 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Strategy Invention for Confluence of Term Rewrite Systems
Nov 10, 2024



Term rewriting plays a crucial role in software verification and compiler optimization. With dozens of highly parameterizable techniques developed to prove various system properties, automatic term rewriting tools work in an extensive parameter space. This complexity exceeds human capacity for parameter selection, motivating an investigation into automated strategy invention. In this paper, we focus on confluence, an important property of term rewrite systems, and apply machine learning to develop the first learning-guided automatic confluence prover. Moreover, we randomly generate a large dataset to analyze confluence for term rewrite systems. Our results focus on improving the state-of-the-art automatic confluence prover CSI: When equipped with our invented strategies, it surpasses its human-designed strategies both on the augmented dataset and on the original human-created benchmark dataset Cops, proving/disproving the confluence of several term rewrite systems for which no automated proofs were known before.
Learning Rules Explaining Interactive Theorem Proving Tactic Prediction
Nov 02, 2024Formally verifying the correctness of mathematical proofs is more accessible than ever, however, the learning curve remains steep for many of the state-of-the-art interactive theorem provers (ITP). Deriving the most appropriate subsequent proof step, and reasoning about it, given the multitude of possibilities, remains a daunting task for novice users. To improve the situation, several investigations have developed machine learning based guidance for tactic selection. Such approaches struggle to learn non-trivial relationships between the chosen tactic and the structure of the proof state and represent them as symbolic expressions. To address these issues we (i) We represent the problem as an Inductive Logic Programming (ILP) task, (ii) Using the ILP representation we enriched the feature space by encoding additional, computationally expensive properties as background knowledge predicates, (iii) We use this enriched feature space to learn rules explaining when a tactic is applicable to a given proof state, (iv) we use the learned rules to filter the output of an existing tactic selection approach and empirically show improvement over the non-filtering approaches.
Deep Reinforcement Learning for Distributed Dynamic Coordinated Beamforming in Massive MIMO Cellular Networks
Mar 24, 2023
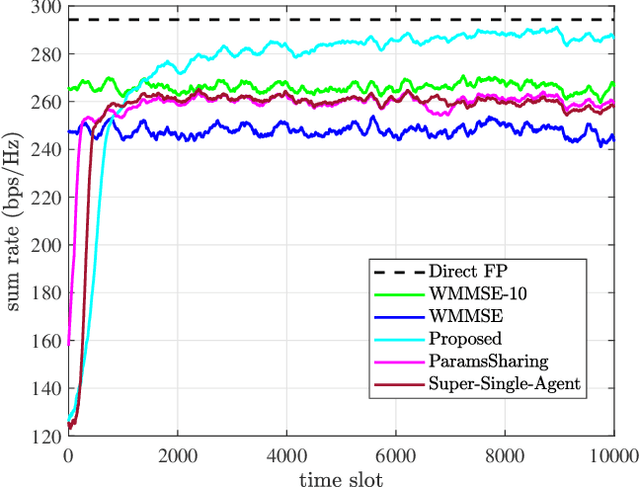
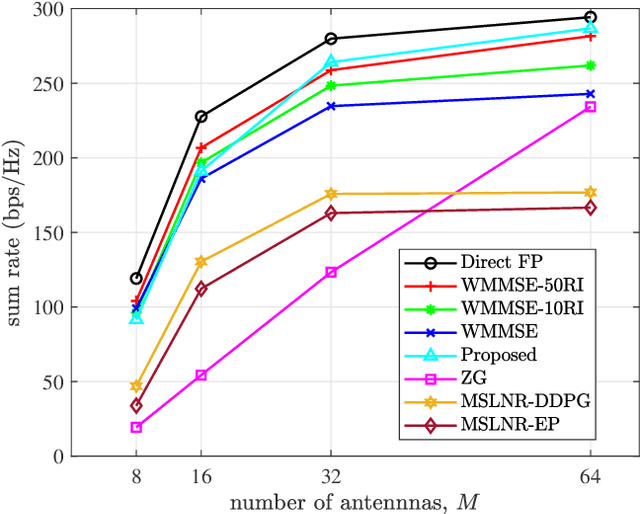
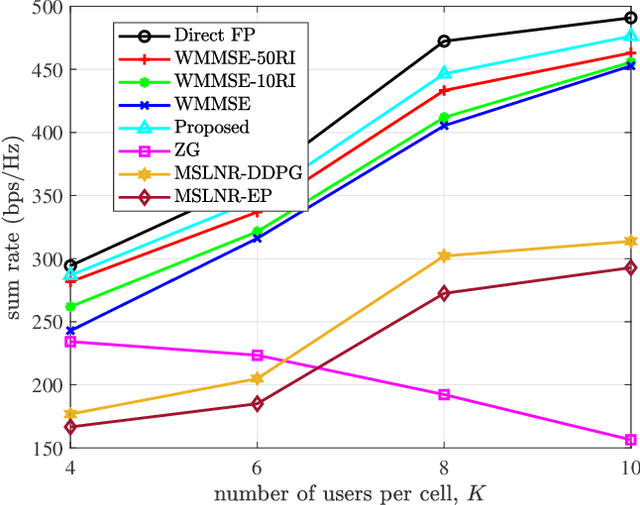
To accommodate the explosive wireless traffics, massive multiple-input multiple-output (MIMO) is regarded as one of the key enabling technologies for next-generation communication systems. In massive MIMO cellular networks, coordinated beamforming (CBF), which jointly designs the beamformers of multiple base stations (BSs), is an efficient method to enhance the network performance. In this paper, we investigate the sum rate maximization problem in a massive MIMO mobile cellular network, where in each cell a multi-antenna BS serves multiple mobile users simultaneously via downlink beamforming. Although existing optimization-based CBF algorithms can provide near-optimal solutions, they require realtime and global channel state information (CSI), in addition to their high computation complexity. It is almost impossible to apply them in practical wireless networks, especially highly dynamic mobile cellular networks. Motivated by this, we propose a deep reinforcement learning based distributed dynamic coordinated beamforming (DDCBF) framework, which enables each BS to determine the beamformers with only local CSI and some historical information from other BSs.Besides, the beamformers can be calculated with a considerably lower computational complexity by exploiting neural networks and expert knowledge, i.e., a solution structure observed from the iterative procedure of the weighted minimum mean square error (WMMSE) algorithm. Moreover, we provide extensive numerical simulations to validate the effectiveness of the proposed DRL-based approach. With lower computational complexity and less required information, the results show that the proposed approach can achieve comparable performance to the centralized iterative optimization algorithms.
TSG: Target-Selective Gradient Backprop for Probing CNN Visual Saliency
Oct 11, 2021

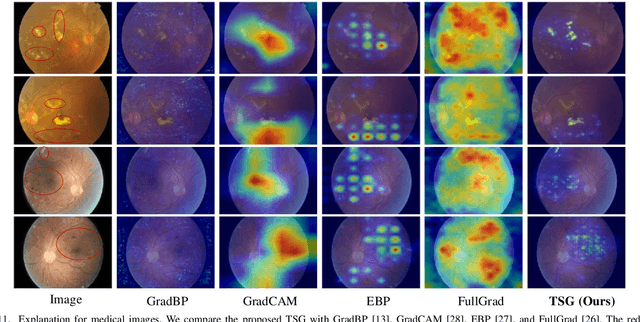
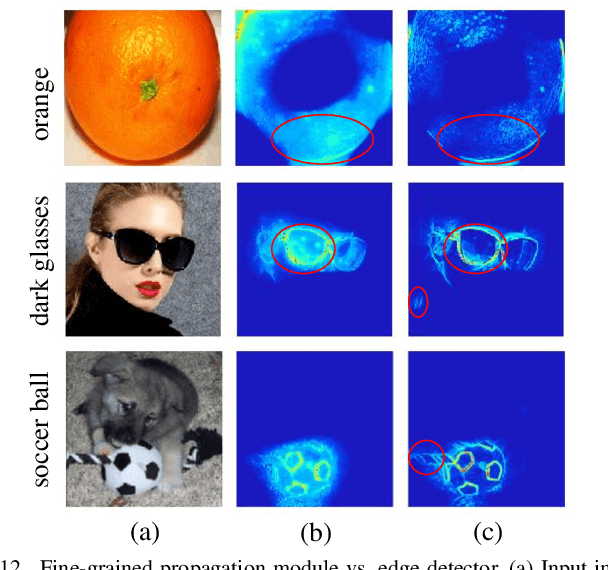
The explanation for deep neural networks has drawn extensive attention in the deep learning community over the past few years. In this work, we study the visual saliency, a.k.a. visual explanation, to interpret convolutional neural networks. Compared to iteration based saliency methods, single backward pass based saliency methods benefit from faster speed and are widely used in downstream visual tasks. Thus our work focuses on single backward pass approaches. However, existing methods in this category struggle to successfully produce fine-grained saliency maps concentrating on specific target classes. That said, producing faithful saliency maps satisfying both target-selectiveness and fine-grainedness using a single backward pass is a challenging problem in the field. To mitigate this problem, we revisit the gradient flow inside the network, and find that the entangled semantics and original weights may disturb the propagation of target-relevant saliency. Inspired by those observations, we propose a novel visual saliency framework, termed Target-Selective Gradient (TSG) backprop, which leverages rectification operations to effectively emphasize target classes and further efficiently propagate the saliency to the input space, thereby generating target-selective and fine-grained saliency maps. The proposed TSG consists of two components, namely, TSG-Conv and TSG-FC, which rectify the gradients for convolutional layers and fully-connected layers, respectively. Thorough qualitative and quantitative experiments on ImageNet and Pascal VOC show that the proposed framework achieves more accurate and reliable results than other competitive methods.
Online Machine Learning Techniques for Coq: A Comparison
Apr 12, 2021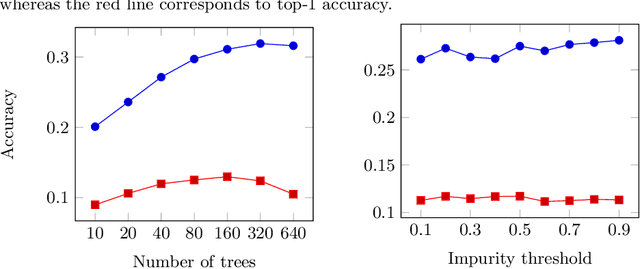
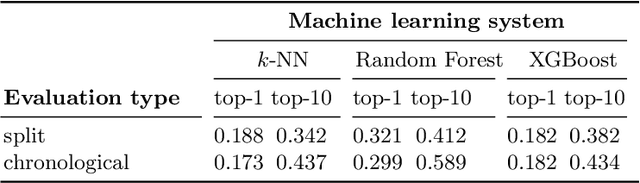
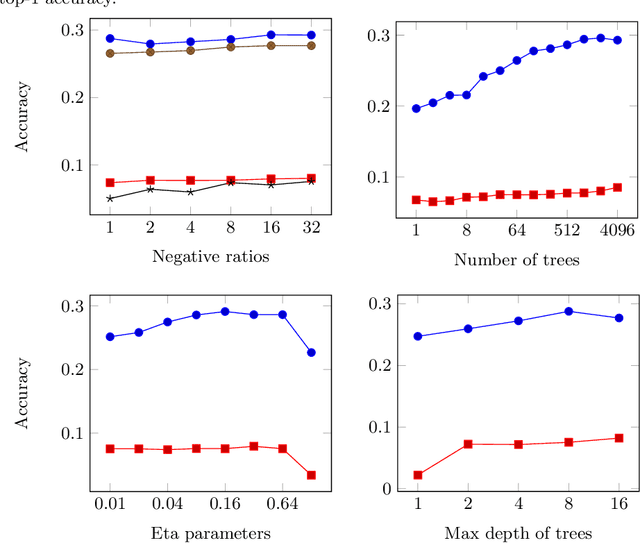
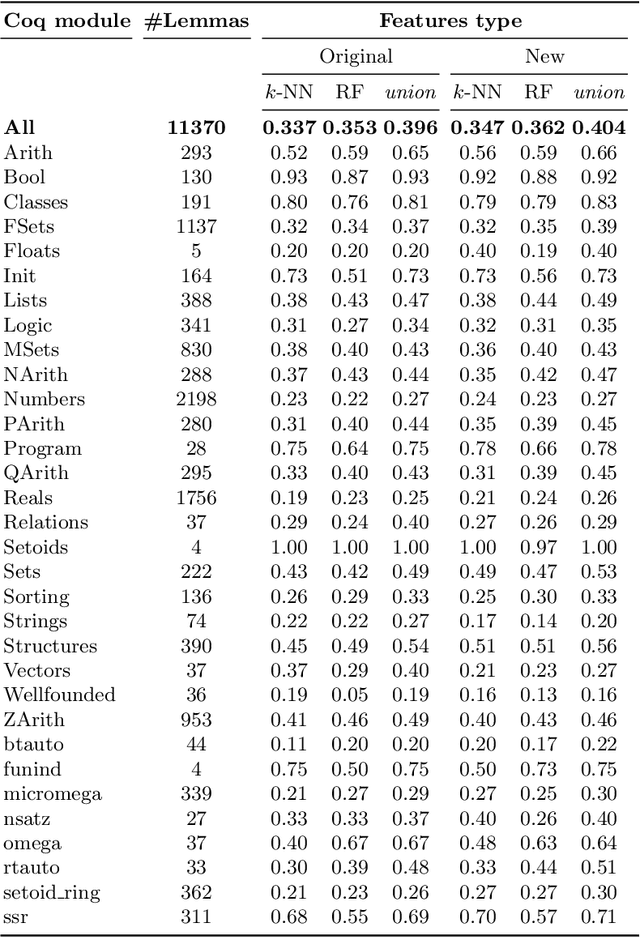
We present a comparison of several online machine learning techniques for tactical learning and proving in the Coq proof assistant. This work builds on top of Tactician, a plugin for Coq that learns from proofs written by the user to synthesize new proofs. This learning happens in an online manner -- meaning that Tactician's machine learning model is updated immediately every time the user performs a step in an interactive proof. This has important advantages compared to the more studied offline learning systems: (1) it provides the user with a seamless, interactive experience with Tactician and, (2) it takes advantage of locality of proof similarity, which means that proofs similar to the current proof are likely to be found close by. We implement two online methods, namely approximate $k$-nearest neighbors based on locality sensitive hashing forests and random decision forests. Additionally, we conduct experiments with gradient boosted trees in an offline setting using XGBoost. We compare the relative performance of Tactician using these three learning methods on Coq's standard library.
Learning Object Scale With Click Supervision for Object Detection
Feb 20, 2020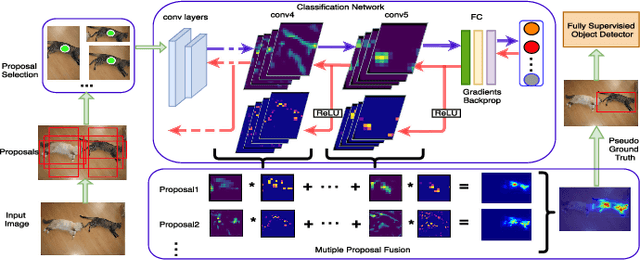



Weakly-supervised object detection has recently attracted increasing attention since it only requires image-levelannotations. However, the performance obtained by existingmethods is still far from being satisfactory compared with fully-supervised object detection methods. To achieve a good trade-off between annotation cost and object detection performance,we propose a simple yet effective method which incorporatesCNN visualization with click supervision to generate the pseudoground-truths (i.e., bounding boxes). These pseudo ground-truthscan be used to train a fully-supervised detector. To estimatethe object scale, we firstly adopt a proposal selection algorithmto preserve high-quality proposals, and then generate ClassActivation Maps (CAMs) for these preserved proposals by theproposed CNN visualization algorithm called Spatial AttentionCAM. Finally, we fuse these CAMs together to generate pseudoground-truths and train a fully-supervised object detector withthese ground-truths. Experimental results on the PASCAL VOC2007 and VOC 2012 datasets show that the proposed methodcan obtain much higher accuracy for estimating the object scale,compared with the state-of-the-art image-level based methodsand the center-click based method