 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBianCang: A Traditional Chinese Medicine Large Language Model
Nov 17, 2024



The rise of large language models (LLMs) has driven significant progress in medical applications, including traditional Chinese medicine (TCM). However, current medical LLMs struggle with TCM diagnosis and syndrome differentiation due to substantial differences between TCM and modern medical theory, and the scarcity of specialized, high-quality corpora. This paper addresses these challenges by proposing BianCang, a TCM-specific LLM, using a two-stage training process that first injects domain-specific knowledge and then aligns it through targeted stimulation. To enhance diagnostic and differentiation capabilities, we constructed pre-training corpora, instruction-aligned datasets based on real hospital records, and the ChP-TCM dataset derived from the Pharmacopoeia of the People's Republic of China. We compiled extensive TCM and medical corpora for continuous pre-training and supervised fine-tuning, building a comprehensive dataset to refine the model's understanding of TCM. Evaluations across 11 test sets involving 29 models and 4 tasks demonstrate the effectiveness of BianCang, offering valuable insights for future research. Code, datasets, and models are available at https://github.com/QLU-NLP/BianCang.
An empirical study of next-basket recommendations
Dec 05, 2023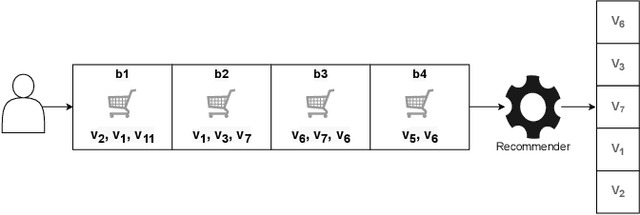
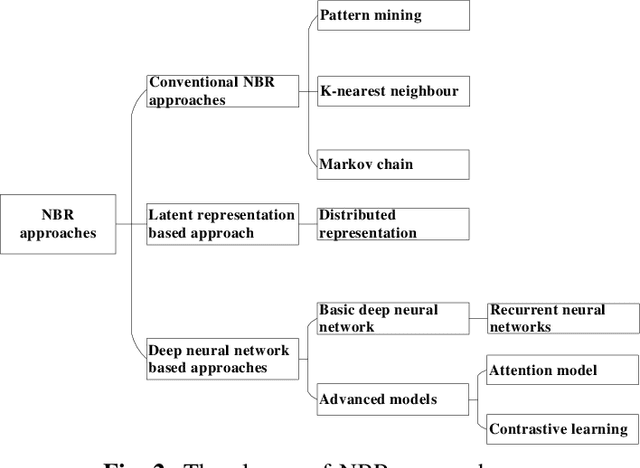
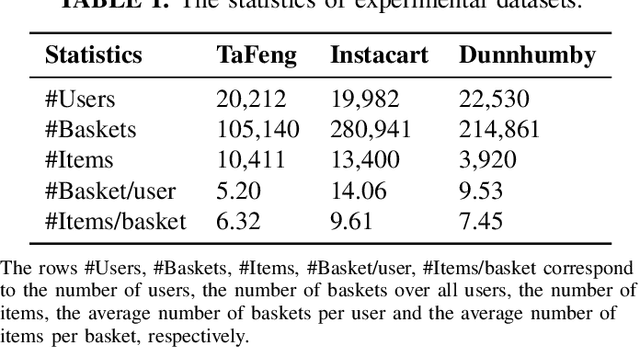
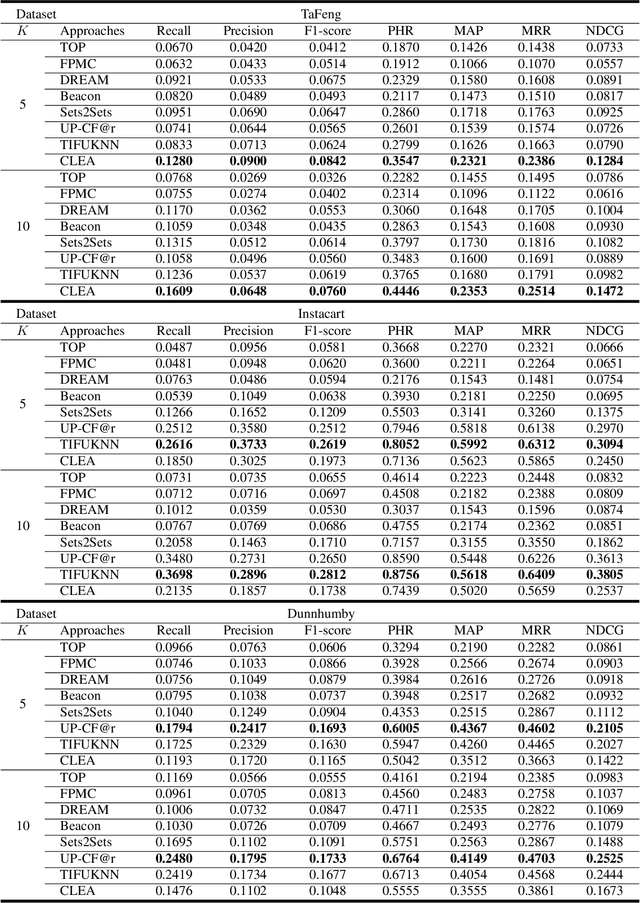
Next Basket Recommender Systems (NBRs) function to recommend the subsequent shopping baskets for users through the modeling of their preferences derived from purchase history, typically manifested as a sequence of historical baskets. Given their widespread applicability in the E-commerce industry, investigations into NBRs have garnered increased attention in recent years. Despite the proliferation of diverse NBR methodologies, a substantial challenge lies in the absence of a systematic and unified evaluation framework across these methodologies. Various studies frequently appraise NBR approaches using disparate datasets and diverse experimental settings, impeding a fair and effective comparative assessment of methodological performance. To bridge this gap, this study undertakes a systematic empirical inquiry into NBRs, reviewing seminal works within the domain and scrutinizing their respective merits and drawbacks. Subsequently, we implement designated NBR algorithms on uniform datasets, employing consistent experimental configurations, and assess their performances via identical metrics. This methodological rigor establishes a cohesive framework for the impartial evaluation of diverse NBR approaches. It is anticipated that this study will furnish a robust foundation and serve as a pivotal reference for forthcoming research endeavors in this dynamic field.
Medical Question Summarization with Entity-driven Contrastive Learning
Apr 15, 2023By summarizing longer consumer health questions into shorter and essential ones, medical question answering (MQA) systems can more accurately understand consumer intentions and retrieve suitable answers. However, medical question summarization is very challenging due to obvious distinctions in health trouble descriptions from patients and doctors. Although existing works have attempted to utilize Seq2Seq, reinforcement learning, or contrastive learning to solve the problem, two challenges remain: how to correctly capture question focus to model its semantic intention, and how to obtain reliable datasets to fairly evaluate performance. To address these challenges, this paper proposes a novel medical question summarization framework using entity-driven contrastive learning (ECL). ECL employs medical entities in frequently asked questions (FAQs) as focuses and devises an effective mechanism to generate hard negative samples. This approach forces models to pay attention to the crucial focus information and generate more ideal question summarization. Additionally, we find that some MQA datasets suffer from serious data leakage problems, such as the iCliniq dataset's 33% duplicate rate. To evaluate the related methods fairly, this paper carefully checks leaked samples to reorganize more reasonable datasets. Extensive experiments demonstrate that our ECL method outperforms state-of-the-art methods by accurately capturing question focus and generating medical question summaries. The code and datasets are available at https://github.com/yrbobo/MQS-ECL.
A Systematical Evaluation for Next-Basket Recommendation Algorithms
Sep 07, 2022
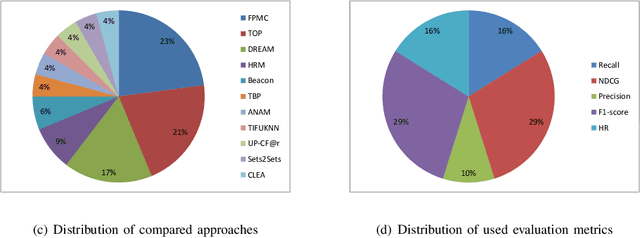
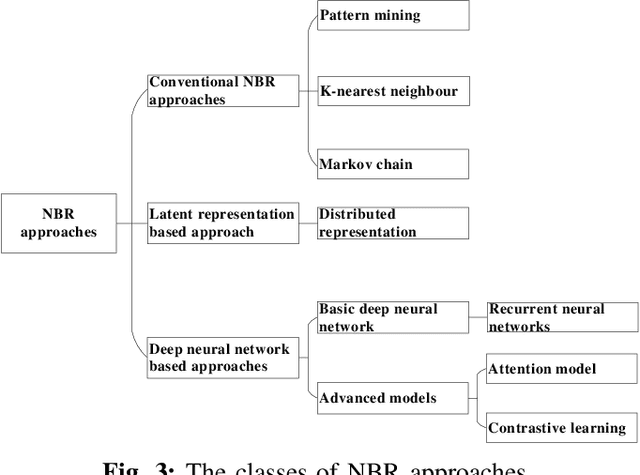
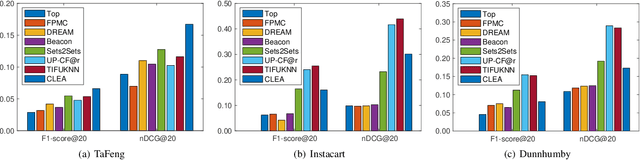
Next basket recommender systems (NBRs) aim to recommend a user's next (shopping) basket of items via modeling the user's preferences towards items based on the user's purchase history, usually a sequence of historical baskets. Due to its wide applicability in the real-world E-commerce industry, the studies NBR have attracted increasing attention in recent years. NBRs have been widely studied and much progress has been achieved in this area with a variety of NBR approaches having been proposed. However, an important issue is that there is a lack of a systematic and unified evaluation over the various NBR approaches. Different studies often evaluate NBR approaches on different datasets, under different experimental settings, making it hard to fairly and effectively compare the performance of different NBR approaches. To bridge this gap, in this work, we conduct a systematical empirical study in NBR area. Specifically, we review the representative work in NBR and analyze their cons and pros. Then, we run the selected NBR algorithms on the same datasets, under the same experimental setting and evaluate their performances using the same measurements. This provides a unified framework to fairly compare different NBR approaches. We hope this study can provide a valuable reference for the future research in this vibrant area.
Rethinking Adjacent Dependency in Session-based Recommendations
Jan 29, 2022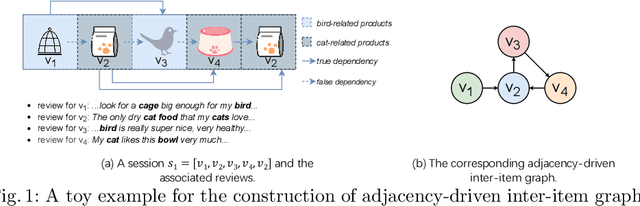
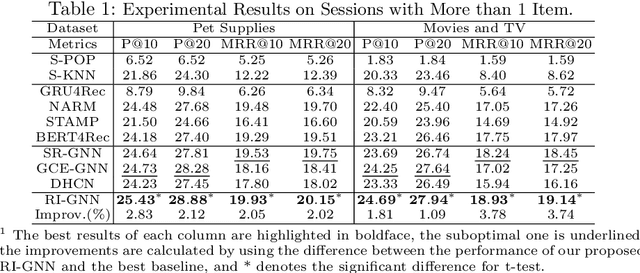
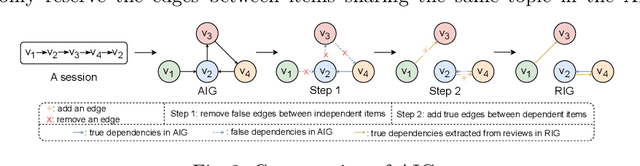
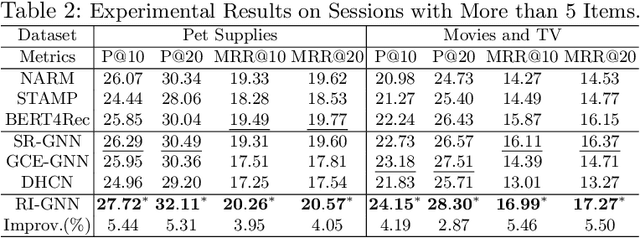
Session-based recommendations (SBRs) recommend the next item for an anonymous user by modeling the dependencies between items in a session. Benefiting from the superiority of graph neural networks (GNN) in learning complex dependencies, GNN-based SBRs have become the main stream of SBRs in recent years. Most GNN-based SBRs are based on a strong assumption of adjacent dependency, which means any two adjacent items in a session are necessarily dependent here. However, based on our observation, the adjacency does not necessarily indicate dependency due to the uncertainty and complexity of user behaviours. Therefore, the aforementioned assumption does not always hold in the real-world cases and thus easily leads to two deficiencies: (1) the introduction of false dependencies between items which are adjacent in a session but are not really dependent, and (2) the missing of true dependencies between items which are not adjacent but are actually dependent. Such deficiencies significantly downgrade accurate dependency learning and thus reduce the recommendation performance. Aiming to address these deficiencies, we propose a novel review-refined inter-item graph neural network (RI-GNN), which utilizes the topic information extracted from items' reviews to refine dependencies between items. Experiments on two public real-world datasets demonstrate that RI-GNN outperforms the state-of-the-art methods.
Aspect-driven User Preference and News Representation Learning for News Recommendation
Oct 12, 2021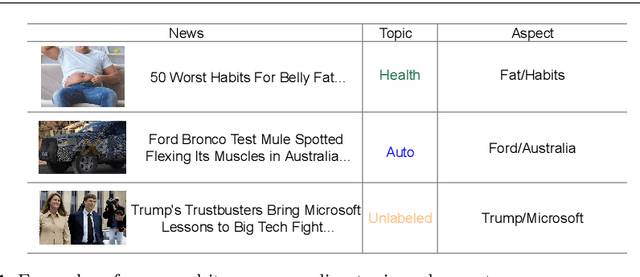

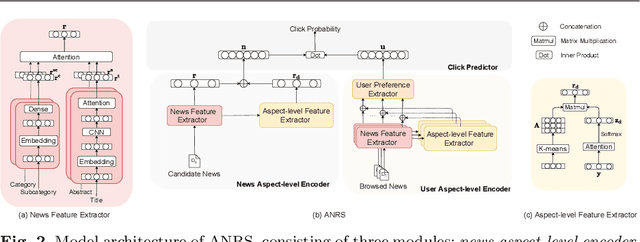
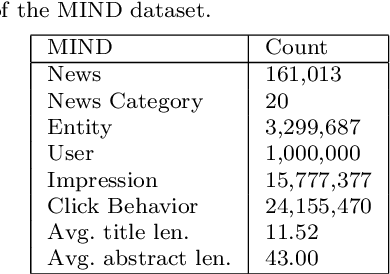
News recommender systems are essential for helping users to efficiently and effectively find out those interesting news from a large amount of news. Most of existing news recommender systems usually learn topic-level representations of users and news for recommendation, and neglect to learn more informative aspect-level features of users and news for more accurate recommendation. As a result, they achieve limited recommendation performance. Aiming at addressing this deficiency, we propose a novel Aspect-driven News Recommender System (ANRS) built on aspect-level user preference and news representation learning. Here, \textit{news aspect} is fine-grained semantic information expressed by a set of related words, which indicates specific aspects described by the news. In ANRS, \textit{news aspect-level encoder} and \textit{user aspect-level encoder} are devised to learn the fine-grained aspect-level representations of user's preferences and news characteristics respectively, which are fed into \textit{click predictor} to judge the probability of the user clicking the candidate news. Extensive experiments are done on the commonly used real-world dataset MIND, which demonstrate the superiority of our method compared with representative and state-of-the-art methods.
Sequential Diagnosis Prediction with Transformer and Ontological Representation
Sep 07, 2021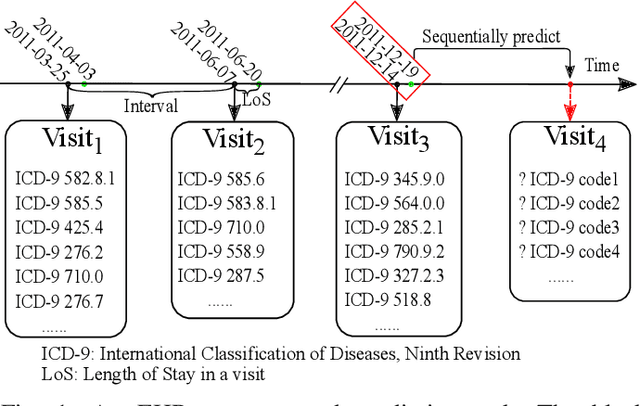
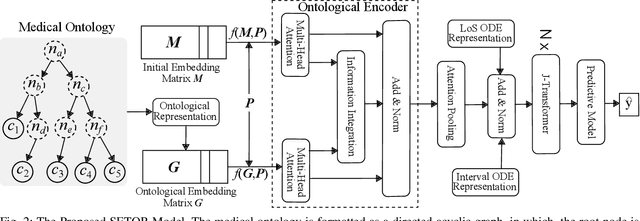
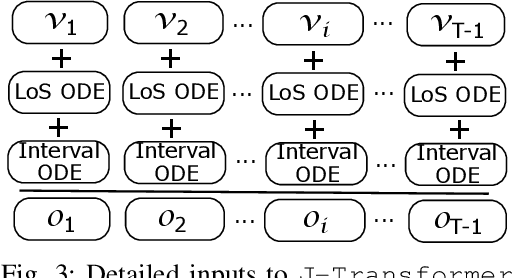
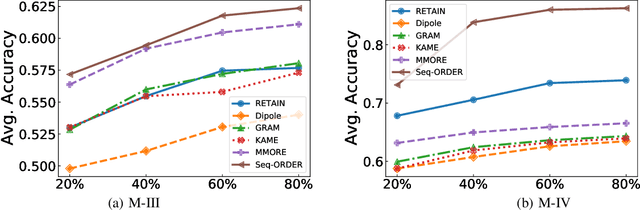
Sequential diagnosis prediction on the Electronic Health Record (EHR) has been proven crucial for predictive analytics in the medical domain. EHR data, sequential records of a patient's interactions with healthcare systems, has numerous inherent characteristics of temporality, irregularity and data insufficiency. Some recent works train healthcare predictive models by making use of sequential information in EHR data, but they are vulnerable to irregular, temporal EHR data with the states of admission/discharge from hospital, and insufficient data. To mitigate this, we propose an end-to-end robust transformer-based model called SETOR, which exploits neural ordinary differential equation to handle both irregular intervals between a patient's visits with admitted timestamps and length of stay in each visit, to alleviate the limitation of insufficient data by integrating medical ontology, and to capture the dependencies between the patient's visits by employing multi-layer transformer blocks. Experiments conducted on two real-world healthcare datasets show that, our sequential diagnoses prediction model SETOR not only achieves better predictive results than previous state-of-the-art approaches, irrespective of sufficient or insufficient training data, but also derives more interpretable embeddings of medical codes. The experimental codes are available at the GitHub repository (https://github.com/Xueping/SETOR).
MIMO: Mutual Integration of Patient Journey and Medical Ontology for Healthcare Representation Learning
Jul 23, 2021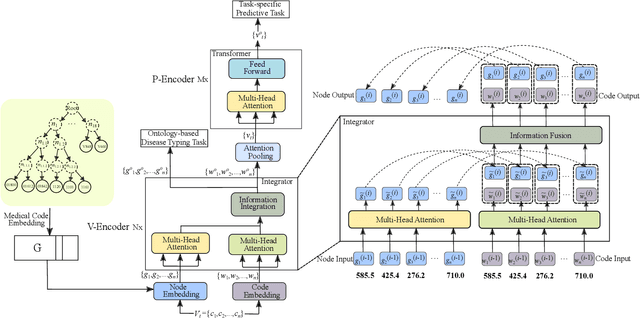
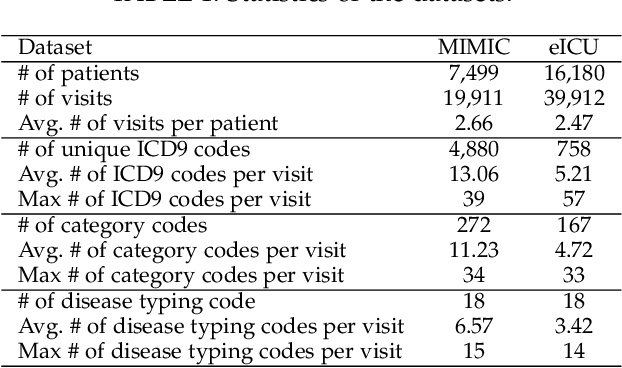
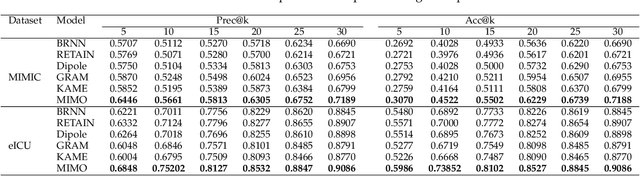
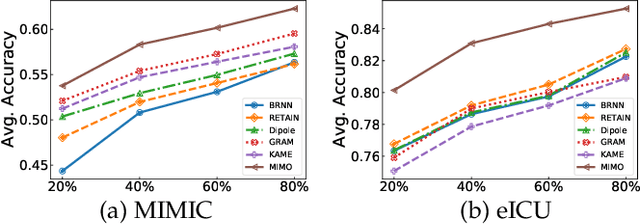
Healthcare representation learning on the Electronic Health Record (EHR) is seen as crucial for predictive analytics in the medical field. Many natural language processing techniques, such as word2vec, RNN and self-attention, have been adapted for use in hierarchical and time stamped EHR data, but fail when they lack either general or task-specific data. Hence, some recent works train healthcare representations by incorporating medical ontology (a.k.a. knowledge graph), by self-supervised tasks like diagnosis prediction, but (1) the small-scale, monotonous ontology is insufficient for robust learning, and (2) critical contexts or dependencies underlying patient journeys are never exploited to enhance ontology learning. To address this, we propose an end-to-end robust Transformer-based solution, Mutual Integration of patient journey and Medical Ontology (MIMO) for healthcare representation learning and predictive analytics. Specifically, it consists of task-specific representation learning and graph-embedding modules to learn both patient journey and medical ontology interactively. Consequently, this creates a mutual integration to benefit both healthcare representation learning and medical ontology embedding. Moreover, such integration is achieved by a joint training of both task-specific predictive and ontology-based disease typing tasks based on fused embeddings of the two modules. Experiments conducted on two real-world diagnosis prediction datasets show that, our healthcare representation model MIMO not only achieves better predictive results than previous state-of-the-art approaches regardless of sufficient or insufficient training data, but also derives more interpretable embeddings of diagnoses.
BiteNet: Bidirectional Temporal Encoder Network to Predict Medical Outcomes
Sep 24, 2020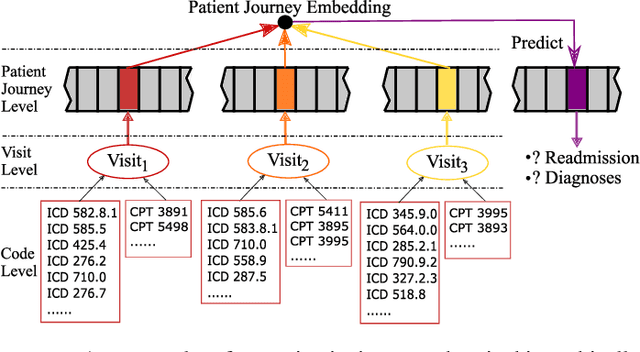
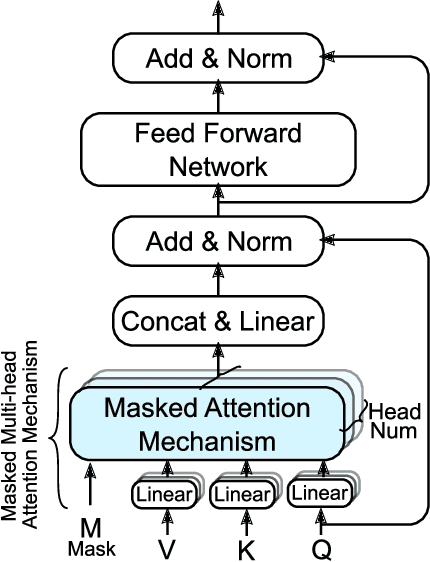
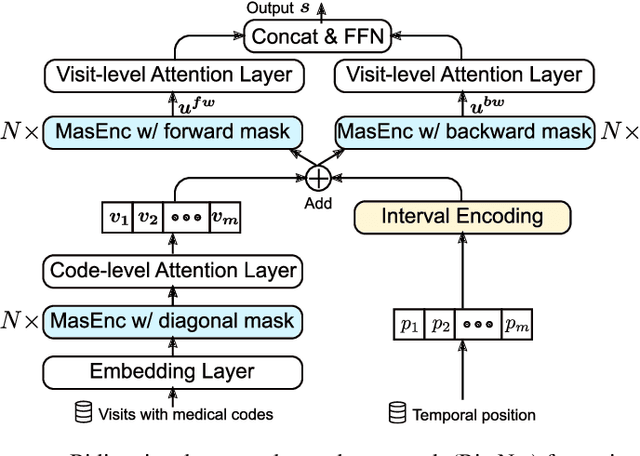
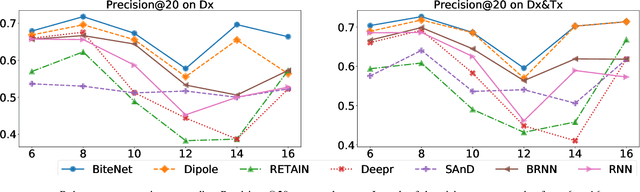
Electronic health records (EHRs) are longitudinal records of a patient's interactions with healthcare systems. A patient's EHR data is organized as a three-level hierarchy from top to bottom: patient journey - all the experiences of diagnoses and treatments over a period of time; individual visit - a set of medical codes in a particular visit; and medical code - a specific record in the form of medical codes. As EHRs begin to amass in millions, the potential benefits, which these data might hold for medical research and medical outcome prediction, are staggering - including, for example, predicting future admissions to hospitals, diagnosing illnesses or determining the efficacy of medical treatments. Each of these analytics tasks requires a domain knowledge extraction method to transform the hierarchical patient journey into a vector representation for further prediction procedure. The representations should embed a sequence of visits and a set of medical codes with a specific timestamp, which are crucial to any downstream prediction tasks. Hence, expressively powerful representations are appealing to boost learning performance. To this end, we propose a novel self-attention mechanism that captures the contextual dependency and temporal relationships within a patient's healthcare journey. An end-to-end bidirectional temporal encoder network (BiteNet) then learns representations of the patient's journeys, based solely on the proposed attention mechanism. We have evaluated the effectiveness of our methods on two supervised prediction and two unsupervised clustering tasks with a real-world EHR dataset. The empirical results demonstrate the proposed BiteNet model produces higher-quality representations than state-of-the-art baseline methods.
Self-Attention Enhanced Patient Journey Understanding in Healthcare System
Jun 19, 2020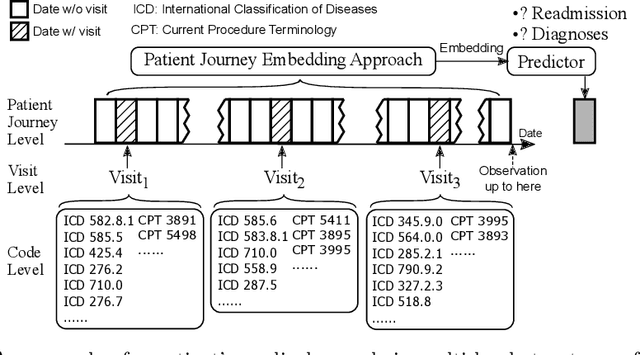

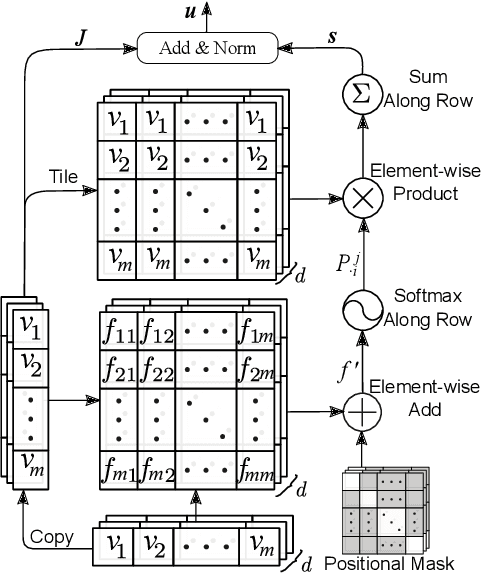
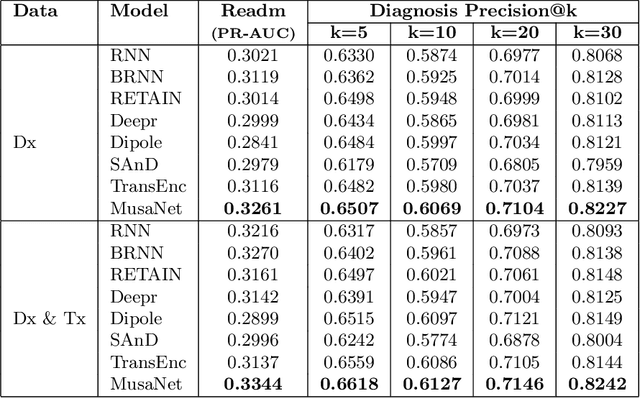
Understanding patients' journeys in healthcare system is a fundamental prepositive task for a broad range of AI-based healthcare applications. This task aims to learn an informative representation that can comprehensively encode hidden dependencies among medical events and its inner entities, and then the use of encoding outputs can greatly benefit the downstream application-driven tasks. A patient journey is a sequence of electronic health records (EHRs) over time that is organized at multiple levels: patient, visits and medical codes. The key challenge of patient journey understanding is to design an effective encoding mechanism which can properly tackle the aforementioned multi-level structured patient journey data with temporal sequential visits and a set of medical codes. This paper proposes a novel self-attention mechanism that can simultaneously capture the contextual and temporal relationships hidden in patient journeys. A multi-level self-attention network (MusaNet) is specifically designed to learn the representations of patient journeys that is used to be a long sequence of activities. The MusaNet is trained in end-to-end manner using the training data derived from EHRs. We evaluated the efficacy of our method on two medical application tasks with real-world benchmark datasets. The results have demonstrated the proposed MusaNet produces higher-quality representations than state-of-the-art baseline methods. The source code is available in https://github.com/xueping/MusaNet.