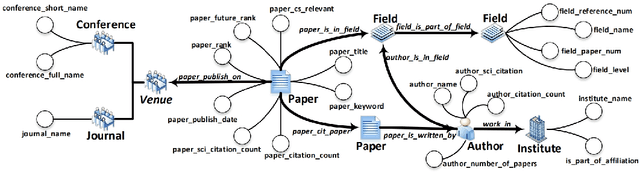
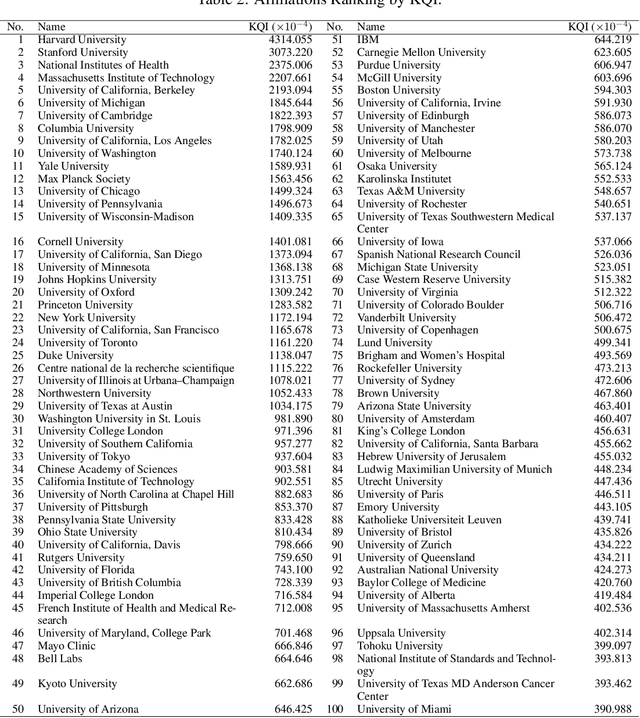
The exponential growth of scientific literature requires effective management and extraction of valuable insights. While existing scientific search engines excel at delivering search results based on relational databases, they often neglect the analysis of collaborations between scientific entities and the evolution of ideas, as well as the in-depth analysis of content within scientific publications. The representation of heterogeneous graphs and the effective measurement, analysis, and mining of such graphs pose significant challenges. To address these challenges, we present AceMap, an academic system designed for knowledge discovery through academic graph. We present advanced database construction techniques to build the comprehensive AceMap database with large-scale academic publications that contain rich visual, textual, and numerical information. AceMap also employs innovative visualization, quantification, and analysis methods to explore associations and logical relationships among academic entities. AceMap introduces large-scale academic network visualization techniques centered on nebular graphs, providing a comprehensive view of academic networks from multiple perspectives. In addition, AceMap proposes a unified metric based on structural entropy to quantitatively measure the knowledge content of different academic entities. Moreover, AceMap provides advanced analysis capabilities, including tracing the evolution of academic ideas through citation relationships and concept co-occurrence, and generating concise summaries informed by this evolutionary process. In addition, AceMap uses machine reading methods to generate potential new ideas at the intersection of different fields. Exploring the integration of large language models and knowledge graphs is a promising direction for future research in idea evolution. Please visit \url{https://www.acemap.info} for further exploration.
IdeaReader: A Machine Reading System for Understanding the Idea Flow of Scientific Publications
Sep 27, 2022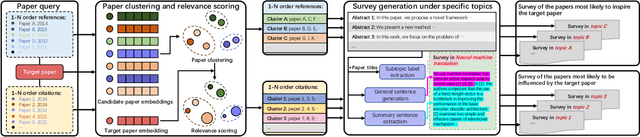
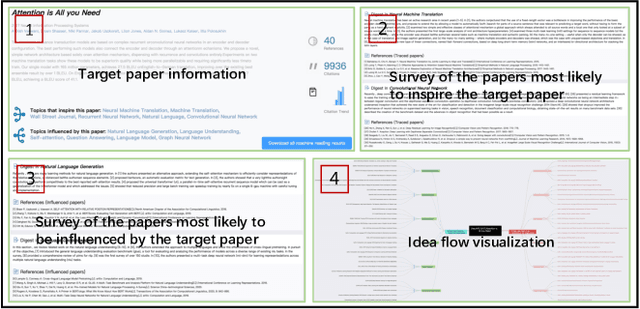
Understanding the origin and influence of the publication's idea is critical to conducting scientific research. However, the proliferation of scientific publications makes it difficult for researchers to sort out the evolution of all relevant literature. To this end, we present IdeaReader, a machine reading system that finds out which papers are most likely to inspire or be influenced by the target publication and summarizes the ideas of these papers in natural language. Specifically, IdeaReader first clusters the references and citations (first-order or higher-order) of the target publication, and the obtained clusters are regarded as the topics that inspire or are influenced by the target publication. It then picks out the important papers from each cluster to extract the skeleton of the idea flow. Finally, IdeaReader automatically generates a literature review of the important papers in each topic. Our system can help researchers gain insight into how scientific ideas flow from the target publication's references to citations by the automatically generated survey and the visualization of idea flow.
Disentangled Graph Contrastive Learning for Review-based Recommendation
Sep 04, 2022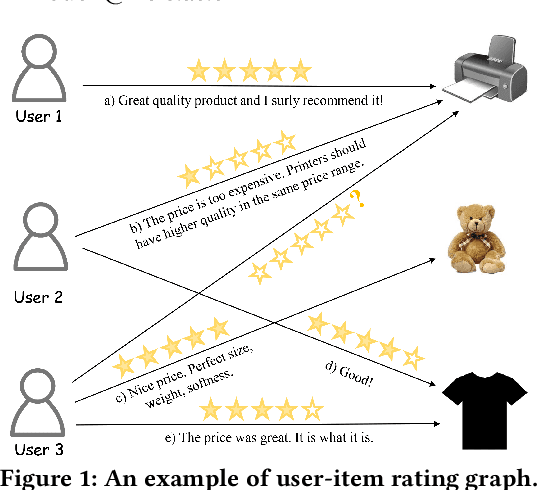
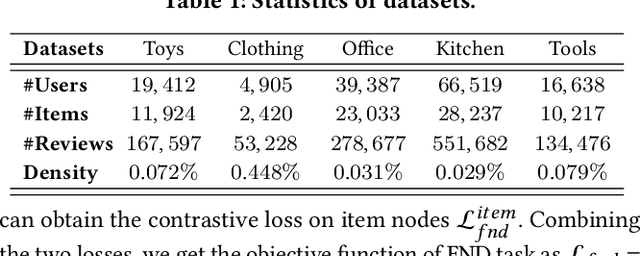
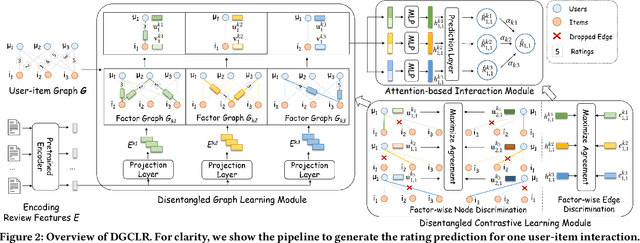
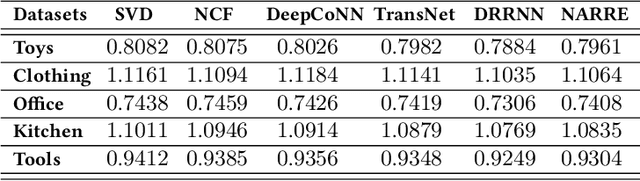
User review data is helpful in alleviating the data sparsity problem in many recommender systems. In review-based recommendation methods, review data is considered as auxiliary information that can improve the quality of learned user/item or interaction representations for the user rating prediction task. However, these methods usually model user-item interactions in a holistic manner and neglect the entanglement of the latent factors behind them, e.g., price, quality, or appearance, resulting in suboptimal representations and reducing interpretability. In this paper, we propose a Disentangled Graph Contrastive Learning framework for Review-based recommendation (DGCLR), to separately model the user-item interactions based on different latent factors through the textual review data. To this end, we first model the distributions of interactions over latent factors from both semantic information in review data and structural information in user-item graph data, forming several factor graphs. Then a factorized message passing mechanism is designed to learn disentangled user/item representations on the factor graphs, which enable us to further characterize the interactions and adaptively combine the predicted ratings from multiple factors via a devised attention mechanism. Finally, we set two factor-wise contrastive learning objectives to alleviate the sparsity issue and model the user/item and interaction features pertinent to each factor more accurately. Empirical results over five benchmark datasets validate the superiority of DGCLR over the state-of-the-art methods. Further analysis is offered to interpret the learned intent factors and rating prediction in DGCLR.