 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Moving Camera Pedestrian Tracking with a New Dataset and Global Link Model
Jan 02, 2024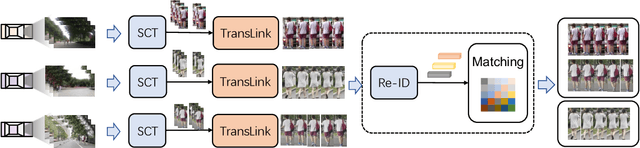
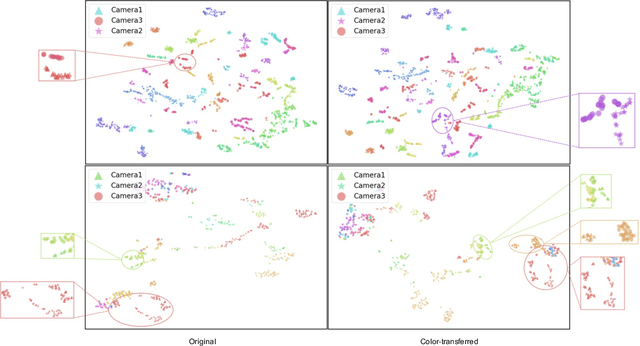
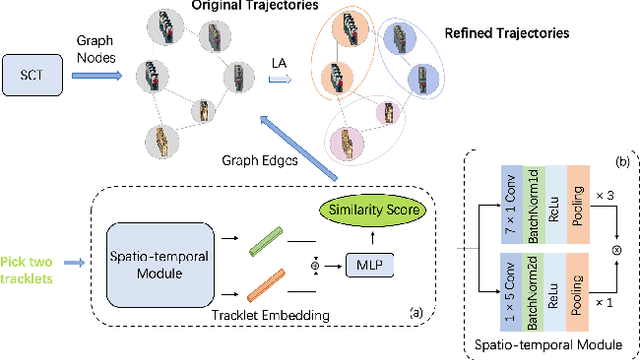
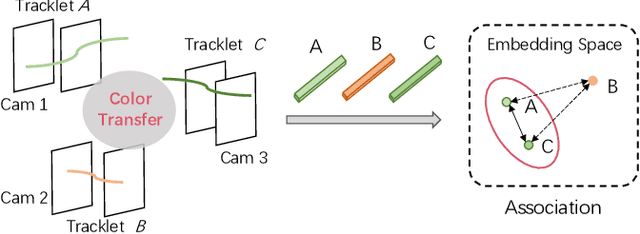
Ensuring driving safety for autonomous vehicles has become increasingly crucial, highlighting the need for systematic tracking of pedestrians on the road. Most vehicles are equipped with visual sensors, however, the large-scale visual dataset from different agents has not been well studied yet. Basically, most of the multi-target multi-camera (MTMC) tracking systems are composed of two modules: single camera tracking (SCT) and inter-camera tracking (ICT). To reliably coordinate between them, MTMC tracking has been a very complicated task, while tracking across multi-moving cameras makes it even more challenging. In this paper, we focus on multi-target multi-moving camera (MTMMC) tracking, which is attracting increasing attention from the research community. Observing there are few datasets for MTMMC tracking, we collect a new dataset, called Multi-Moving Camera Track (MMCT), which contains sequences under various driving scenarios. To address the common problems of identity switch easily faced by most existing SCT trackers, especially for moving cameras due to ego-motion between the camera and targets, a lightweight appearance-free global link model, called Linker, is proposed to mitigate the identity switch by associating two disjoint tracklets of the same target into a complete trajectory within the same camera. Incorporated with Linker, existing SCT trackers generally obtain a significant improvement. Moreover, a strong baseline approach of re-identification (Re-ID) is effectively incorporated to extract robust appearance features under varying surroundings for pedestrian association across moving cameras for ICT, resulting in a much improved MTMMC tracking system, which can constitute a step further towards coordinated mining of multiple moving cameras. The dataset is available at https://github.com/dhu-mmct/DHU-MMCT}{https://github.com/dhu-mmct/DHU-MMCT .
Rethinking Adjacent Dependency in Session-based Recommendations
Jan 29, 2022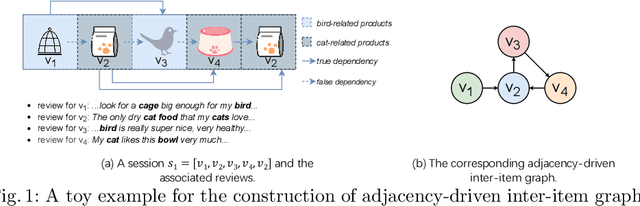
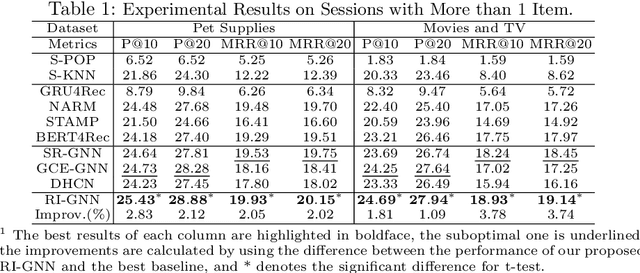
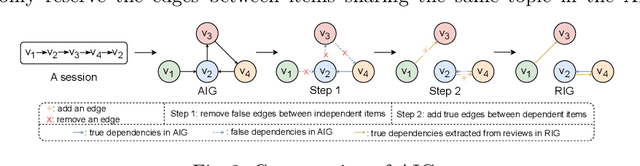
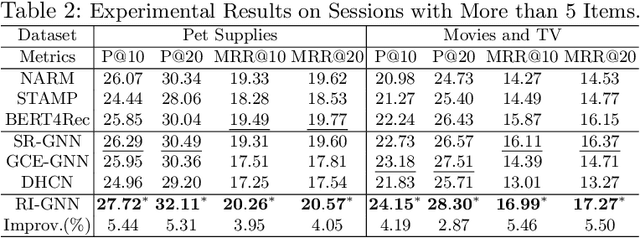
Session-based recommendations (SBRs) recommend the next item for an anonymous user by modeling the dependencies between items in a session. Benefiting from the superiority of graph neural networks (GNN) in learning complex dependencies, GNN-based SBRs have become the main stream of SBRs in recent years. Most GNN-based SBRs are based on a strong assumption of adjacent dependency, which means any two adjacent items in a session are necessarily dependent here. However, based on our observation, the adjacency does not necessarily indicate dependency due to the uncertainty and complexity of user behaviours. Therefore, the aforementioned assumption does not always hold in the real-world cases and thus easily leads to two deficiencies: (1) the introduction of false dependencies between items which are adjacent in a session but are not really dependent, and (2) the missing of true dependencies between items which are not adjacent but are actually dependent. Such deficiencies significantly downgrade accurate dependency learning and thus reduce the recommendation performance. Aiming to address these deficiencies, we propose a novel review-refined inter-item graph neural network (RI-GNN), which utilizes the topic information extracted from items' reviews to refine dependencies between items. Experiments on two public real-world datasets demonstrate that RI-GNN outperforms the state-of-the-art methods.
JEFL: Joint Embedding of Formal Proof Libraries
Jul 21, 2021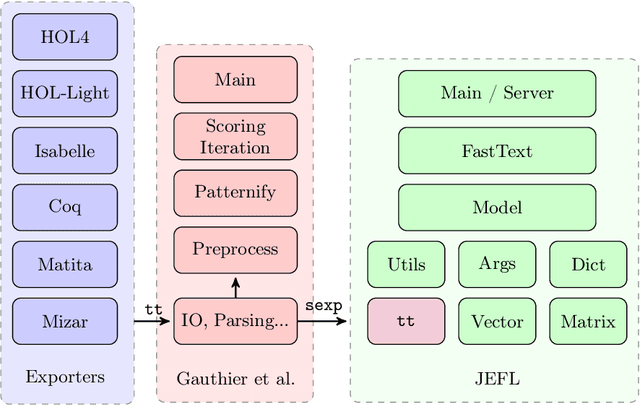

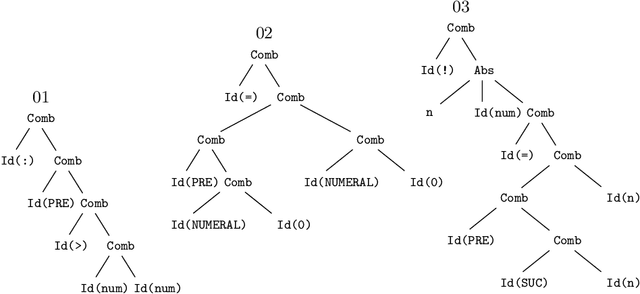
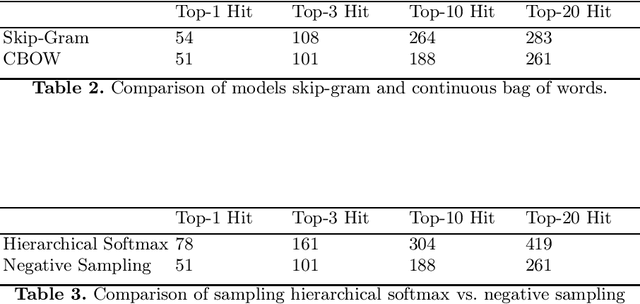
The heterogeneous nature of the logical foundations used in different interactive proof assistant libraries has rendered discovery of similar mathematical concepts among them difficult. In this paper, we compare a previously proposed algorithm for matching concepts across libraries with our unsupervised embedding approach that can help us retrieve similar concepts. Our approach is based on the fasttext implementation of Word2Vec, on top of which a tree traversal module is added to adapt its algorithm to the representation format of our data export pipeline. We compare the explainability, customizability, and online-servability of the approaches and argue that the neural embedding approach has more potential to be integrated into an interactive proof assistant.
Exploration of Neural Machine Translation in Autoformalization of Mathematics in Mizar
Dec 13, 2019

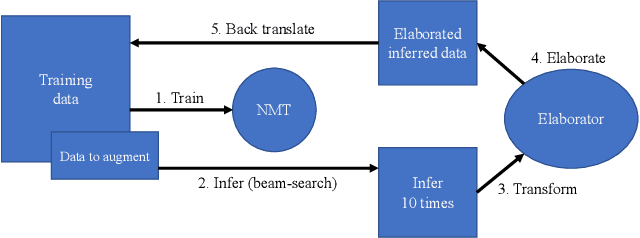
In this paper we share several experiments trying to automatically translate informal mathematics into formal mathematics. In our context informal mathematics refers to human-written mathematical sentences in the LaTeX format; and formal mathematics refers to statements in the Mizar language. We conducted our experiments against three established neural network-based machine translation models that are known to deliver competitive results on translating between natural languages. To train these models we also prepared four informal-to-formal datasets. We compare and analyze our results according to whether the model is supervised or unsupervised. In order to augment the data available for auto-formalization and improve the results, we develop a custom type-elaboration mechanism and integrate it in the supervised translation.
First Experiments with Neural Translation of Informal to Formal Mathematics
Jun 11, 2018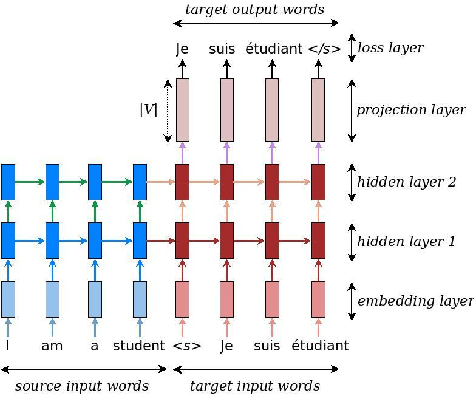
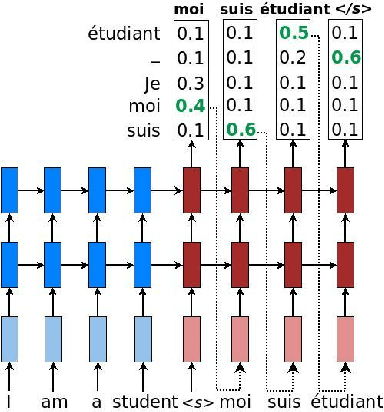
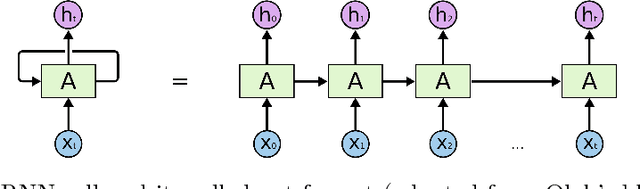

We report on our experiments to train deep neural networks that automatically translate informalized LaTeX-written Mizar texts into the formal Mizar language. To the best of our knowledge, this is the first time when neural networks have been adopted in the formalization of mathematics. Using Luong et al.'s neural machine translation model (NMT), we tested our aligned informal-formal corpora against various hyperparameters and evaluated their results. Our experiments show that our best performing model configurations are able to generate correct Mizar statements on 65.73\% of the inference data, with the union of all models covering 79.17\%. These results indicate that formalization through artificial neural network is a promising approach for automated formalization of mathematics. We present several case studies to illustrate our results.