 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLHA-Net: A Hierarchical Attention Network for Two-View Correspondence Learning
Dec 31, 2025Establishing the correct correspondence of feature points is a fundamental task in computer vision. However, the presence of numerous outliers among the feature points can significantly affect the matching results, reducing the accuracy and robustness of the process. Furthermore, a challenge arises when dealing with a large proportion of outliers: how to ensure the extraction of high-quality information while reducing errors caused by negative samples. To address these issues, in this paper, we propose a novel method called Layer-by-Layer Hierarchical Attention Network, which enhances the precision of feature point matching in computer vision by addressing the issue of outliers. Our method incorporates stage fusion, hierarchical extraction, and an attention mechanism to improve the network's representation capability by emphasizing the rich semantic information of feature points. Specifically, we introduce a layer-by-layer channel fusion module, which preserves the feature semantic information from each stage and achieves overall fusion, thereby enhancing the representation capability of the feature points. Additionally, we design a hierarchical attention module that adaptively captures and fuses global perception and structural semantic information using an attention mechanism. Finally, we propose two architectures to extract and integrate features, thereby improving the adaptability of our network. We conduct experiments on two public datasets, namely YFCC100M and SUN3D, and the results demonstrate that our proposed method outperforms several state-of-the-art techniques in both outlier removal and camera pose estimation. Source code is available at http://www.linshuyuan.com.
MGCA-Net: Multi-Graph Contextual Attention Network for Two-View Correspondence Learning
Dec 29, 2025Two-view correspondence learning is a key task in computer vision, which aims to establish reliable matching relationships for applications such as camera pose estimation and 3D reconstruction. However, existing methods have limitations in local geometric modeling and cross-stage information optimization, which make it difficult to accurately capture the geometric constraints of matched pairs and thus reduce the robustness of the model. To address these challenges, we propose a Multi-Graph Contextual Attention Network (MGCA-Net), which consists of a Contextual Geometric Attention (CGA) module and a Cross-Stage Multi-Graph Consensus (CSMGC) module. Specifically, CGA dynamically integrates spatial position and feature information via an adaptive attention mechanism and enhances the capability to capture both local and global geometric relationships. Meanwhile, CSMGC establishes geometric consensus via a cross-stage sparse graph network, ensuring the consistency of geometric information across different stages. Experimental results on two representative YFCC100M and SUN3D datasets show that MGCA-Net significantly outperforms existing SOTA methods in the outlier rejection and camera pose estimation tasks. Source code is available at http://www.linshuyuan.com.
SRLCG: Self-Rectified Large-Scale Code Generation with Multidimensional Chain-of-Thought and Dynamic Backtracking
Apr 01, 2025Large language models (LLMs) have revolutionized code generation, significantly enhancing developer productivity. However, for a vast number of users with minimal coding knowledge, LLMs provide little support, as they primarily generate isolated code snippets rather than complete, large-scale project code. Without coding expertise, these users struggle to interpret, modify, and iteratively refine the outputs of LLMs, making it impossible to assemble a complete project. To address this issue, we propose Self-Rectified Large-Scale Code Generator (SRLCG), a framework that generates complete multi-file project code from a single prompt. SRLCG employs a novel multidimensional chain-of-thought (CoT) and self-rectification to guide LLMs in generating correct and robust code files, then integrates them into a complete and coherent project using our proposed dynamic backtracking algorithm. Experimental results show that SRLCG generates code 15x longer than DeepSeek-V3, 16x longer than GPT-4, and at least 10x longer than other leading CoT-based baselines. Furthermore, they confirm its improved correctness, robustness, and performance compared to baselines in large-scale code generation.
TSG: Target-Selective Gradient Backprop for Probing CNN Visual Saliency
Oct 11, 2021

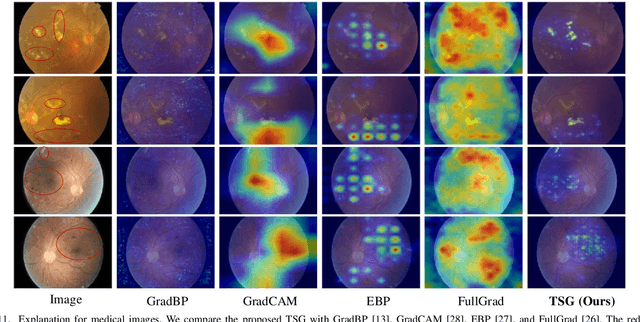
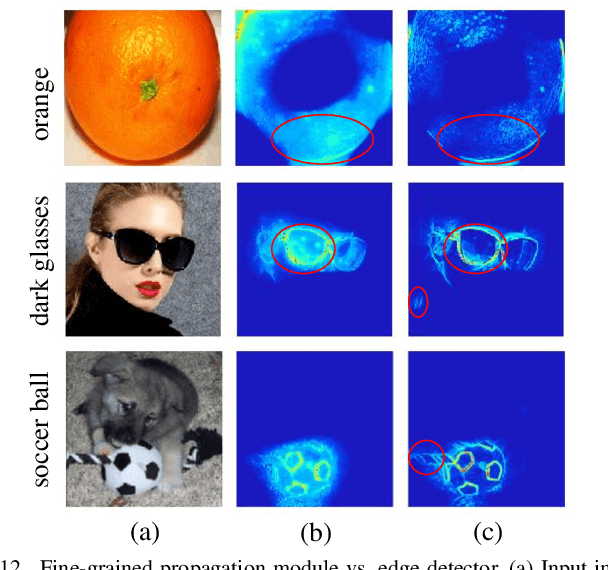
The explanation for deep neural networks has drawn extensive attention in the deep learning community over the past few years. In this work, we study the visual saliency, a.k.a. visual explanation, to interpret convolutional neural networks. Compared to iteration based saliency methods, single backward pass based saliency methods benefit from faster speed and are widely used in downstream visual tasks. Thus our work focuses on single backward pass approaches. However, existing methods in this category struggle to successfully produce fine-grained saliency maps concentrating on specific target classes. That said, producing faithful saliency maps satisfying both target-selectiveness and fine-grainedness using a single backward pass is a challenging problem in the field. To mitigate this problem, we revisit the gradient flow inside the network, and find that the entangled semantics and original weights may disturb the propagation of target-relevant saliency. Inspired by those observations, we propose a novel visual saliency framework, termed Target-Selective Gradient (TSG) backprop, which leverages rectification operations to effectively emphasize target classes and further efficiently propagate the saliency to the input space, thereby generating target-selective and fine-grained saliency maps. The proposed TSG consists of two components, namely, TSG-Conv and TSG-FC, which rectify the gradients for convolutional layers and fully-connected layers, respectively. Thorough qualitative and quantitative experiments on ImageNet and Pascal VOC show that the proposed framework achieves more accurate and reliable results than other competitive methods.
Robust Visual Tracking via Statistical Positive Sample Generation and Gradient Aware Learning
Nov 09, 2020
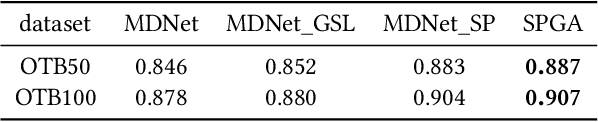
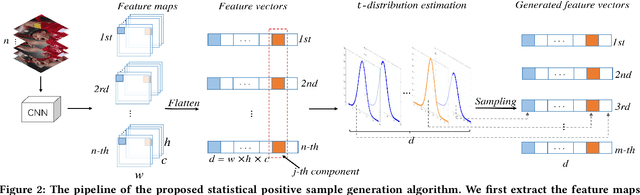
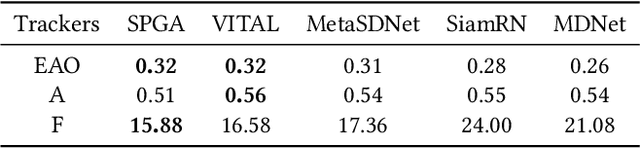
In recent years, Convolutional Neural Network (CNN) based trackers have achieved state-of-the-art performance on multiple benchmark datasets. Most of these trackers train a binary classifier to distinguish the target from its background. However, they suffer from two limitations. Firstly, these trackers cannot effectively handle significant appearance variations due to the limited number of positive samples. Secondly, there exists a significant imbalance of gradient contributions between easy and hard samples, where the easy samples usually dominate the computation of gradient. In this paper, we propose a robust tracking method via Statistical Positive sample generation and Gradient Aware learning (SPGA) to address the above two limitations. To enrich the diversity of positive samples, we present an effective and efficient statistical positive sample generation algorithm to generate positive samples in the feature space. Furthermore, to handle the issue of imbalance between easy and hard samples, we propose a gradient sensitive loss to harmonize the gradient contributions between easy and hard samples. Extensive experiments on three challenging benchmark datasets including OTB50, OTB100 and VOT2016 demonstrate that the proposed SPGA performs favorably against several state-of-the-art trackers.
* 6 pages
Correlation filter tracking with adaptive proposal selection for accurate scale estimation
Jul 14, 2020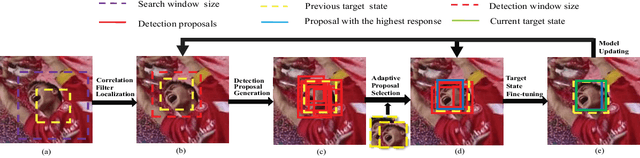
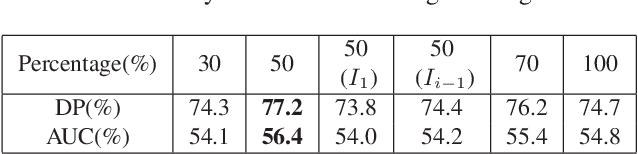
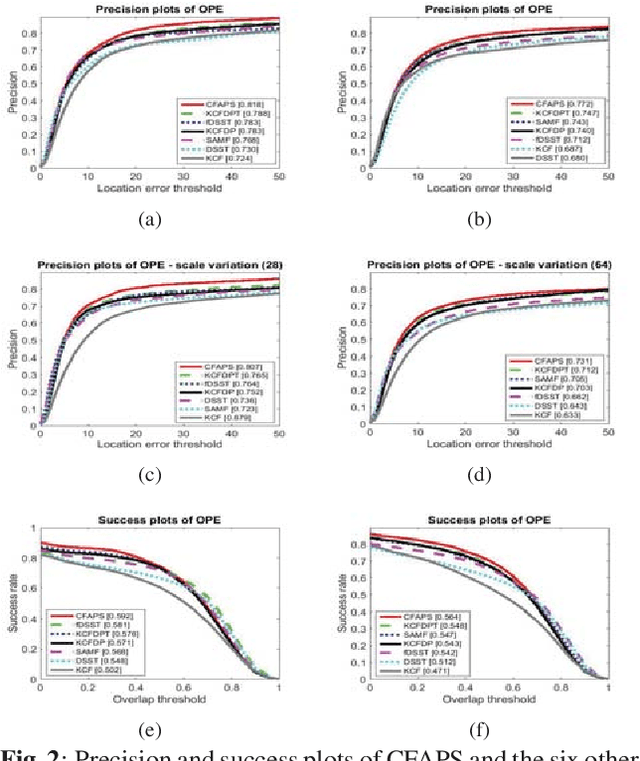
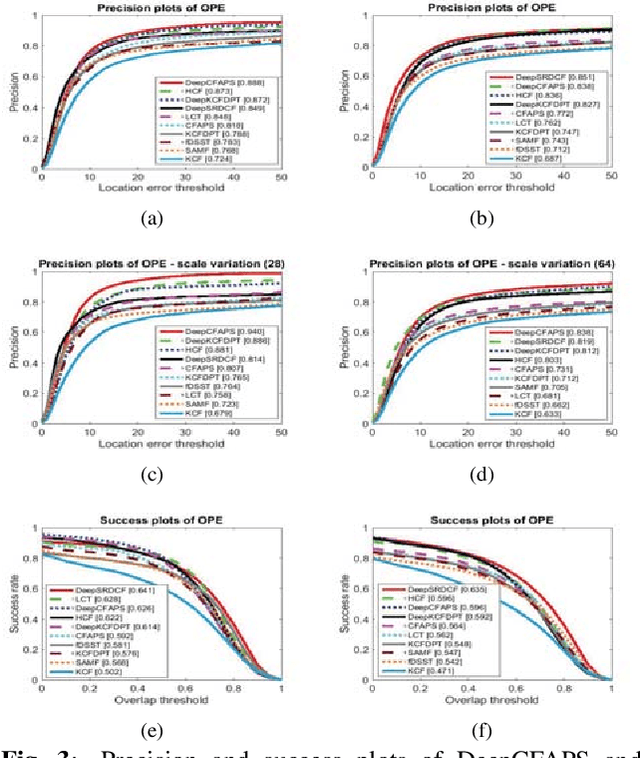
Recently, some correlation filter based trackers with detection proposals have achieved state-of-the-art tracking results. However, a large number of redundant proposals given by the proposal generator may degrade the performance and speed of these trackers. In this paper, we propose an adaptive proposal selection algorithm which can generate a small number of high-quality proposals to handle the problem of scale variations for visual object tracking. Specifically, we firstly utilize the color histograms in the HSV color space to represent the instances (i.e., the initial target in the first frame and the predicted target in the previous frame) and proposals. Then, an adaptive strategy based on the color similarity is formulated to select high-quality proposals. We further integrate the proposed adaptive proposal selection algorithm with coarse-to-fine deep features to validate the generalization and efficiency of the proposed tracker. Experiments on two benchmark datasets demonstrate that the proposed algorithm performs favorably against several state-of-the-art trackers.
Asynchronous Tracking-by-Detection on Adaptive Time Surfaces for Event-based Object Tracking
Feb 13, 2020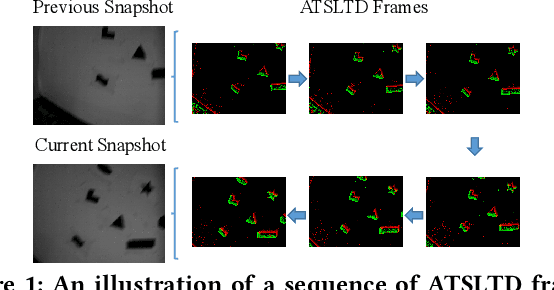


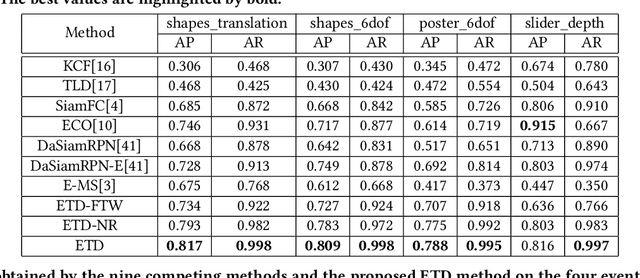
Event cameras, which are asynchronous bio-inspired vision sensors, have shown great potential in a variety of situations, such as fast motion and low illumination scenes. However, most of the event-based object tracking methods are designed for scenarios with untextured objects and uncluttered backgrounds. There are few event-based object tracking methods that support bounding box-based object tracking. The main idea behind this work is to propose an asynchronous Event-based Tracking-by-Detection (ETD) method for generic bounding box-based object tracking. To achieve this goal, we present an Adaptive Time-Surface with Linear Time Decay (ATSLTD) event-to-frame conversion algorithm, which asynchronously and effectively warps the spatio-temporal information of asynchronous retinal events to a sequence of ATSLTD frames with clear object contours. We feed the sequence of ATSLTD frames to the proposed ETD method to perform accurate and efficient object tracking, which leverages the high temporal resolution property of event cameras. We compare the proposed ETD method with seven popular object tracking methods, that are based on conventional cameras or event cameras, and two variants of ETD. The experimental results show the superiority of the proposed ETD method in handling various challenging environments.
* 9 pages, 5 figures
DSNet: Deep and Shallow Feature Learning for Efficient Visual Tracking
Nov 06, 2018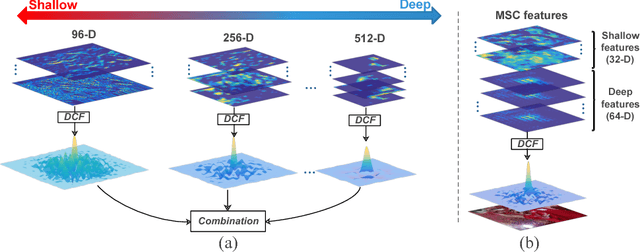
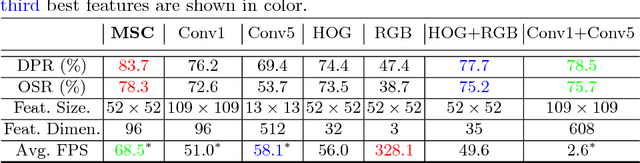
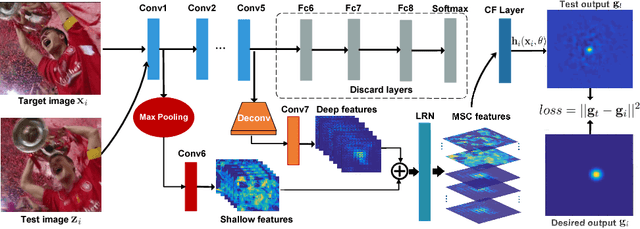
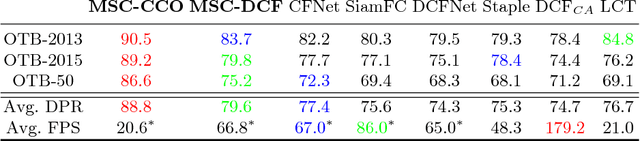
In recent years, Discriminative Correlation Filter (DCF) based tracking methods have achieved great success in visual tracking. However, the multi-resolution convolutional feature maps trained from other tasks like image classification, cannot be naturally used in the conventional DCF formulation. Furthermore, these high-dimensional feature maps significantly increase the tracking complexity and thus limit the tracking speed. In this paper, we present a deep and shallow feature learning network, namely DSNet, to learn the multi-level same-resolution compressed (MSC) features for efficient online tracking, in an end-to-end offline manner. Specifically, the proposed DSNet compresses multi-level convolutional features to uniform spatial resolution features. The learned MSC features effectively encode both appearance and semantic information of objects in the same-resolution feature maps, thus enabling an elegant combination of the MSC features with any DCF-based methods. Additionally, a channel reliability measurement (CRM) method is presented to further refine the learned MSC features. We demonstrate the effectiveness of the MSC features learned from the proposed DSNet on two DCF tracking frameworks: the basic DCF framework and the continuous convolution operator framework. Extensive experiments show that the learned MSC features have the appealing advantage of allowing the equipped DCF-based tracking methods to perform favorably against the state-of-the-art methods while running at high frame rates.