 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Visual-semantic Alignment for Zero-shot Learning with Ambiguous Labels
Apr 20, 2026Zero-shot learning (ZSL) aims to recognize unseen classes without visual instances. However, existing methods usually assume clean labels, overlooking real-world label noise and ambiguity, which degrades performance. To bridge this gap, we propose the Dynamic Visual-semantic Alignment (DVSA), a robust ZSL framework for learning from ambiguous labels. DVSA uses a bidirectional visual-semantic alignment module with attention to mutually calibrate visual features and attribute prototypes, and a contrastive optimization grounded in Mutual Information (MI) at the attribute level to strengthen discriminative, semantically consistent attributes. In addition, a dynamic label disambiguation mechanism iteratively corrects noisy supervision while preserving semantic consistency, narrowing the instance-label gap, and improving generalization. Extensive experiments on standard benchmarks verify that DVSA achieves stronger performance under ambiguous supervision.
How Do LLMs and VLMs Understand Viewpoint Rotation Without Vision? An Interpretability Study
Apr 16, 2026Over the past year, spatial intelligence has drawn increasing attention. Many prior works study it from the perspective of visual-spatial intelligence, where models have access to visuospatial information from visual inputs. However, in the absence of visual information, whether linguistic intelligence alone is sufficient to endow models with spatial intelligence, and how models perform relevant tasks with text-only inputs still remain unexplored. Therefore, in this paper, we focus on a fundamental and critical capability in spatial intelligence from a linguistic perspective: viewpoint rotation understanding (VRU). Specifically, LLMs and VLMs are asked to infer their final viewpoint and predict the corresponding observation in an environment given textual description of viewpoint rotation and observation over multiple steps. We find that both LLMs and VLMs perform poorly on our proposed dataset while human can easily achieve 100% accuracy, indicating a substantial gap between current model capabilities and the requirements of spatial intelligence. To uncover the underlying mechanisms, we conduct a layer-wise probing analysis and head-wise causal intervention. Our findings reveal that although models encode viewpoint information in the hidden states, they appear to struggle to bind the viewpoint position with corresponding observation, resulting in a hallucination in final layers. Finally, we selectively fine-tune the key attention heads identified by causal intervention to improve VRU performance. Experimental results demonstrate that such selective fine-tuning achieves improved VRU performance while avoiding catastrophic forgetting of generic abilities. Our dataset and code will be released at https://github.com/Young-Zhen/VRU_Interpret .
ContiGuard: A Framework for Continual Toxicity Detection Against Evolving Evasive Perturbations
Mar 16, 2026Toxicity detection mitigates the dissemination of toxic content (e.g., hateful comments, posts, and messages within online social actions) to safeguard a healthy online social environment. However, malicious users persistently develop evasive perturbations to disguise toxic content and evade detectors. Traditional detectors or methods are static over time and are inadequate in addressing these evolving evasion tactics. Thus, continual learning emerges as a logical approach to dynamically update detection ability against evolving perturbations. Nevertheless, disparities across perturbations hinder the detector's continual learning on perturbed text. More importantly, perturbation-induced noises distort semantics to degrade comprehension and also impair critical feature learning to render detection sensitive to perturbations. These amplify the challenge of continual learning against evolving perturbations. In this work, we present ContiGuard, the first framework tailored for continual learning of the detector on time-evolving perturbed text (termed continual toxicity detection) to enable the detector to continually update capability and maintain sustained resilience against evolving perturbations. Specifically, to boost the comprehension, we present an LLM-powered semantic enriching strategy, where we dynamically incorporate possible meaning and toxicity-related clues excavated by LLM into the perturbed text to improve the comprehension. To mitigate non-critical features and amplify critical ones, we propose a discriminability-driven feature learning strategy, where we strengthen discriminative features while suppressing the less-discriminative ones to shape a robust classification boundary for detection...
CLIP-driven Zero-shot Learning with Ambiguous Labels
Mar 05, 2026Zero-shot learning (ZSL) aims to recognize unseen classes by leveraging semantic information from seen classes, but most existing methods assume accurate class labels for training instances. However, in real-world scenarios, noise and ambiguous labels can significantly reduce the performance of ZSL. To address this, we propose a new CLIP-driven partial label zero-shot learning (CLIP-PZSL) framework to handle label ambiguity. First, we use CLIP to extract instance and label features. Then, a semantic mining block fuses these features to extract discriminative label embeddings. We also introduce a partial zero-shot loss, which assigns weights to candidate labels based on their relevance to the instance and aligns instance and label embeddings to minimize semantic mismatch. As the training goes on, the ground-truth labels are progressively identified, and the refined labels and label embeddings in turn help improve the semantic alignment of instance and label features. Comprehensive experiments on several datasets demonstrate the advantage of CLIP-PZSL.
BIOME-Bench: A Benchmark for Biomolecular Interaction Inference and Multi-Omics Pathway Mechanism Elucidation from Scientific Literature
Dec 31, 2025Multi-omics studies often rely on pathway enrichment to interpret heterogeneous molecular changes, but pathway enrichment (PE)-based workflows inherit structural limitations of pathway resources, including curation lag, functional redundancy, and limited sensitivity to molecular states and interventions. Although recent work has explored using large language models (LLMs) to improve PE-based interpretation, the lack of a standardized benchmark for end-to-end multi-omics pathway mechanism elucidation has largely confined evaluation to small, manually curated datasets or ad hoc case studies, hindering reproducible progress. To address this issue, we introduce BIOME-Bench, constructed via a rigorous four-stage workflow, to evaluate two core capabilities of LLMs in multi-omics analysis: Biomolecular Interaction Inference and end-to-end Multi-Omics Pathway Mechanism Elucidation. We develop evaluation protocols for both tasks and conduct comprehensive experiments across multiple strong contemporary models. Experimental results demonstrate that existing models still exhibit substantial deficiencies in multi-omics analysis, struggling to reliably distinguish fine-grained biomolecular relation types and to generate faithful, robust pathway-level mechanistic explanations.
A Survey on Training-free Alignment of Large Language Models
Aug 12, 2025The alignment of large language models (LLMs) aims to ensure their outputs adhere to human values, ethical standards, and legal norms. Traditional alignment methods often rely on resource-intensive fine-tuning (FT), which may suffer from knowledge degradation and face challenges in scenarios where the model accessibility or computational resources are constrained. In contrast, training-free (TF) alignment techniques--leveraging in-context learning, decoding-time adjustments, and post-generation corrections--offer a promising alternative by enabling alignment without heavily retraining LLMs, making them adaptable to both open-source and closed-source environments. This paper presents the first systematic review of TF alignment methods, categorizing them by stages of pre-decoding, in-decoding, and post-decoding. For each stage, we provide a detailed examination from the viewpoint of LLMs and multimodal LLMs (MLLMs), highlighting their mechanisms and limitations. Furthermore, we identify key challenges and future directions, paving the way for more inclusive and effective TF alignment techniques. By synthesizing and organizing the rapidly growing body of research, this survey offers a guidance for practitioners and advances the development of safer and more reliable LLMs.
CCHall: A Novel Benchmark for Joint Cross-Lingual and Cross-Modal Hallucinations Detection in Large Language Models
May 25, 2025

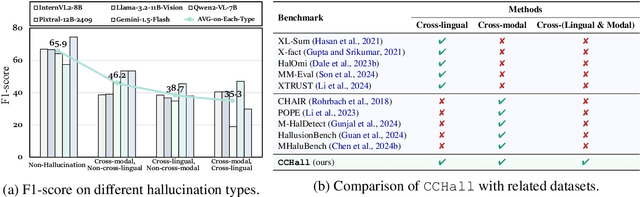

Investigating hallucination issues in large language models (LLMs) within cross-lingual and cross-modal scenarios can greatly advance the large-scale deployment in real-world applications. Nevertheless, the current studies are limited to a single scenario, either cross-lingual or cross-modal, leaving a gap in the exploration of hallucinations in the joint cross-lingual and cross-modal scenarios. Motivated by this, we introduce a novel joint Cross-lingual and Cross-modal Hallucinations benchmark (CCHall) to fill this gap. Specifically, CCHall simultaneously incorporates both cross-lingual and cross-modal hallucination scenarios, which can be used to assess the cross-lingual and cross-modal capabilities of LLMs. Furthermore, we conduct a comprehensive evaluation on CCHall, exploring both mainstream open-source and closed-source LLMs. The experimental results highlight that current LLMs still struggle with CCHall. We hope CCHall can serve as a valuable resource to assess LLMs in joint cross-lingual and cross-modal scenarios.
SRLCG: Self-Rectified Large-Scale Code Generation with Multidimensional Chain-of-Thought and Dynamic Backtracking
Apr 01, 2025Large language models (LLMs) have revolutionized code generation, significantly enhancing developer productivity. However, for a vast number of users with minimal coding knowledge, LLMs provide little support, as they primarily generate isolated code snippets rather than complete, large-scale project code. Without coding expertise, these users struggle to interpret, modify, and iteratively refine the outputs of LLMs, making it impossible to assemble a complete project. To address this issue, we propose Self-Rectified Large-Scale Code Generator (SRLCG), a framework that generates complete multi-file project code from a single prompt. SRLCG employs a novel multidimensional chain-of-thought (CoT) and self-rectification to guide LLMs in generating correct and robust code files, then integrates them into a complete and coherent project using our proposed dynamic backtracking algorithm. Experimental results show that SRLCG generates code 15x longer than DeepSeek-V3, 16x longer than GPT-4, and at least 10x longer than other leading CoT-based baselines. Furthermore, they confirm its improved correctness, robustness, and performance compared to baselines in large-scale code generation.
BianCang: A Traditional Chinese Medicine Large Language Model
Nov 17, 2024



The rise of large language models (LLMs) has driven significant progress in medical applications, including traditional Chinese medicine (TCM). However, current medical LLMs struggle with TCM diagnosis and syndrome differentiation due to substantial differences between TCM and modern medical theory, and the scarcity of specialized, high-quality corpora. This paper addresses these challenges by proposing BianCang, a TCM-specific LLM, using a two-stage training process that first injects domain-specific knowledge and then aligns it through targeted stimulation. To enhance diagnostic and differentiation capabilities, we constructed pre-training corpora, instruction-aligned datasets based on real hospital records, and the ChP-TCM dataset derived from the Pharmacopoeia of the People's Republic of China. We compiled extensive TCM and medical corpora for continuous pre-training and supervised fine-tuning, building a comprehensive dataset to refine the model's understanding of TCM. Evaluations across 11 test sets involving 29 models and 4 tasks demonstrate the effectiveness of BianCang, offering valuable insights for future research. Code, datasets, and models are available at https://github.com/QLU-NLP/BianCang.
PMoL: Parameter Efficient MoE for Preference Mixing of LLM Alignment
Nov 02, 2024



Reinforcement Learning from Human Feedback (RLHF) has been proven to be an effective method for preference alignment of large language models (LLMs) and is widely used in the post-training process of LLMs. However, RLHF struggles with handling multiple competing preferences. This leads to a decrease in the alignment of LLMs with human preferences. To address this issue, we propose Preference Mixture of LoRAs (PMoL) from the perspective of model architecture, which can adapt to any number of preferences to mix. PMoL combines Mixture of Experts (MoE) and Low Rank Adaptor (LoRA). This architecture is innovatively applied to the research of preference alignment and has achieved significant performance improvement. The expert group soft loss is used to enable MoE with the ability to mix preferences. Through comprehensive evaluation by the reward model and GPT-4o, the experiment results show that PMoL has superior preference mixing capabilities compared to baseline methods. PMoL achieves better preference alignment with lower training costs.