 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaveAgent: Transforming LLMs into Stateful Runtime Operators
Jan 04, 2026LLM-based agents are increasingly capable of complex task execution, yet current agentic systems remain constrained by text-centric paradigms. Traditional approaches rely on procedural JSON-based function calling, which often struggles with long-horizon tasks due to fragile multi-turn dependencies and context drift. In this paper, we present CaveAgent, a framework that transforms the paradigm from "LLM-as-Text-Generator" to "LLM-as-Runtime-Operator." We introduce a Dual-stream Context Architecture that decouples state management into a lightweight semantic stream for reasoning and a persistent, deterministic Python Runtime stream for execution. In addition to leveraging code generation to efficiently resolve interdependent sub-tasks (e.g., loops, conditionals) in a single step, we introduce \textit{Stateful Runtime Management} in CaveAgent. Distinct from existing code-based approaches that remain text-bound and lack the support for external object injection and retrieval, CaveAgent injects, manipulates, and retrieves complex Python objects (e.g., DataFrames, database connections) that persist across turns. This persistence mechanism acts as a high-fidelity external memory to eliminate context drift, avoid catastrophic forgetting, while ensuring that processed data flows losslessly to downstream applications. Comprehensive evaluations on Tau$^2$-bench, BFCL and various case studies across representative SOTA LLMs demonstrate CaveAgent's superiority. Specifically, our framework achieves a 10.5\% success rate improvement on retail tasks and reduces total token consumption by 28.4\% in multi-turn scenarios. On data-intensive tasks, direct variable storage and retrieval reduces token consumption by 59\%, allowing CaveAgent to handle large-scale data that causes context overflow failures in both JSON-based and Code-based agents.
ViCO: A Training Strategy towards Semantic Aware Dynamic High-Resolution
Oct 14, 2025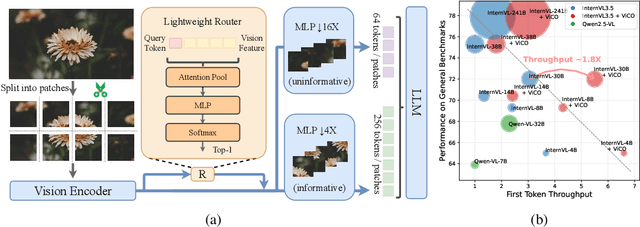
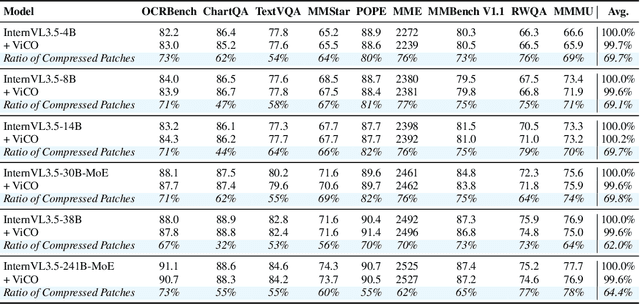
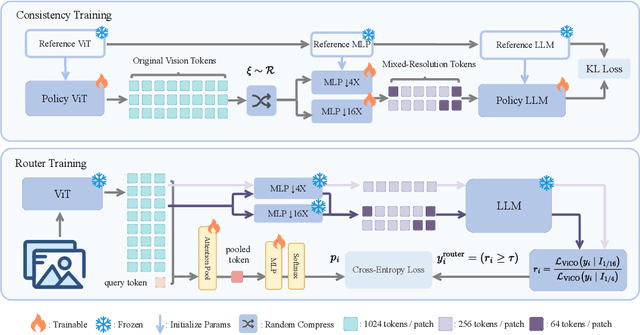
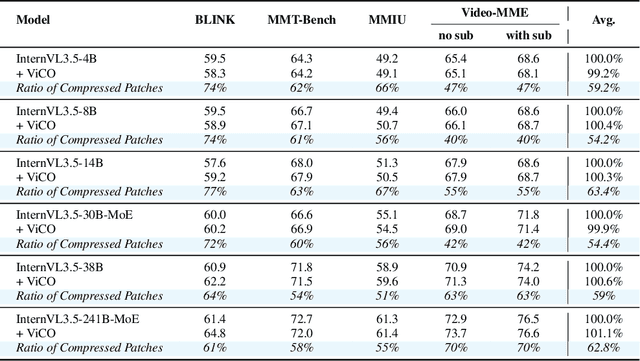
Existing Multimodal Large Language Models (MLLMs) suffer from increased inference costs due to the additional vision tokens introduced by image inputs. In this work, we propose Visual Consistency Learning (ViCO), a novel training algorithm that enables the model to represent images of varying semantic complexities using different numbers of vision tokens. The key idea behind our method is to employ multiple MLP connectors, each with a different image compression ratio, to downsample the vision tokens based on the semantic complexity of the image. During training, we minimize the KL divergence between the responses conditioned on different MLP connectors. At inference time, we introduce an image router, termed Visual Resolution Router (ViR), that automatically selects the appropriate compression rate for each image patch. Compared with existing dynamic high-resolution strategies, which adjust the number of visual tokens based on image resolutions, our method dynamically adapts the number of visual tokens according to semantic complexity. Experimental results demonstrate that our method can reduce the number of vision tokens by up to 50% while maintaining the model's perception, reasoning, and OCR capabilities. We hope this work will contribute to the development of more efficient MLLMs. The code and models will be released to facilitate future research.
PsyLite Technical Report
Jun 26, 2025With the rapid development of digital technology, AI-driven psychological counseling has gradually become an important research direction in the field of mental health. However, existing models still have deficiencies in dialogue safety, detailed scenario handling, and lightweight deployment. To address these issues, this study proposes PsyLite, a lightweight psychological counseling large language model agent developed based on the base model InternLM2.5-7B-chat. Through a two-stage training strategy (hybrid distillation data fine-tuning and ORPO preference optimization), PsyLite enhances the model's deep-reasoning ability, psychological counseling ability, and safe dialogue ability. After deployment using Ollama and Open WebUI, a custom workflow is created with Pipelines. An innovative conditional RAG is designed to introduce crosstalk humor elements at appropriate times during psychological counseling to enhance user experience and decline dangerous requests to strengthen dialogue safety. Evaluations show that PsyLite outperforms the baseline models in the Chinese general evaluation (CEval), psychological counseling professional evaluation (CPsyCounE), and dialogue safety evaluation (SafeDialBench), particularly in psychological counseling professionalism (CPsyCounE score improvement of 47.6\%) and dialogue safety (\safe{} score improvement of 2.4\%). Additionally, the model uses quantization technology (GGUF q4\_k\_m) to achieve low hardware deployment (5GB memory is sufficient for operation), providing a feasible solution for psychological counseling applications in resource-constrained environments.
Point or Line? Using Line-based Representation for Panoptic Symbol Spotting in CAD Drawings
May 29, 2025We study the task of panoptic symbol spotting, which involves identifying both individual instances of countable things and the semantic regions of uncountable stuff in computer-aided design (CAD) drawings composed of vector graphical primitives. Existing methods typically rely on image rasterization, graph construction, or point-based representation, but these approaches often suffer from high computational costs, limited generality, and loss of geometric structural information. In this paper, we propose VecFormer, a novel method that addresses these challenges through line-based representation of primitives. This design preserves the geometric continuity of the original primitive, enabling more accurate shape representation while maintaining a computation-friendly structure, making it well-suited for vector graphic understanding tasks. To further enhance prediction reliability, we introduce a Branch Fusion Refinement module that effectively integrates instance and semantic predictions, resolving their inconsistencies for more coherent panoptic outputs. Extensive experiments demonstrate that our method establishes a new state-of-the-art, achieving 91.1 PQ, with Stuff-PQ improved by 9.6 and 21.2 points over the second-best results under settings with and without prior information, respectively, highlighting the strong potential of line-based representation as a foundation for vector graphic understanding.
CoCoB: Adaptive Collaborative Combinatorial Bandits for Online Recommendation
May 05, 2025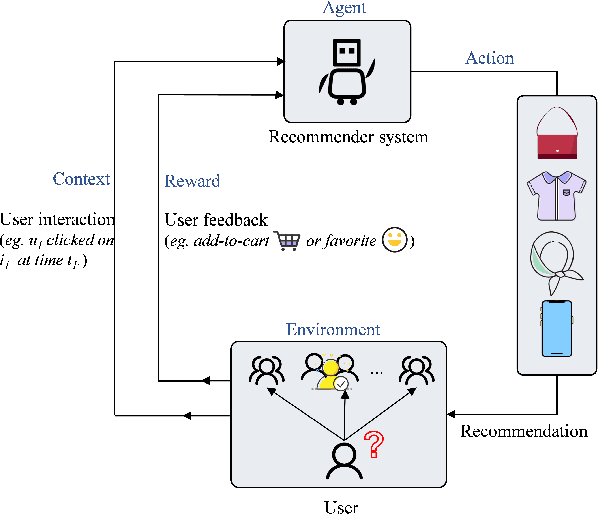

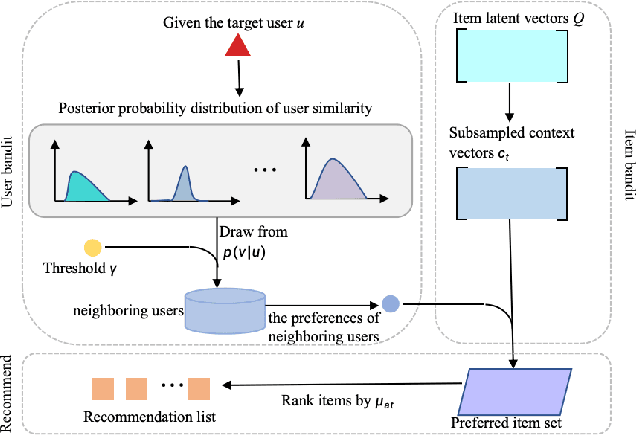

Clustering bandits have gained significant attention in recommender systems by leveraging collaborative information from neighboring users to better capture target user preferences. However, these methods often lack a clear definition of similar users and face challenges when users with unique preferences lack appropriate neighbors. In such cases, relying on divergent preferences of misidentified neighbors can degrade recommendation quality. To address these limitations, this paper proposes an adaptive Collaborative Combinatorial Bandits algorithm (CoCoB). CoCoB employs an innovative two-sided bandit architecture, applying bandit principles to both the user and item sides. The user-bandit employs an enhanced Bayesian model to explore user similarity, identifying neighbors based on a similarity probability threshold. The item-bandit treats items as arms, generating diverse recommendations informed by the user-bandit's output. CoCoB dynamically adapts, leveraging neighbor preferences when available or focusing solely on the target user otherwise. Regret analysis under a linear contextual bandit setting and experiments on three real-world datasets demonstrate CoCoB's effectiveness, achieving an average 2.4% improvement in F1 score over state-of-the-art methods.
ArchCAD-400K: An Open Large-Scale Architectural CAD Dataset and New Baseline for Panoptic Symbol Spotting
Apr 02, 2025Recognizing symbols in architectural CAD drawings is critical for various advanced engineering applications. In this paper, we propose a novel CAD data annotation engine that leverages intrinsic attributes from systematically archived CAD drawings to automatically generate high-quality annotations, thus significantly reducing manual labeling efforts. Utilizing this engine, we construct ArchCAD-400K, a large-scale CAD dataset consisting of 413,062 chunks from 5538 highly standardized drawings, making it over 26 times larger than the largest existing CAD dataset. ArchCAD-400K boasts an extended drawing diversity and broader categories, offering line-grained annotations. Furthermore, we present a new baseline model for panoptic symbol spotting, termed Dual-Pathway Symbol Spotter (DPSS). It incorporates an adaptive fusion module to enhance primitive features with complementary image features, achieving state-of-the-art performance and enhanced robustness. Extensive experiments validate the effectiveness of DPSS, demonstrating the value of ArchCAD-400K and its potential to drive innovation in architectural design and construction.
ViPOcc: Leveraging Visual Priors from Vision Foundation Models for Single-View 3D Occupancy Prediction
Dec 15, 2024Inferring the 3D structure of a scene from a single image is an ill-posed and challenging problem in the field of vision-centric autonomous driving. Existing methods usually employ neural radiance fields to produce voxelized 3D occupancy, lacking instance-level semantic reasoning and temporal photometric consistency. In this paper, we propose ViPOcc, which leverages the visual priors from vision foundation models (VFMs) for fine-grained 3D occupancy prediction. Unlike previous works that solely employ volume rendering for RGB and depth image reconstruction, we introduce a metric depth estimation branch, in which an inverse depth alignment module is proposed to bridge the domain gap in depth distribution between VFM predictions and the ground truth. The recovered metric depth is then utilized in temporal photometric alignment and spatial geometric alignment to ensure accurate and consistent 3D occupancy prediction. Additionally, we also propose a semantic-guided non-overlapping Gaussian mixture sampler for efficient, instance-aware ray sampling, which addresses the redundant and imbalanced sampling issue that still exists in previous state-of-the-art methods. Extensive experiments demonstrate the superior performance of ViPOcc in both 3D occupancy prediction and depth estimation tasks on the KITTI-360 and KITTI Raw datasets. Our code is available at: \url{https://mias.group/ViPOcc}.
STEVE Series: Step-by-Step Construction of Agent Systems in Minecraft
Jun 17, 2024Building an embodied agent system with a large language model (LLM) as its core is a promising direction. Due to the significant costs and uncontrollable factors associated with deploying and training such agents in the real world, we have decided to begin our exploration within the Minecraft environment. Our STEVE Series agents can complete basic tasks in a virtual environment and more challenging tasks such as navigation and even creative tasks, with an efficiency far exceeding previous state-of-the-art methods by a factor of $2.5\times$ to $7.3\times$. We begin our exploration with a vanilla large language model, augmenting it with a vision encoder and an action codebase trained on our collected high-quality dataset STEVE-21K. Subsequently, we enhanced it with a Critic and memory to transform it into a complex system. Finally, we constructed a hierarchical multi-agent system. Our recent work explored how to prune the agent system through knowledge distillation. In the future, we will explore more potential applications of STEVE agents in the real world.
Do We Really Need a Complex Agent System? Distill Embodied Agent into a Single Model
Apr 06, 2024With the power of large language models (LLMs), open-ended embodied agents can flexibly understand human instructions, generate interpretable guidance strategies, and output executable actions. Nowadays, Multi-modal Language Models~(MLMs) integrate multi-modal signals into LLMs, further bringing richer perception to entity agents and allowing embodied agents to perceive world-understanding tasks more delicately. However, existing works: 1) operate independently by agents, each containing multiple LLMs, from perception to action, resulting in gaps between complex tasks and execution; 2) train MLMs on static data, struggling with dynamics in open-ended scenarios; 3) input prior knowledge directly as prompts, suppressing application flexibility. We propose STEVE-2, a hierarchical knowledge distillation framework for open-ended embodied tasks, characterized by 1) a hierarchical system for multi-granular task division, 2) a mirrored distillation method for parallel simulation data, and 3) an extra expert model for bringing additional knowledge into parallel simulation. After distillation, embodied agents can complete complex, open-ended tasks without additional expert guidance, utilizing the performance and knowledge of a versatile MLM. Extensive evaluations on navigation and creation tasks highlight the superior performance of STEVE-2 in open-ended tasks, with $1.4 \times$ - $7.3 \times$ in performance.
Hierarchical Auto-Organizing System for Open-Ended Multi-Agent Navigation
Mar 18, 2024Due to the dynamic and unpredictable open-world setting, navigating complex environments in Minecraft poses significant challenges for multi-agent systems. Agents must interact with the environment and coordinate their actions with other agents to achieve common objectives. However, traditional approaches often struggle to efficiently manage inter-agent communication and task distribution, crucial for effective multi-agent navigation. Furthermore, processing and integrating multi-modal information (such as visual, textual, and auditory data) is essential for agents to comprehend their goals and navigate the environment successfully and fully. To address this issue, we design the HAS framework to auto-organize groups of LLM-based agents to complete navigation tasks. In our approach, we devise a hierarchical auto-organizing navigation system, which is characterized by 1) a hierarchical system for multi-agent organization, ensuring centralized planning and decentralized execution; 2) an auto-organizing and intra-communication mechanism, enabling dynamic group adjustment under subtasks; 3) a multi-modal information platform, facilitating multi-modal perception to perform the three navigation tasks with one system. To assess organizational behavior, we design a series of navigation tasks in the Minecraft environment, which includes searching and exploring. We aim to develop embodied organizations that push the boundaries of embodied AI, moving it towards a more human-like organizational structure.