 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRADAR: Reasoning as Discrimination with Aligned Representations for LLM-based Knowledge Graph Reasoning
Feb 25, 2026Knowledge graph reasoning (KGR) infers missing facts, with recent advances increasingly harnessing the semantic priors and reasoning abilities of Large Language Models (LLMs). However, prevailing generative paradigms are prone to memorizing surface-level co-occurrences rather than learning genuine relational semantics, limiting out-of-distribution generalization. To address this, we propose RADAR, which reformulates KGR from generative pattern matching to discriminative relational reasoning. We recast KGR as discriminative entity selection, where reinforcement learning enforces relative entity separability beyond token-likelihood imitation. Leveraging this separability, inference operates directly in representation space, ensuring consistency with the discriminative optimization and bypassing generation-induced hallucinations. Across four benchmarks, RADAR achieves 5-6% relative gains on link prediction and triple classification over strong LLM baselines, while increasing task-relevant mutual information in intermediate representations by 62.9%, indicating more robust and transferable relational reasoning.
Flow of Spans: Generalizing Language Models to Dynamic Span-Vocabulary via GFlowNets
Feb 11, 2026Standard autoregressive language models generate text token-by-token from a fixed vocabulary, inducing a tree-structured state space when viewing token sampling as an action, which limits flexibility and expressiveness. Recent work introduces dynamic vocabulary by sampling retrieved text spans but overlooks that the same sentence can be composed of spans of varying lengths, lacking explicit modeling of the directed acyclic graph (DAG) state space. This leads to restricted exploration of compositional paths and is biased toward the chosen path. Generative Flow Networks (GFlowNets) are powerful for efficient exploring and generalizing over state spaces, particularly those with a DAG structure. However, prior GFlowNets-based language models operate at the token level and remain confined to tree-structured spaces, limiting their potential. In this work, we propose Flow of SpanS (FOSS), a principled GFlowNets framework for span generation. FoSS constructs a dynamic span vocabulary by segmenting the retrieved text flexibly, ensuring a DAG-structured state space, which allows GFlowNets to explore diverse compositional paths and improve generalization. With specialized reward models, FoSS generates diverse, high-quality text. Empirically, FoSS improves MAUVE scores by up to 12.5% over Transformer on text generation and achieves 3.5% gains on knowledge-intensive tasks, consistently outperforming state-of-the-art methods. Scaling experiments further demonstrate FoSS benefits from larger models, more data, and richer retrieval corpora, retaining its advantage over strong baselines.
Improved Approximate Regret for Decentralized Online Continuous Submodular Maximization via Reductions
Feb 10, 2026To expand the applicability of decentralized online learning, previous studies have proposed several algorithms for decentralized online continuous submodular maximization (D-OCSM) -- a non-convex/non-concave setting with continuous DR-submodular reward functions. However, there exist large gaps between their approximate regret bounds and the regret bounds achieved in the convex setting. Moreover, if focusing on projection-free algorithms, which can efficiently handle complex decision sets, they cannot even recover the approximate regret bounds achieved in the centralized setting. In this paper, we first demonstrate that for D-OCSM over general convex decision sets, these two issues can be addressed simultaneously. Furthermore, for D-OCSM over downward-closed decision sets, we show that the second issue can be addressed while significantly alleviating the first issue. Our key techniques are two reductions from D-OCSM to decentralized online convex optimization (D-OCO), which can exploit D-OCO algorithms to improve the approximate regret of D-OCSM in these two cases, respectively.
Controlling Exploration-Exploitation in GFlowNets via Markov Chain Perspectives
Feb 03, 2026Generative Flow Network (GFlowNet) objectives implicitly fix an equal mixing of forward and backward policies, potentially constraining the exploration-exploitation trade-off during training. By further exploring the link between GFlowNets and Markov chains, we establish an equivalence between GFlowNet objectives and Markov chain reversibility, thereby revealing the origin of such constraints, and provide a framework for adapting Markov chain properties to GFlowNets. Building on these theoretical findings, we propose $α$-GFNs, which generalize the mixing via a tunable parameter $α$. This generalization enables direct control over exploration-exploitation dynamics to enhance mode discovery capabilities, while ensuring convergence to unique flows. Across various benchmarks, including Set, Bit Sequence, and Molecule Generation, $α$-GFN objectives consistently outperform previous GFlowNet objectives, achieving up to a $10 \times$ increase in the number of discovered modes.
Consistency Is Not Always Correct: Towards Understanding the Role of Exploration in Post-Training Reasoning
Nov 10, 2025Foundation models exhibit broad knowledge but limited task-specific reasoning, motivating post-training strategies such as RLVR and inference scaling with outcome or process reward models (ORM/PRM). While recent work highlights the role of exploration and entropy stability in improving pass@K, empirical evidence points to a paradox: RLVR and ORM/PRM typically reinforce existing tree-like reasoning paths rather than expanding the reasoning scope, raising the question of why exploration helps at all if no new patterns emerge. To reconcile this paradox, we adopt the perspective of Kim et al. (2025), viewing easy (e.g., simplifying a fraction) versus hard (e.g., discovering a symmetry) reasoning steps as low- versus high-probability Markov transitions, and formalize post-training dynamics through Multi-task Tree-structured Markov Chains (TMC). In this tractable model, pretraining corresponds to tree expansion, while post-training corresponds to chain-of-thought reweighting. We show that several phenomena recently observed in empirical studies arise naturally in this setting: (1) RLVR induces a squeezing effect, reducing reasoning entropy and forgetting some correct paths; (2) population rewards of ORM/PRM encourage consistency rather than accuracy, thereby favoring common patterns; and (3) certain rare, high-uncertainty reasoning paths by the base model are responsible for solving hard problem instances. Together, these explain why exploration -- even when confined to the base model's reasoning scope -- remains essential: it preserves access to rare but crucial reasoning traces needed for difficult cases, which are squeezed out by RLVR or unfavored by inference scaling. Building on this, we further show that exploration strategies such as rejecting easy instances and KL regularization help preserve rare reasoning traces. Empirical simulations corroborate our theoretical results.
Beyond the Lower Bound: Bridging Regret Minimization and Best Arm Identification in Lexicographic Bandits
Nov 08, 2025In multi-objective decision-making with hierarchical preferences, lexicographic bandits provide a natural framework for optimizing multiple objectives in a prioritized order. In this setting, a learner repeatedly selects arms and observes reward vectors, aiming to maximize the reward for the highest-priority objective, then the next, and so on. While previous studies have primarily focused on regret minimization, this work bridges the gap between \textit{regret minimization} and \textit{best arm identification} under lexicographic preferences. We propose two elimination-based algorithms to address this joint objective. The first algorithm eliminates suboptimal arms sequentially, layer by layer, in accordance with the objective priorities, and achieves sample complexity and regret bounds comparable to those of the best single-objective algorithms. The second algorithm simultaneously leverages reward information from all objectives in each round, effectively exploiting cross-objective dependencies. Remarkably, it outperforms the known lower bound for the single-objective bandit problem, highlighting the benefit of cross-objective information sharing in the multi-objective setting. Empirical results further validate their superior performance over baselines.
Parametric Pareto Set Learning for Expensive Multi-Objective Optimization
Nov 08, 2025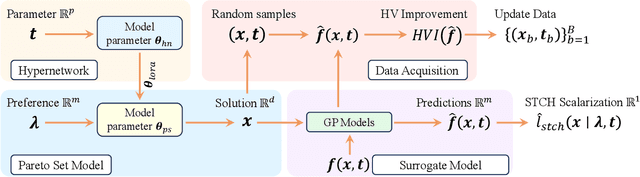
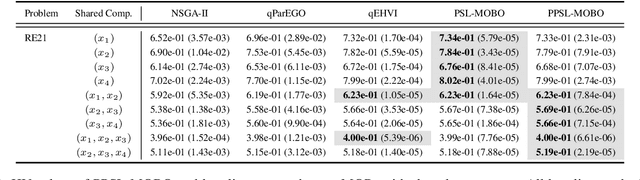
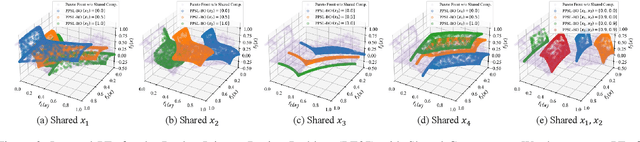
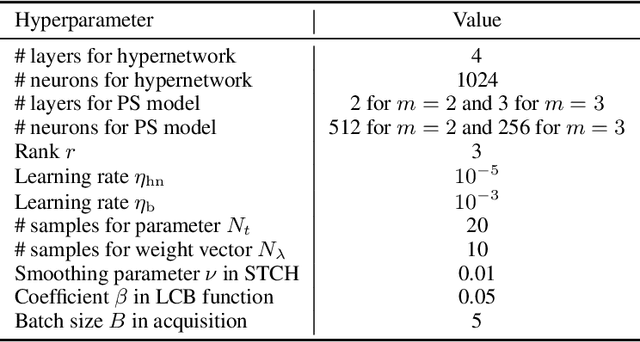
Parametric multi-objective optimization (PMO) addresses the challenge of solving an infinite family of multi-objective optimization problems, where optimal solutions must adapt to varying parameters. Traditional methods require re-execution for each parameter configuration, leading to prohibitive costs when objective evaluations are computationally expensive. To address this issue, we propose Parametric Pareto Set Learning with multi-objective Bayesian Optimization (PPSL-MOBO), a novel framework that learns a unified mapping from both preferences and parameters to Pareto-optimal solutions. PPSL-MOBO leverages a hypernetwork with Low-Rank Adaptation (LoRA) to efficiently capture parametric variations, while integrating Gaussian process surrogates and hypervolume-based acquisition to minimize expensive function evaluations. We demonstrate PPSL-MOBO's effectiveness on two challenging applications: multi-objective optimization with shared components, where certain design variables must be identical across solution families due to modular constraints, and dynamic multi-objective optimization, where objectives evolve over time. Unlike existing methods that cannot directly solve PMO problems in a unified manner, PPSL-MOBO learns a single model that generalizes across the entire parameter space. By enabling instant inference of Pareto sets for new parameter values without retraining, PPSL-MOBO provides an efficient solution for expensive PMO problems.
FlowRL: Matching Reward Distributions for LLM Reasoning
Sep 18, 2025We propose FlowRL: matching the full reward distribution via flow balancing instead of maximizing rewards in large language model (LLM) reinforcement learning (RL). Recent advanced reasoning models adopt reward-maximizing methods (\eg, PPO and GRPO), which tend to over-optimize dominant reward signals while neglecting less frequent but valid reasoning paths, thus reducing diversity. In contrast, we transform scalar rewards into a normalized target distribution using a learnable partition function, and then minimize the reverse KL divergence between the policy and the target distribution. We implement this idea as a flow-balanced optimization method that promotes diverse exploration and generalizable reasoning trajectories. We conduct experiments on math and code reasoning tasks: FlowRL achieves a significant average improvement of $10.0\%$ over GRPO and $5.1\%$ over PPO on math benchmarks, and performs consistently better on code reasoning tasks. These results highlight reward distribution-matching as a key step toward efficient exploration and diverse reasoning in LLM reinforcement learning.
AceParse: A Comprehensive Dataset with Diverse Structured Texts for Academic Literature Parsing
Sep 16, 2024With the development of data-centric AI, the focus has shifted from model-driven approaches to improving data quality. Academic literature, as one of the crucial types, is predominantly stored in PDF formats and needs to be parsed into texts before further processing. However, parsing diverse structured texts in academic literature remains challenging due to the lack of datasets that cover various text structures. In this paper, we introduce AceParse, the first comprehensive dataset designed to support the parsing of a wide range of structured texts, including formulas, tables, lists, algorithms, and sentences with embedded mathematical expressions. Based on AceParse, we fine-tuned a multimodal model, named AceParser, which accurately parses various structured texts within academic literature. This model outperforms the previous state-of-the-art by 4.1% in terms of F1 score and by 5% in Jaccard Similarity, demonstrating the potential of multimodal models in academic literature parsing. Our dataset is available at https://github.com/JHW5981/AceParse.
Unlock the Power of Frozen LLMs in Knowledge Graph Completion
Aug 13, 2024



Classical knowledge graph completion (KGC) methods rely solely on structural information, struggling with the inherent sparsity of knowledge graphs (KGs). Large Language Models (LLMs) learn extensive knowledge from large corpora with powerful context modeling, which is ideal for mitigating the limitations of previous methods. Directly fine-tuning LLMs offers great capability but comes at the cost of huge time and memory consumption, while utilizing frozen LLMs yields suboptimal results. In this work, we aim to leverage LLMs for KGC effectively and efficiently. We capture the context-aware hidden states of knowledge triples by employing prompts to stimulate the intermediate layers of LLMs. We then train a data-efficient classifier on these hidden states to harness the inherent capabilities of frozen LLMs in KGC. We also generate entity descriptions with subgraph sampling on KGs, reducing the ambiguity of triplets and enriching the knowledge representation. Extensive experiments on standard benchmarks showcase the efficiency and effectiveness of our approach. We outperform classical KGC methods on most datasets and match the performance of fine-tuned LLMs. Additionally, compared to fine-tuned LLMs, we boost GPU memory efficiency by \textbf{$188\times$} and speed up training+inference by \textbf{$13.48\times$}.