 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Modal Isolation in Interleaved Thinking: Supervising Modality Transitions via Stepwise Reinforcement
Jun 11, 2026Interleaved thinking, where a unified multimodal model alternates between textual reasoning and visual generation, has shown promise on spatial and physical tasks. However, in complex long-chain scenarios, we identify a fundamental failure mode: generated images diverge from the textual context while subsequent text ignores the visual evidence, causing the two modalities to alternate without genuinely informing each other. We term this Modal Isolation and attribute it to compounding information loss at modality boundaries. We decompose each reasoning cycle into atomic operations and define modality transition loss, quantifying cross-modal hallucination (text-to-image) and visual utilization deficit (image-to-text) at each boundary. We propose MoTiF (Modality Tiransition Fidelity), a two-stage training framework that directly optimizes these transitions: Reflective SFT trains the model to detect and recover from erroneous visual outputs; Flow-GRPO improves image generation fidelity via reinforcement learning. All training signals in MoTiF derive from transition-level fidelity rather than end-task accuracy. Across four visual puzzle benchmarks, this transition-level supervision substantially improves both cross-modal coherence and final task accuracy. The results demonstrate that effective interleaved reasoning requires explicit structural supervision at modality boundaries, not merely scaling or end-task optimization.
Rose-SQL: Role-State Evolution Guided Structured Reasoning for Multi-Turn Text-to-SQL
May 05, 2026Recent advances in Large Reasoning Models (LRMs) trained with Long Chain-of-Thought have demonstrated remarkable capabilities in code generation and mathematical reasoning. However, their potential in multi-turn Text-to-SQL tasks remains largely underexplored. Existing approaches typically rely on unstable API-based inference or require expensive fine-tuning on small-scale models. In this work, we present Rose-SQL, a training-free framework that leverages small-scale LRMs through in-context learning to enable accurate context-dependent parsing. We introduce the Role-State, a fine-grained representation that bridges the structural gap between schema linking and SQL generation by serving as a structural blueprint. To handle conversational dependencies, Rose-SQL traces the evolution of Role-State through historical context via structural isomorphism checks, guiding the model to infer the possible SQL composition for the current question through verified interaction trajectories. Experiments on the SParC and CoSQL benchmarks show that, within the Qwen3 series, Rose-SQL outperforms in-context learning baselines at the 4B scale and substantially surpasses state-of-the-art fine-tuned models at the 8B and 14B scales, while showing consistent gains on additional reasoning backbones.
ProDiff: Prototype-Guided Diffusion for Minimal Information Trajectory Imputation
May 29, 2025Trajectory data is crucial for various applications but often suffers from incompleteness due to device limitations and diverse collection scenarios. Existing imputation methods rely on sparse trajectory or travel information, such as velocity, to infer missing points. However, these approaches assume that sparse trajectories retain essential behavioral patterns, which place significant demands on data acquisition and overlook the potential of large-scale human trajectory embeddings. To address this, we propose ProDiff, a trajectory imputation framework that uses only two endpoints as minimal information. It integrates prototype learning to embed human movement patterns and a denoising diffusion probabilistic model for robust spatiotemporal reconstruction. Joint training with a tailored loss function ensures effective imputation. ProDiff outperforms state-of-the-art methods, improving accuracy by 6.28\% on FourSquare and 2.52\% on WuXi. Further analysis shows a 0.927 correlation between generated and real trajectories, demonstrating the effectiveness of our approach.
GeoGalactica: A Scientific Large Language Model in Geoscience
Dec 31, 2023

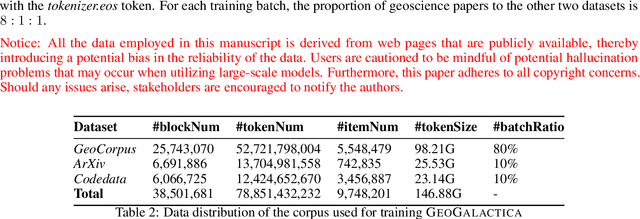
Large language models (LLMs) have achieved huge success for their general knowledge and ability to solve a wide spectrum of tasks in natural language processing (NLP). Due to their impressive abilities, LLMs have shed light on potential inter-discipline applications to foster scientific discoveries of a specific domain by using artificial intelligence (AI for science, AI4S). In the meantime, utilizing NLP techniques in geoscience research and practice is wide and convoluted, contributing from knowledge extraction and document classification to question answering and knowledge discovery. In this work, we take the initial step to leverage LLM for science, through a rather straightforward approach. We try to specialize an LLM into geoscience, by further pre-training the model with a vast amount of texts in geoscience, as well as supervised fine-tuning (SFT) the resulting model with our custom collected instruction tuning dataset. These efforts result in a model GeoGalactica consisting of 30 billion parameters. To our best knowledge, it is the largest language model for the geoscience domain. More specifically, GeoGalactica is from further pre-training of Galactica. We train GeoGalactica over a geoscience-related text corpus containing 65 billion tokens curated from extensive data sources in the big science project Deep-time Digital Earth (DDE), preserving as the largest geoscience-specific text corpus. Then we fine-tune the model with 1 million pairs of instruction-tuning data consisting of questions that demand professional geoscience knowledge to answer. In this technical report, we will illustrate in detail all aspects of GeoGalactica, including data collection, data cleaning, base model selection, pre-training, SFT, and evaluation. We open-source our data curation tools and the checkpoints of GeoGalactica during the first 3/4 of pre-training.
Fovea Transformer: Efficient Long-Context Modeling with Structured Fine-to-Coarse Attention
Nov 13, 2023



The quadratic complexity of self-attention in Transformers has hindered the processing of long text. To alleviate this problem, previous works have proposed to sparsify the attention matrix, taking advantage of the observation that crucial information about a token can be derived from its neighbors. These methods typically combine one or another form of local attention and global attention. Such combinations introduce abrupt changes in contextual granularity when going from local to global, which may be undesirable. We believe that a smoother transition could potentially enhance model's ability to capture long-context dependencies. In this study, we introduce Fovea Transformer, a long-context focused transformer that addresses the challenges of capturing global dependencies while maintaining computational efficiency. To achieve this, we construct a multi-scale tree from the input sequence, and use representations of context tokens with a progressively coarser granularity in the tree, as their distance to the query token increases. We evaluate our model on three long-context summarization tasks\footnote{Our code is publicly available at: \textit{https://github.com/ZiweiHe/Fovea-Transformer}}. It achieves state-of-the-art performance on two of them, and competitive results on the third with mixed improvement and setback of the evaluation metrics.
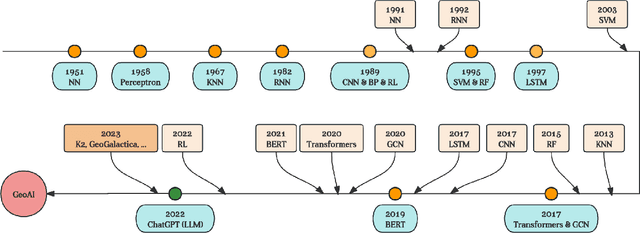
Learning A Foundation Language Model for Geoscience Knowledge Understanding and Utilization
Jun 08, 2023



Large language models (LLMs)have achieved great success in general domains of natural language processing. In this paper, we bring LLMs to the realm of geoscience, with the objective of advancing research and applications in this field. To this end, we present the first-ever LLM in geoscience, K2, alongside a suite of resources developed to further promote LLM research within geoscience. For instance, we have curated the first geoscience instruction tuning dataset, GeoSignal, which aims to align LLM responses to geoscience-related user queries. Additionally, we have established the first geoscience benchmark, GeoBenchmark, to evaluate LLMs in the context of geoscience. In this work, we experiment with a complete recipe to adapt a pretrained general-domain LLM to the geoscience domain. Specifically, we further train the LLaMA-7B model on over 1 million pieces of geoscience literature and utilize GeoSignal's supervised data to fine-tune the model. Moreover, we share a protocol that can efficiently gather domain-specific data and construct domain-supervised data, even in situations where manpower is scarce. Experiments conducted on the GeoBenchmark demonstrate the the effectiveness of our approach and datasets.