 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhrase Decoupling Cross-Modal Hierarchical Matching and Progressive Position Correction for Visual Grounding
Paper and Code
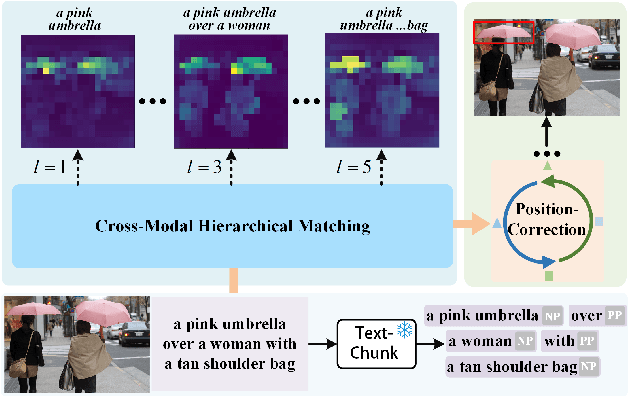

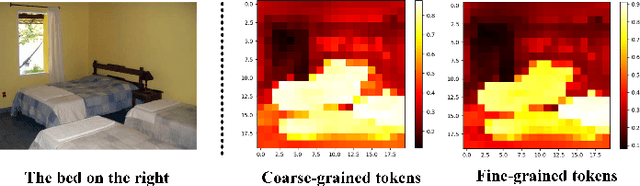
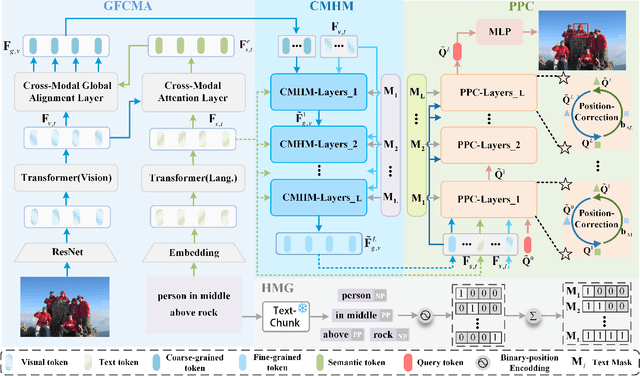
Visual grounding has attracted wide attention thanks to its broad application in various visual language tasks. Although visual grounding has made significant research progress, existing methods ignore the promotion effect of the association between text and image features at different hierarchies on cross-modal matching. This paper proposes a Phrase Decoupling Cross-Modal Hierarchical Matching and Progressive Position Correction Visual Grounding method. It first generates a mask through decoupled sentence phrases, and a text and image hierarchical matching mechanism is constructed, highlighting the role of association between different hierarchies in cross-modal matching. In addition, a corresponding target object position progressive correction strategy is defined based on the hierarchical matching mechanism to achieve accurate positioning for the target object described in the text. This method can continuously optimize and adjust the bounding box position of the target object as the certainty of the text description of the target object improves. This design explores the association between features at different hierarchies and highlights the role of features related to the target object and its position in target positioning. The proposed method is validated on different datasets through experiments, and its superiority is verified by the performance comparison with the state-of-the-art methods.