 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple Yet Effective Approach for Diversified Session-Based Recommendation
Mar 30, 2024



Session-based recommender systems (SBRSs) have become extremely popular in view of the core capability of capturing short-term and dynamic user preferences. However, most SBRSs primarily maximize recommendation accuracy but ignore user minor preferences, thus leading to filter bubbles in the long run. Only a handful of works, being devoted to improving diversity, depend on unique model designs and calibrated loss functions, which cannot be easily adapted to existing accuracy-oriented SBRSs. It is thus worthwhile to come up with a simple yet effective design that can be used as a plugin to facilitate existing SBRSs on generating a more diversified list in the meantime preserving the recommendation accuracy. In this case, we propose an end-to-end framework applied for every existing representative (accuracy-oriented) SBRS, called diversified category-aware attentive SBRS (DCA-SBRS), to boost the performance on recommendation diversity. It consists of two novel designs: a model-agnostic diversity-oriented loss function, and a non-invasive category-aware attention mechanism. Extensive experiments on three datasets showcase that our framework helps existing SBRSs achieve extraordinary performance in terms of recommendation diversity and comprehensive performance, without significantly deteriorating recommendation accuracy compared to state-of-the-art accuracy-oriented SBRSs.
Beam Detection Based on Machine Learning Algorithms
Aug 01, 2023
The positions of free electron laser beams on screens are precisely determined by a sequence of machine learning models. Transfer training is conducted in a self-constructed convolutional neural network based on VGG16 model. Output of intermediate layers are passed as features to a support vector regression model. With this sequence, 85.8% correct prediction is achieved on test data.
Understanding Diversity in Session-Based Recommendation
Aug 29, 2022
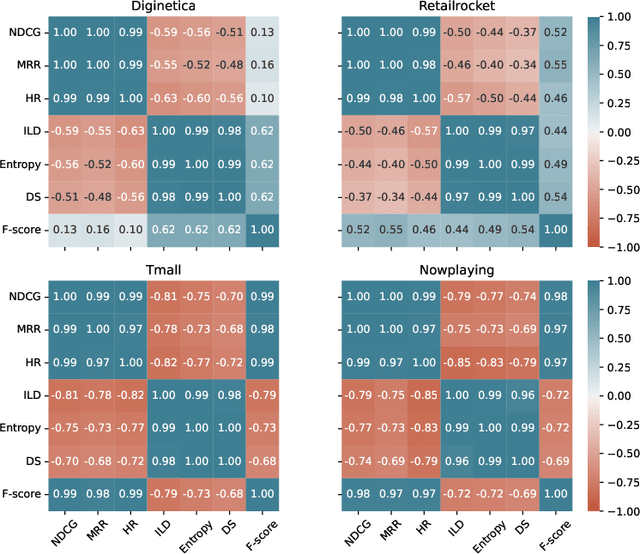

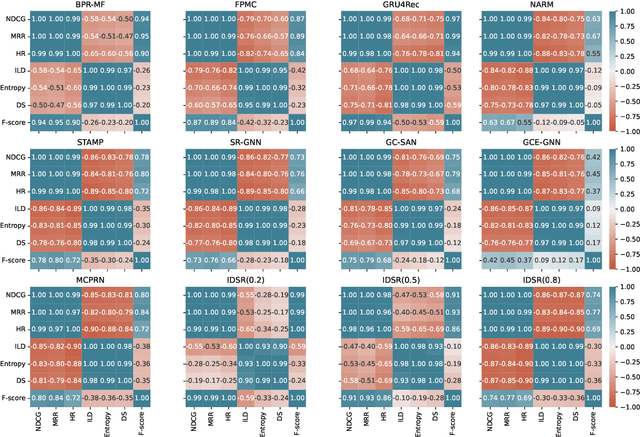
Current session-based recommender systems (SBRSs) mainly focus on maximizing recommendation accuracy, while few studies have been devoted to improve diversity beyond accuracy. Meanwhile, it is unclear how the accuracy-oriented SBRSs perform in terms of diversity. Besides, the asserted "trade-off" relationship between accuracy and diversity has been increasingly questioned in the literature. Towards the aforementioned issues, we conduct a holistic study to particularly examine the recommendation performance of representative SBRSs w.r.t. both accuracy and diversity, striving for better understanding the diversity-related issues for SBRSs and providing guidance on designing diversified SBRSs. Particularly, for a fair and thorough comparison, we deliberately select state-of-the-art non-neural, deep neural, and diversified SBRSs, by covering more scenarios with appropriate experimental setups, e.g., representative datasets, evaluation metrics, and hyper-parameter optimization technique. Our empirical results unveil that: 1) non-diversified methods can also obtain satisfying performance on diversity, which might even surpass diversified ones; and 2) the relationship between accuracy and diversity is quite complex. Besides the "trade-off" relationship, they might be positively correlated with each other, that is, having a same-trend (win-win or lose-lose) relationship, which varies across different methods and datasets. Additionally, we further identify three possible influential factors on diversity in SBRSs (i.e., granularity of item categorization, session diversity of datasets, and length of recommendation lists).
Label-dependent and event-guided interpretable disease risk prediction using EHRs
Jan 18, 2022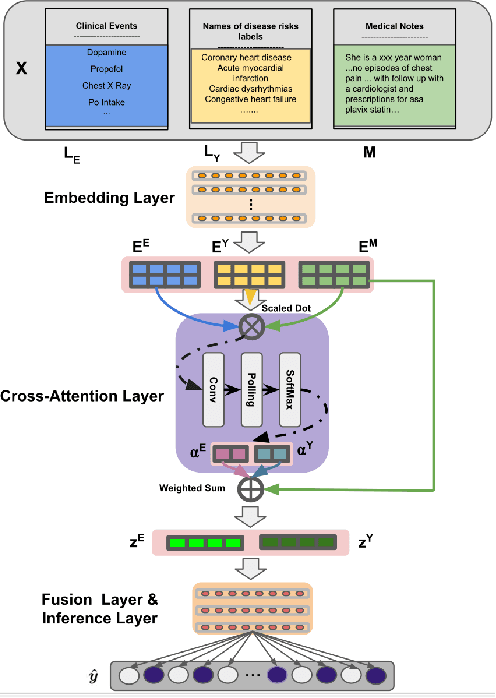
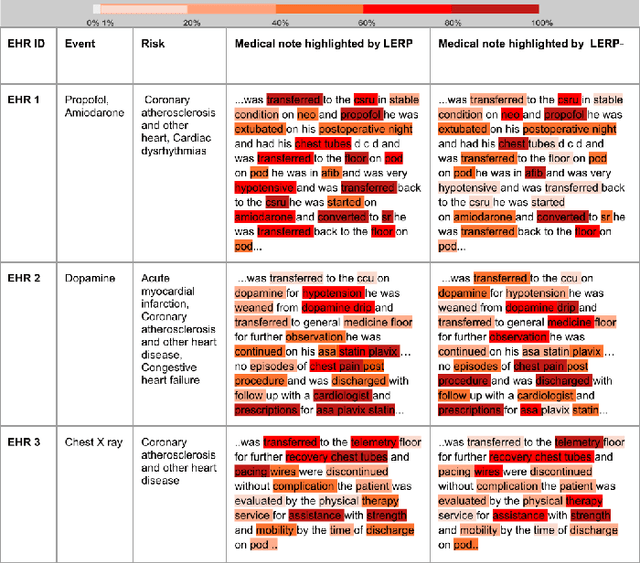
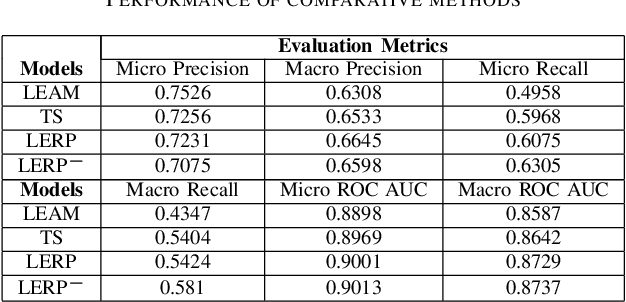
Electronic health records (EHRs) contain patients' heterogeneous data that are collected from medical providers involved in the patient's care, including medical notes, clinical events, laboratory test results, symptoms, and diagnoses. In the field of modern healthcare, predicting whether patients would experience any risks based on their EHRs has emerged as a promising research area, in which artificial intelligence (AI) plays a key role. To make AI models practically applicable, it is required that the prediction results should be both accurate and interpretable. To achieve this goal, this paper proposed a label-dependent and event-guided risk prediction model (LERP) to predict the presence of multiple disease risks by mainly extracting information from unstructured medical notes. Our model is featured in the following aspects. First, we adopt a label-dependent mechanism that gives greater attention to words from medical notes that are semantically similar to the names of risk labels. Secondly, as the clinical events (e.g., treatments and drugs) can also indicate the health status of patients, our model utilizes the information from events and uses them to generate an event-guided representation of medical notes. Thirdly, both label-dependent and event-guided representations are integrated to make a robust prediction, in which the interpretability is enabled by the attention weights over words from medical notes. To demonstrate the applicability of the proposed method, we apply it to the MIMIC-III dataset, which contains real-world EHRs collected from hospitals. Our method is evaluated in both quantitative and qualitative ways.
Label Dependent Attention Model for Disease Risk Prediction Using Multimodal Electronic Health Records
Jan 18, 2022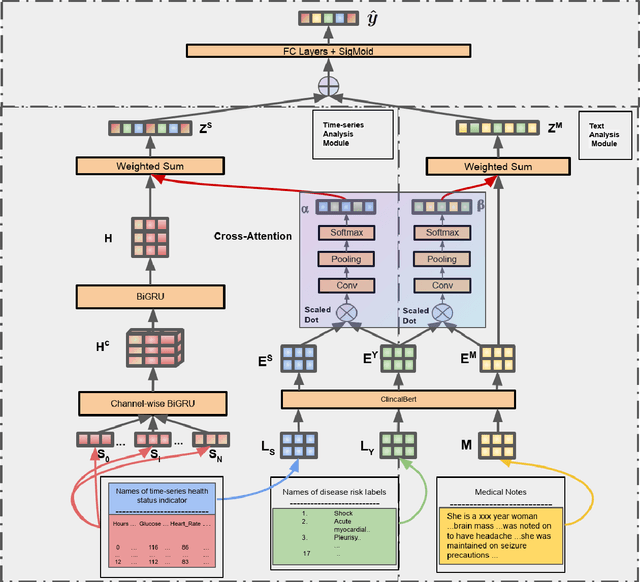
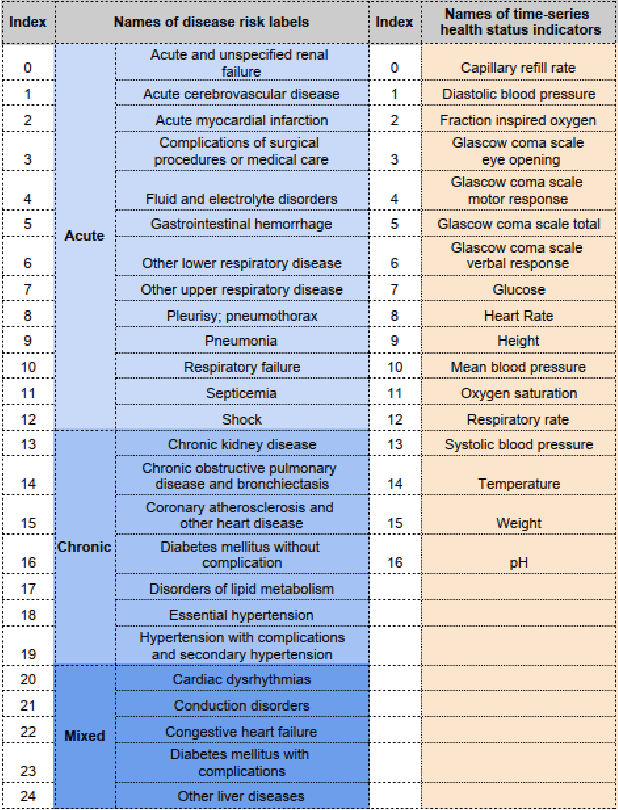

Disease risk prediction has attracted increasing attention in the field of modern healthcare, especially with the latest advances in artificial intelligence (AI). Electronic health records (EHRs), which contain heterogeneous patient information, are widely used in disease risk prediction tasks. One challenge of applying AI models for risk prediction lies in generating interpretable evidence to support the prediction results while retaining the prediction ability. In order to address this problem, we propose the method of jointly embedding words and labels whereby attention modules learn the weights of words from medical notes according to their relevance to the names of risk prediction labels. This approach boosts interpretability by employing an attention mechanism and including the names of prediction tasks in the model. However, its application is only limited to the handling of textual inputs such as medical notes. In this paper, we propose a label dependent attention model LDAM to 1) improve the interpretability by exploiting Clinical-BERT (a biomedical language model pre-trained on a large clinical corpus) to encode biomedically meaningful features and labels jointly; 2) extend the idea of joint embedding to the processing of time-series data, and develop a multi-modal learning framework for integrating heterogeneous information from medical notes and time-series health status indicators. To demonstrate our method, we apply LDAM to the MIMIC-III dataset to predict different disease risks. We evaluate our method both quantitatively and qualitatively. Specifically, the predictive power of LDAM will be shown, and case studies will be carried out to illustrate its interpretability.
AntNet: Deep Answer Understanding Network for Natural Reverse QA
Dec 01, 2019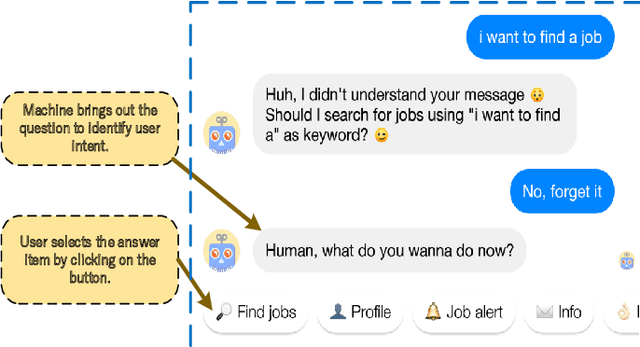
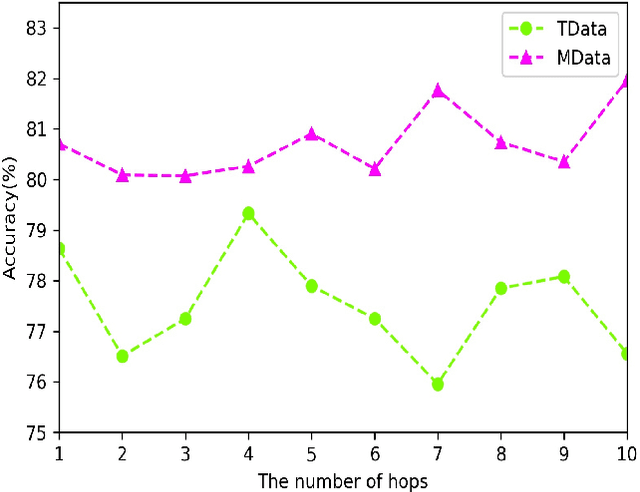

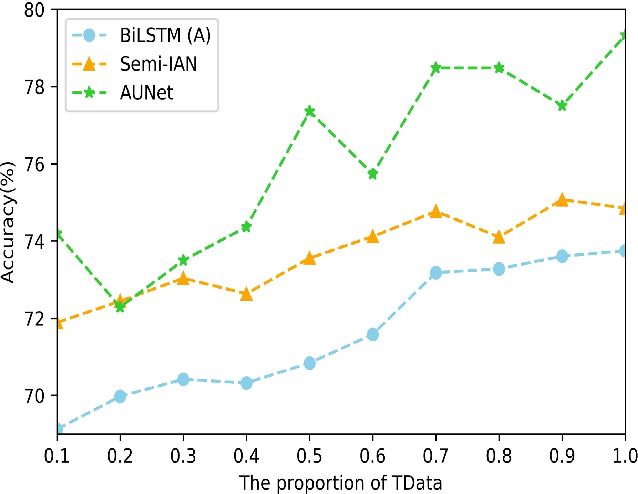
This study refers to a reverse question answering(reverse QA) procedure, in which machines proactively raise questions and humans supply answers. This procedure exists in many real human-machine interaction applications. A crucial problem in human-machine interaction is answer understanding. Existing solutions rely on mandatory option term selection to avoid automatic answer understanding. However, these solutions lead to unnatural human-computer interaction and harm user experience. To this end, this study proposed a novel deep answer understanding network, called AntNet, for reverse QA. The network consists of three new modules, namely, skeleton extraction for questions, relevance-aware representation of answers, and multi-hop based fusion. As answer understanding for reverse QA has not been explored, a new data corpus is compiled in this study. Experimental results indicate that our proposed network is significantly better than existing methods and those modified from classical natural language processing (NLP) deep models. The effectiveness of the three new modules is also verified.
Semi-interactive Attention Network for Answer Understanding in Reverse-QA
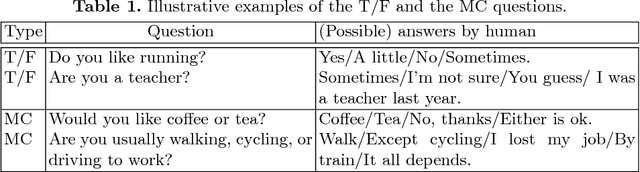
Jan 12, 2019
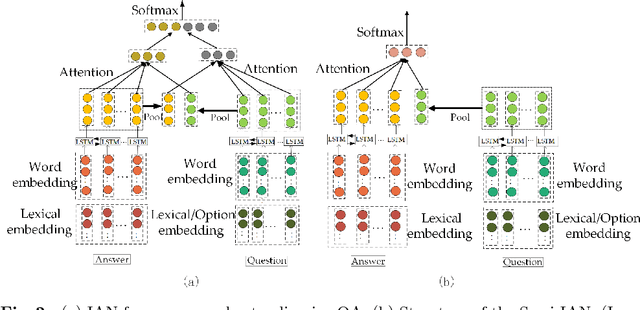
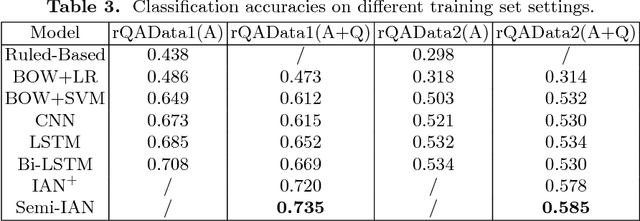
Question answering (QA) is an important natural language processing (NLP) task and has received much attention in academic research and industry communities. Existing QA studies assume that questions are raised by humans and answers are generated by machines. Nevertheless, in many real applications, machines are also required to determine human needs or perceive human states. In such scenarios, machines may proactively raise questions and humans supply answers. Subsequently, machines should attempt to understand the true meaning of these answers. This new QA approach is called reverse-QA (rQA) throughout this paper. In this work, the human answer understanding problem is investigated and solved by classifying the answers into predefined answer-label categories (e.g., True, False, Uncertain). To explore the relationships between questions and answers, we use the interactive attention network (IAN) model and propose an improved structure called semi-interactive attention network (Semi-IAN). Two Chinese data sets for rQA are compiled. We evaluate several conventional text classification models for comparison, and experimental results indicate the promising performance of our proposed models.