 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopoMesh: High-Fidelity Mesh Autoencoding via Topological Unification
Mar 25, 2026The dominant paradigm for high-fidelity 3D generation relies on a VAE-Diffusion pipeline, where the VAE's reconstruction capability sets a firm upper bound on generation quality. A fundamental challenge limiting existing VAEs is the representation mismatch between ground-truth meshes and network predictions: GT meshes have arbitrary, variable topology, while VAEs typically predict fixed-structure implicit fields (\eg, SDF on regular grids). This inherent misalignment prevents establishing explicit mesh-level correspondences, forcing prior work to rely on indirect supervision signals such as SDF or rendering losses. Consequently, fine geometric details, particularly sharp features, are poorly preserved during reconstruction. To address this, we introduce TopoMesh, a sparse voxel-based VAE that unifies both GT and predicted meshes under a shared Dual Marching Cubes (DMC) topological framework. Specifically, we convert arbitrary input meshes into DMC-compliant representations via a remeshing algorithm that preserves sharp edges using an L$\infty$ distance metric. Our decoder outputs meshes in the same DMC format, ensuring that both predicted and target meshes share identical topological structures. This establishes explicit correspondences at the vertex and face level, allowing us to derive explicit mesh-level supervision signals for topology, vertex positions, and face orientations with clear gradients. Our sparse VAE architecture employs this unified framework and is trained with Teacher Forcing and progressive resolution training for stable and efficient convergence. Extensive experiments demonstrate that TopoMesh significantly outperforms existing VAEs in reconstruction fidelity, achieving superior preservation of sharp features and geometric details.
SoLA-Vision: Fine-grained Layer-wise Linear Softmax Hybrid Attention
Jan 16, 2026Standard softmax self-attention excels in vision tasks but incurs quadratic complexity O(N^2), limiting high-resolution deployment. Linear attention reduces the cost to O(N), yet its compressed state representations can impair modeling capacity and accuracy. We present an analytical study that contrasts linear and softmax attention for visual representation learning from a layer-stacking perspective. We further conduct systematic experiments on layer-wise hybridization patterns of linear and softmax attention. Our results show that, compared with rigid intra-block hybrid designs, fine-grained layer-wise hybridization can match or surpass performance while requiring fewer softmax layers. Building on these findings, we propose SoLA-Vision (Softmax-Linear Attention Vision), a flexible layer-wise hybrid attention backbone that enables fine-grained control over how linear and softmax attention are integrated. By strategically inserting a small number of global softmax layers, SoLA-Vision achieves a strong trade-off between accuracy and computational cost. On ImageNet-1K, SoLA-Vision outperforms purely linear and other hybrid attention models. On dense prediction tasks, it consistently surpasses strong baselines by a considerable margin. Code will be released.
Integrating Diverse Assignment Strategies into DETRs
Jan 14, 2026Label assignment is a critical component in object detectors, particularly within DETR-style frameworks where the one-to-one matching strategy, despite its end-to-end elegance, suffers from slow convergence due to sparse supervision. While recent works have explored one-to-many assignments to enrich supervisory signals, they often introduce complex, architecture-specific modifications and typically focus on a single auxiliary strategy, lacking a unified and scalable design. In this paper, we first systematically investigate the effects of ``one-to-many'' supervision and reveal a surprising insight that performance gains are driven not by the sheer quantity of supervision, but by the diversity of the assignment strategies employed. This finding suggests that a more elegant, parameter-efficient approach is attainable. Building on this insight, we propose LoRA-DETR, a flexible and lightweight framework that seamlessly integrates diverse assignment strategies into any DETR-style detector. Our method augments the primary network with multiple Low-Rank Adaptation (LoRA) branches during training, each instantiating a different one-to-many assignment rule. These branches act as auxiliary modules that inject rich, varied supervisory gradients into the main model and are discarded during inference, thus incurring no additional computational cost. This design promotes robust joint optimization while maintaining the architectural simplicity of the original detector. Extensive experiments on different baselines validate the effectiveness of our approach. Our work presents a new paradigm for enhancing detectors, demonstrating that diverse ``one-to-many'' supervision can be integrated to achieve state-of-the-art results without compromising model elegance.
Dora: Sampling and Benchmarking for 3D Shape Variational Auto-Encoders
Dec 24, 2024



Recent 3D content generation pipelines commonly employ Variational Autoencoders (VAEs) to encode shapes into compact latent representations for diffusion-based generation. However, the widely adopted uniform point sampling strategy in Shape VAE training often leads to a significant loss of geometric details, limiting the quality of shape reconstruction and downstream generation tasks. We present Dora-VAE, a novel approach that enhances VAE reconstruction through our proposed sharp edge sampling strategy and a dual cross-attention mechanism. By identifying and prioritizing regions with high geometric complexity during training, our method significantly improves the preservation of fine-grained shape features. Such sampling strategy and the dual attention mechanism enable the VAE to focus on crucial geometric details that are typically missed by uniform sampling approaches. To systematically evaluate VAE reconstruction quality, we additionally propose Dora-bench, a benchmark that quantifies shape complexity through the density of sharp edges, introducing a new metric focused on reconstruction accuracy at these salient geometric features. Extensive experiments on the Dora-bench demonstrate that Dora-VAE achieves comparable reconstruction quality to the state-of-the-art dense XCube-VAE while requiring a latent space at least 8$\times$ smaller (1,280 vs. > 10,000 codes). We will release our code and benchmark dataset to facilitate future research in 3D shape modeling.
VQ-Map: Bird's-Eye-View Map Layout Estimation in Tokenized Discrete Space via Vector Quantization
Nov 03, 2024



Bird's-eye-view (BEV) map layout estimation requires an accurate and full understanding of the semantics for the environmental elements around the ego car to make the results coherent and realistic. Due to the challenges posed by occlusion, unfavourable imaging conditions and low resolution, \emph{generating} the BEV semantic maps corresponding to corrupted or invalid areas in the perspective view (PV) is appealing very recently. \emph{The question is how to align the PV features with the generative models to facilitate the map estimation}. In this paper, we propose to utilize a generative model similar to the Vector Quantized-Variational AutoEncoder (VQ-VAE) to acquire prior knowledge for the high-level BEV semantics in the tokenized discrete space. Thanks to the obtained BEV tokens accompanied with a codebook embedding encapsulating the semantics for different BEV elements in the groundtruth maps, we are able to directly align the sparse backbone image features with the obtained BEV tokens from the discrete representation learning based on a specialized token decoder module, and finally generate high-quality BEV maps with the BEV codebook embedding serving as a bridge between PV and BEV. We evaluate the BEV map layout estimation performance of our model, termed VQ-Map, on both the nuScenes and Argoverse benchmarks, achieving 62.2/47.6 mean IoU for surround-view/monocular evaluation on nuScenes, as well as 73.4 IoU for monocular evaluation on Argoverse, which all set a new record for this map layout estimation task. The code and models are available on \url{https://github.com/Z1zyw/VQ-Map}.
3D Gaussian Editing with A Single Image
Aug 14, 2024



The modeling and manipulation of 3D scenes captured from the real world are pivotal in various applications, attracting growing research interest. While previous works on editing have achieved interesting results through manipulating 3D meshes, they often require accurately reconstructed meshes to perform editing, which limits their application in 3D content generation. To address this gap, we introduce a novel single-image-driven 3D scene editing approach based on 3D Gaussian Splatting, enabling intuitive manipulation via directly editing the content on a 2D image plane. Our method learns to optimize the 3D Gaussians to align with an edited version of the image rendered from a user-specified viewpoint of the original scene. To capture long-range object deformation, we introduce positional loss into the optimization process of 3D Gaussian Splatting and enable gradient propagation through reparameterization. To handle occluded 3D Gaussians when rendering from the specified viewpoint, we build an anchor-based structure and employ a coarse-to-fine optimization strategy capable of handling long-range deformation while maintaining structural stability. Furthermore, we design a novel masking strategy to adaptively identify non-rigid deformation regions for fine-scale modeling. Extensive experiments show the effectiveness of our method in handling geometric details, long-range, and non-rigid deformation, demonstrating superior editing flexibility and quality compared to previous approaches.
PI3D: Efficient Text-to-3D Generation with Pseudo-Image Diffusion
Dec 14, 2023



In this paper, we introduce PI3D, a novel and efficient framework that utilizes the pre-trained text-to-image diffusion models to generate high-quality 3D shapes in minutes. On the one hand, it fine-tunes a pre-trained 2D diffusion model into a 3D diffusion model, enabling both 3D generative capabilities and generalization derived from the 2D model. On the other, it utilizes score distillation sampling of 2D diffusion models to quickly improve the quality of the sampled 3D shapes. PI3D enables the migration of knowledge from image to triplane generation by treating it as a set of pseudo-images. We adapt the modules in the pre-training model to enable hybrid training using pseudo and real images, which has proved to be a well-established strategy for improving generalizability. The efficiency of PI3D is highlighted by its ability to sample diverse 3D models in seconds and refine them in minutes. The experimental results confirm the advantages of PI3D over existing methods based on either 3D diffusion models or lifting 2D diffusion models in terms of fast generation of 3D consistent and high-quality models. The proposed PI3D stands as a promising advancement in the field of text-to-3D generation, and we hope it will inspire more research into 3D generation leveraging the knowledge in both 2D and 3D data.
Open-Vocabulary One-Stage Detection with Hierarchical Visual-Language Knowledge Distillation
Mar 20, 2022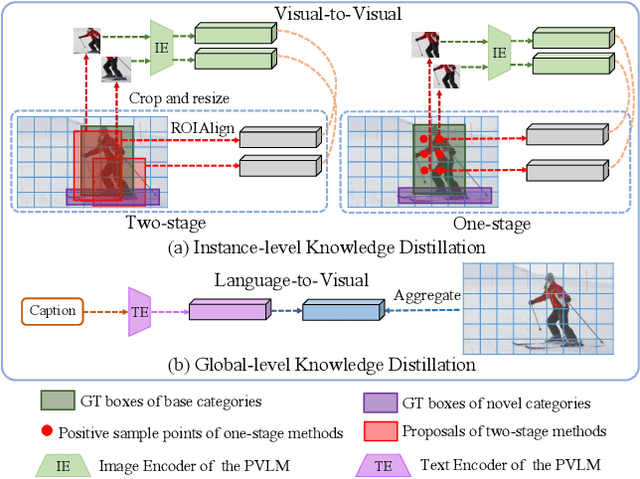
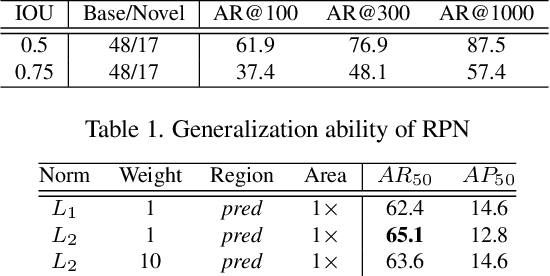
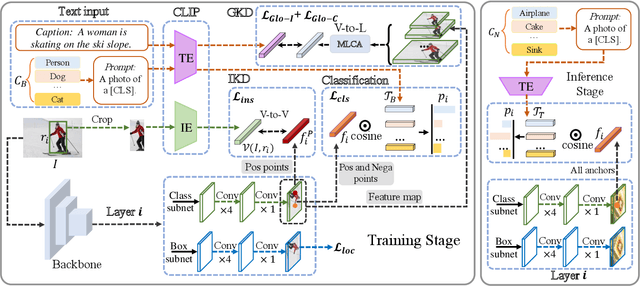
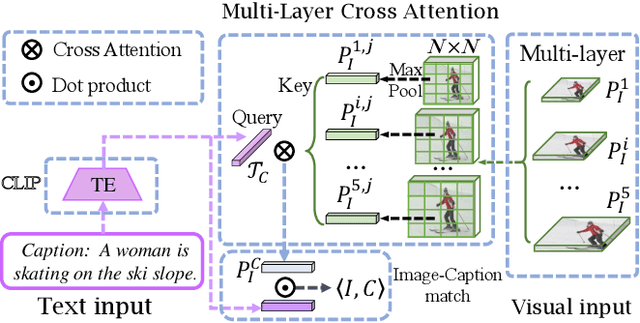
Open-vocabulary object detection aims to detect novel object categories beyond the training set. The advanced open-vocabulary two-stage detectors employ instance-level visual-to-visual knowledge distillation to align the visual space of the detector with the semantic space of the Pre-trained Visual-Language Model (PVLM). However, in the more efficient one-stage detector, the absence of class-agnostic object proposals hinders the knowledge distillation on unseen objects, leading to severe performance degradation. In this paper, we propose a hierarchical visual-language knowledge distillation method, i.e., HierKD, for open-vocabulary one-stage detection. Specifically, a global-level knowledge distillation is explored to transfer the knowledge of unseen categories from the PVLM to the detector. Moreover, we combine the proposed global-level knowledge distillation and the common instance-level knowledge distillation to learn the knowledge of seen and unseen categories simultaneously. Extensive experiments on MS-COCO show that our method significantly surpasses the previous best one-stage detector with 11.9\% and 6.7\% $AP_{50}$ gains under the zero-shot detection and generalized zero-shot detection settings, and reduces the $AP_{50}$ performance gap from 14\% to 7.3\% compared to the best two-stage detector.
Semi-interactive Attention Network for Answer Understanding in Reverse-QA
Jan 12, 2019
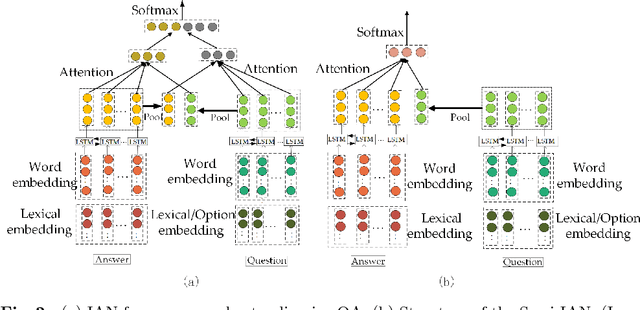
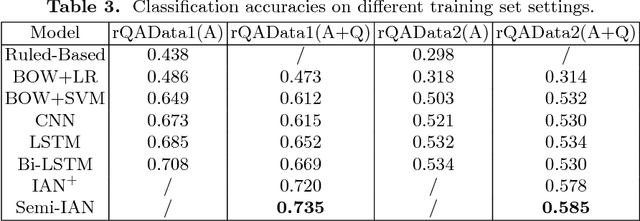
Question answering (QA) is an important natural language processing (NLP) task and has received much attention in academic research and industry communities. Existing QA studies assume that questions are raised by humans and answers are generated by machines. Nevertheless, in many real applications, machines are also required to determine human needs or perceive human states. In such scenarios, machines may proactively raise questions and humans supply answers. Subsequently, machines should attempt to understand the true meaning of these answers. This new QA approach is called reverse-QA (rQA) throughout this paper. In this work, the human answer understanding problem is investigated and solved by classifying the answers into predefined answer-label categories (e.g., True, False, Uncertain). To explore the relationships between questions and answers, we use the interactive attention network (IAN) model and propose an improved structure called semi-interactive attention network (Semi-IAN). Two Chinese data sets for rQA are compiled. We evaluate several conventional text classification models for comparison, and experimental results indicate the promising performance of our proposed models.