 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdeaReader: A Machine Reading System for Understanding the Idea Flow of Scientific Publications
Sep 27, 2022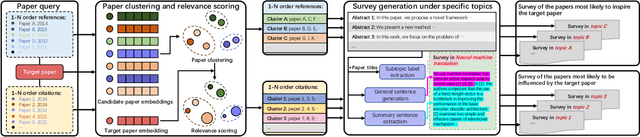
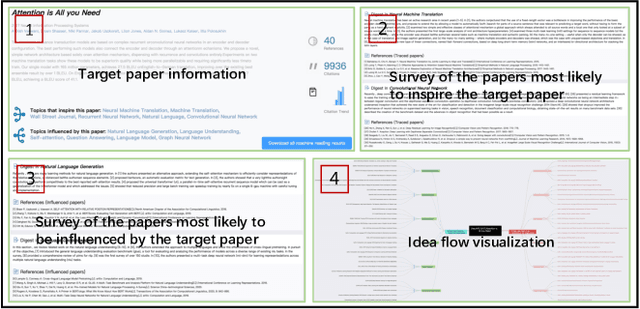
Understanding the origin and influence of the publication's idea is critical to conducting scientific research. However, the proliferation of scientific publications makes it difficult for researchers to sort out the evolution of all relevant literature. To this end, we present IdeaReader, a machine reading system that finds out which papers are most likely to inspire or be influenced by the target publication and summarizes the ideas of these papers in natural language. Specifically, IdeaReader first clusters the references and citations (first-order or higher-order) of the target publication, and the obtained clusters are regarded as the topics that inspire or are influenced by the target publication. It then picks out the important papers from each cluster to extract the skeleton of the idea flow. Finally, IdeaReader automatically generates a literature review of the important papers in each topic. Our system can help researchers gain insight into how scientific ideas flow from the target publication's references to citations by the automatically generated survey and the visualization of idea flow.
Disentangled Graph Contrastive Learning for Review-based Recommendation
Sep 04, 2022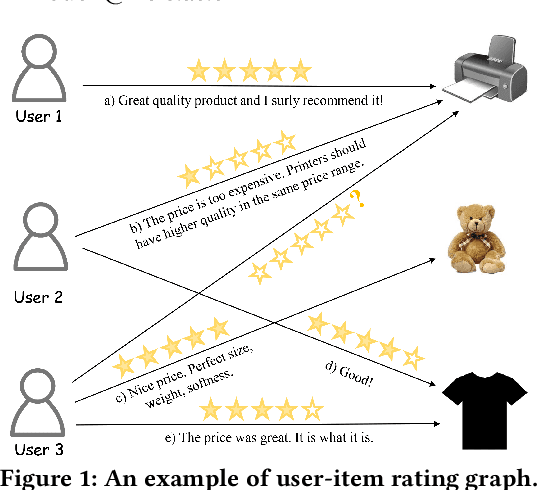
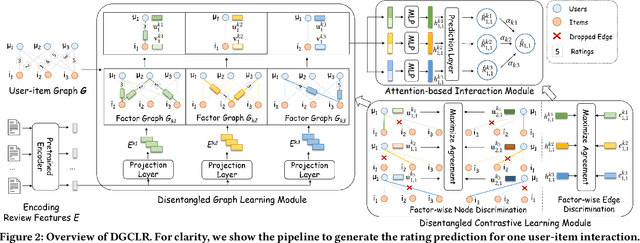
User review data is helpful in alleviating the data sparsity problem in many recommender systems. In review-based recommendation methods, review data is considered as auxiliary information that can improve the quality of learned user/item or interaction representations for the user rating prediction task. However, these methods usually model user-item interactions in a holistic manner and neglect the entanglement of the latent factors behind them, e.g., price, quality, or appearance, resulting in suboptimal representations and reducing interpretability. In this paper, we propose a Disentangled Graph Contrastive Learning framework for Review-based recommendation (DGCLR), to separately model the user-item interactions based on different latent factors through the textual review data. To this end, we first model the distributions of interactions over latent factors from both semantic information in review data and structural information in user-item graph data, forming several factor graphs. Then a factorized message passing mechanism is designed to learn disentangled user/item representations on the factor graphs, which enable us to further characterize the interactions and adaptively combine the predicted ratings from multiple factors via a devised attention mechanism. Finally, we set two factor-wise contrastive learning objectives to alleviate the sparsity issue and model the user/item and interaction features pertinent to each factor more accurately. Empirical results over five benchmark datasets validate the superiority of DGCLR over the state-of-the-art methods. Further analysis is offered to interpret the learned intent factors and rating prediction in DGCLR.