 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Compressive and Scalable Recurrent Memory
Feb 11, 2026Transformers face a quadratic bottleneck in attention when scaling to long contexts. Recent approaches introduce recurrent memory to extend context beyond the current window, yet these often face a fundamental trade-off between theoretical principles and practical scalability. To address this, we introduce Elastic Memory, a novel memory architecture grounded in the HiPPO framework for online function approximation. Elastic Memory treats historical sequence as samples from continuous signals, applying optimal online compression to encode them into a fixed-size memory state. For retrieval, we propose a flexible \textit{polynomial sampling} mechanism that reconstructs a history summary from this compressed state. Elastic Memory consistently outperformed baselines on long-context (32k+) datasets across three domains. With equal parameters, it beat Memorizing Transformer by 16x memory and outperformed Melodi at all memory sizes, even when Melodi had 30% more parameters. When scaling model size, Elastic Memory stayed ahead of all baselines and was significantly faster than Melodi at 4x size. Furthermore, its decoupled design allows for injecting inductive biases at test-time to boost performance.
Flow of Spans: Generalizing Language Models to Dynamic Span-Vocabulary via GFlowNets
Feb 11, 2026Standard autoregressive language models generate text token-by-token from a fixed vocabulary, inducing a tree-structured state space when viewing token sampling as an action, which limits flexibility and expressiveness. Recent work introduces dynamic vocabulary by sampling retrieved text spans but overlooks that the same sentence can be composed of spans of varying lengths, lacking explicit modeling of the directed acyclic graph (DAG) state space. This leads to restricted exploration of compositional paths and is biased toward the chosen path. Generative Flow Networks (GFlowNets) are powerful for efficient exploring and generalizing over state spaces, particularly those with a DAG structure. However, prior GFlowNets-based language models operate at the token level and remain confined to tree-structured spaces, limiting their potential. In this work, we propose Flow of SpanS (FOSS), a principled GFlowNets framework for span generation. FoSS constructs a dynamic span vocabulary by segmenting the retrieved text flexibly, ensuring a DAG-structured state space, which allows GFlowNets to explore diverse compositional paths and improve generalization. With specialized reward models, FoSS generates diverse, high-quality text. Empirically, FoSS improves MAUVE scores by up to 12.5% over Transformer on text generation and achieves 3.5% gains on knowledge-intensive tasks, consistently outperforming state-of-the-art methods. Scaling experiments further demonstrate FoSS benefits from larger models, more data, and richer retrieval corpora, retaining its advantage over strong baselines.
Next Concept Prediction in Discrete Latent Space Leads to Stronger Language Models
Feb 09, 2026We propose Next Concept Prediction (NCP), a generative pretraining paradigm built on top of Next Token Prediction (NTP). NCP predicts discrete concepts that span multiple tokens, thereby forming a more challenging pretraining objective. Our model, ConceptLM, quantizes hidden states using Vector Quantization and constructs a concept vocabulary. It leverages both NCP and NTP to drive parameter updates and generates a concept to guide the generation of the following tokens. We train ConceptLM from scratch at scales ranging from 70M to 1.5B parameters with up to 300B training data, including Pythia and GPT-2 backbones. Results on 13 benchmarks show that NCP yields consistent performance gains over traditional token-level models. Furthermore, continual pretraining experiments on an 8B-parameter Llama model indicate that NCP can further improve an NTP-trained model. Our analysis suggests that NCP leads to more powerful language models by introducing a harder pretraining task, providing a promising path toward better language modeling.
Controlling Exploration-Exploitation in GFlowNets via Markov Chain Perspectives
Feb 03, 2026Generative Flow Network (GFlowNet) objectives implicitly fix an equal mixing of forward and backward policies, potentially constraining the exploration-exploitation trade-off during training. By further exploring the link between GFlowNets and Markov chains, we establish an equivalence between GFlowNet objectives and Markov chain reversibility, thereby revealing the origin of such constraints, and provide a framework for adapting Markov chain properties to GFlowNets. Building on these theoretical findings, we propose $α$-GFNs, which generalize the mixing via a tunable parameter $α$. This generalization enables direct control over exploration-exploitation dynamics to enhance mode discovery capabilities, while ensuring convergence to unique flows. Across various benchmarks, including Set, Bit Sequence, and Molecule Generation, $α$-GFN objectives consistently outperform previous GFlowNet objectives, achieving up to a $10 \times$ increase in the number of discovered modes.
FlowRL: Matching Reward Distributions for LLM Reasoning
Sep 18, 2025We propose FlowRL: matching the full reward distribution via flow balancing instead of maximizing rewards in large language model (LLM) reinforcement learning (RL). Recent advanced reasoning models adopt reward-maximizing methods (\eg, PPO and GRPO), which tend to over-optimize dominant reward signals while neglecting less frequent but valid reasoning paths, thus reducing diversity. In contrast, we transform scalar rewards into a normalized target distribution using a learnable partition function, and then minimize the reverse KL divergence between the policy and the target distribution. We implement this idea as a flow-balanced optimization method that promotes diverse exploration and generalizable reasoning trajectories. We conduct experiments on math and code reasoning tasks: FlowRL achieves a significant average improvement of $10.0\%$ over GRPO and $5.1\%$ over PPO on math benchmarks, and performs consistently better on code reasoning tasks. These results highlight reward distribution-matching as a key step toward efficient exploration and diverse reasoning in LLM reinforcement learning.
Cluster-wise Graph Transformer with Dual-granularity Kernelized Attention
Oct 09, 2024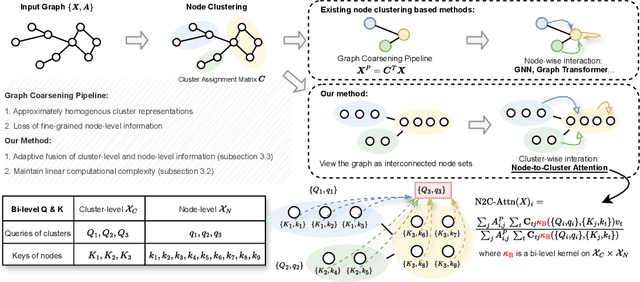
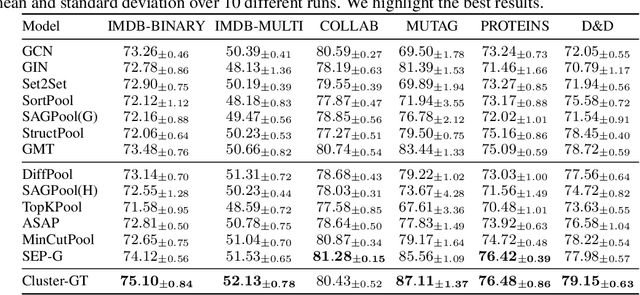
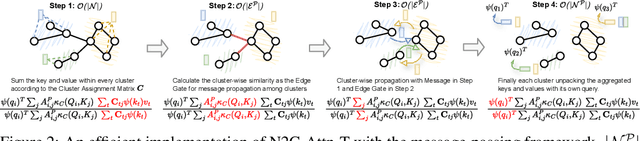
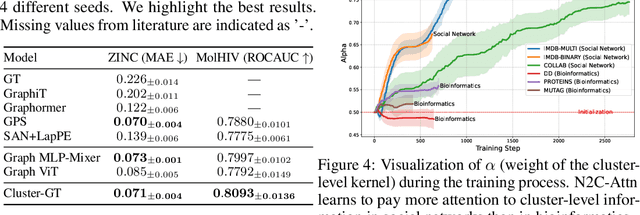
In the realm of graph learning, there is a category of methods that conceptualize graphs as hierarchical structures, utilizing node clustering to capture broader structural information. While generally effective, these methods often rely on a fixed graph coarsening routine, leading to overly homogeneous cluster representations and loss of node-level information. In this paper, we envision the graph as a network of interconnected node sets without compressing each cluster into a single embedding. To enable effective information transfer among these node sets, we propose the Node-to-Cluster Attention (N2C-Attn) mechanism. N2C-Attn incorporates techniques from Multiple Kernel Learning into the kernelized attention framework, effectively capturing information at both node and cluster levels. We then devise an efficient form for N2C-Attn using the cluster-wise message-passing framework, achieving linear time complexity. We further analyze how N2C-Attn combines bi-level feature maps of queries and keys, demonstrating its capability to merge dual-granularity information. The resulting architecture, Cluster-wise Graph Transformer (Cluster-GT), which uses node clusters as tokens and employs our proposed N2C-Attn module, shows superior performance on various graph-level tasks. Code is available at https://github.com/LUMIA-Group/Cluster-wise-Graph-Transformer.
Unlock the Power of Frozen LLMs in Knowledge Graph Completion
Aug 13, 2024



Classical knowledge graph completion (KGC) methods rely solely on structural information, struggling with the inherent sparsity of knowledge graphs (KGs). Large Language Models (LLMs) learn extensive knowledge from large corpora with powerful context modeling, which is ideal for mitigating the limitations of previous methods. Directly fine-tuning LLMs offers great capability but comes at the cost of huge time and memory consumption, while utilizing frozen LLMs yields suboptimal results. In this work, we aim to leverage LLMs for KGC effectively and efficiently. We capture the context-aware hidden states of knowledge triples by employing prompts to stimulate the intermediate layers of LLMs. We then train a data-efficient classifier on these hidden states to harness the inherent capabilities of frozen LLMs in KGC. We also generate entity descriptions with subgraph sampling on KGs, reducing the ambiguity of triplets and enriching the knowledge representation. Extensive experiments on standard benchmarks showcase the efficiency and effectiveness of our approach. We outperform classical KGC methods on most datasets and match the performance of fine-tuned LLMs. Additionally, compared to fine-tuned LLMs, we boost GPU memory efficiency by \textbf{$188\times$} and speed up training+inference by \textbf{$13.48\times$}.
Graph Parsing Networks
Feb 22, 2024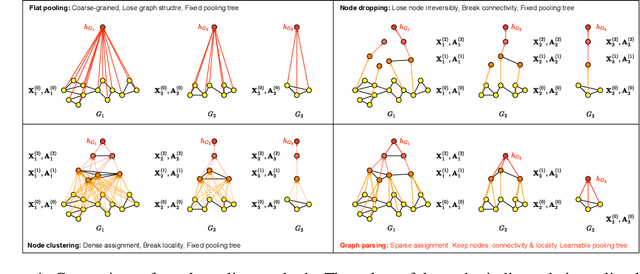


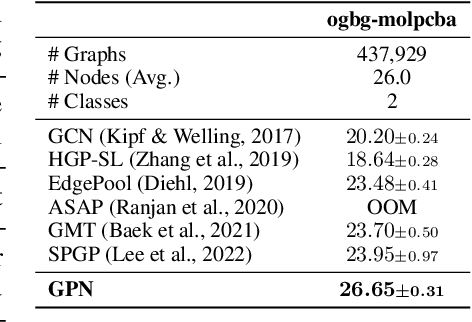
Graph pooling compresses graph information into a compact representation. State-of-the-art graph pooling methods follow a hierarchical approach, which reduces the graph size step-by-step. These methods must balance memory efficiency with preserving node information, depending on whether they use node dropping or node clustering. Additionally, fixed pooling ratios or numbers of pooling layers are predefined for all graphs, which prevents personalized pooling structures from being captured for each individual graph. In this work, inspired by bottom-up grammar induction, we propose an efficient graph parsing algorithm to infer the pooling structure, which then drives graph pooling. The resulting Graph Parsing Network (GPN) adaptively learns personalized pooling structure for each individual graph. GPN benefits from the discrete assignments generated by the graph parsing algorithm, allowing good memory efficiency while preserving node information intact. Experimental results on standard benchmarks demonstrate that GPN outperforms state-of-the-art graph pooling methods in graph classification tasks while being able to achieve competitive performance in node classification tasks. We also conduct a graph reconstruction task to show GPN's ability to preserve node information and measure both memory and time efficiency through relevant tests.
GeoGalactica: A Scientific Large Language Model in Geoscience
Dec 31, 2023

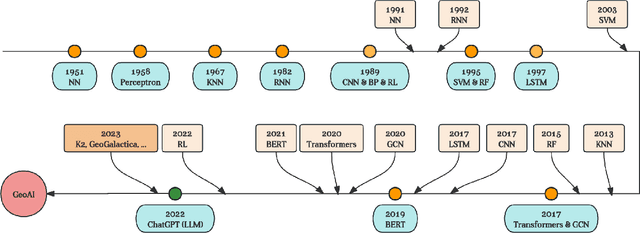
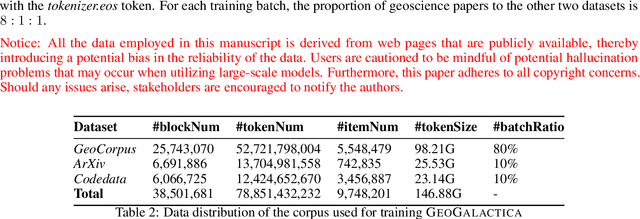
Large language models (LLMs) have achieved huge success for their general knowledge and ability to solve a wide spectrum of tasks in natural language processing (NLP). Due to their impressive abilities, LLMs have shed light on potential inter-discipline applications to foster scientific discoveries of a specific domain by using artificial intelligence (AI for science, AI4S). In the meantime, utilizing NLP techniques in geoscience research and practice is wide and convoluted, contributing from knowledge extraction and document classification to question answering and knowledge discovery. In this work, we take the initial step to leverage LLM for science, through a rather straightforward approach. We try to specialize an LLM into geoscience, by further pre-training the model with a vast amount of texts in geoscience, as well as supervised fine-tuning (SFT) the resulting model with our custom collected instruction tuning dataset. These efforts result in a model GeoGalactica consisting of 30 billion parameters. To our best knowledge, it is the largest language model for the geoscience domain. More specifically, GeoGalactica is from further pre-training of Galactica. We train GeoGalactica over a geoscience-related text corpus containing 65 billion tokens curated from extensive data sources in the big science project Deep-time Digital Earth (DDE), preserving as the largest geoscience-specific text corpus. Then we fine-tune the model with 1 million pairs of instruction-tuning data consisting of questions that demand professional geoscience knowledge to answer. In this technical report, we will illustrate in detail all aspects of GeoGalactica, including data collection, data cleaning, base model selection, pre-training, SFT, and evaluation. We open-source our data curation tools and the checkpoints of GeoGalactica during the first 3/4 of pre-training.
Tailoring Self-Attention for Graph via Rooted Subtrees
Oct 08, 2023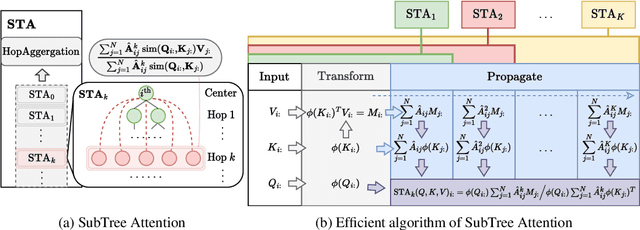
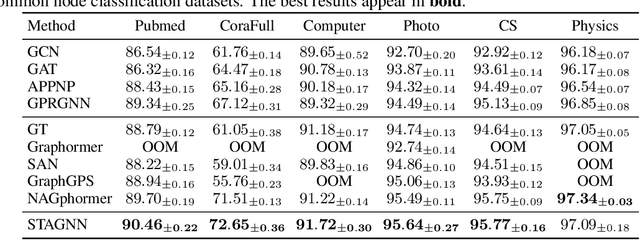


Attention mechanisms have made significant strides in graph learning, yet they still exhibit notable limitations: local attention faces challenges in capturing long-range information due to the inherent problems of the message-passing scheme, while global attention cannot reflect the hierarchical neighborhood structure and fails to capture fine-grained local information. In this paper, we propose a novel multi-hop graph attention mechanism, named Subtree Attention (STA), to address the aforementioned issues. STA seamlessly bridges the fully-attentional structure and the rooted subtree, with theoretical proof that STA approximates the global attention under extreme settings. By allowing direct computation of attention weights among multi-hop neighbors, STA mitigates the inherent problems in existing graph attention mechanisms. Further we devise an efficient form for STA by employing kernelized softmax, which yields a linear time complexity. Our resulting GNN architecture, the STAGNN, presents a simple yet performant STA-based graph neural network leveraging a hop-aware attention strategy. Comprehensive evaluations on ten node classification datasets demonstrate that STA-based models outperform existing graph transformers and mainstream GNNs. The code is available at https://github.com/LUMIA-Group/SubTree-Attention.