 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel Dependent Attention Model for Disease Risk Prediction Using Multimodal Electronic Health Records
Paper and Code
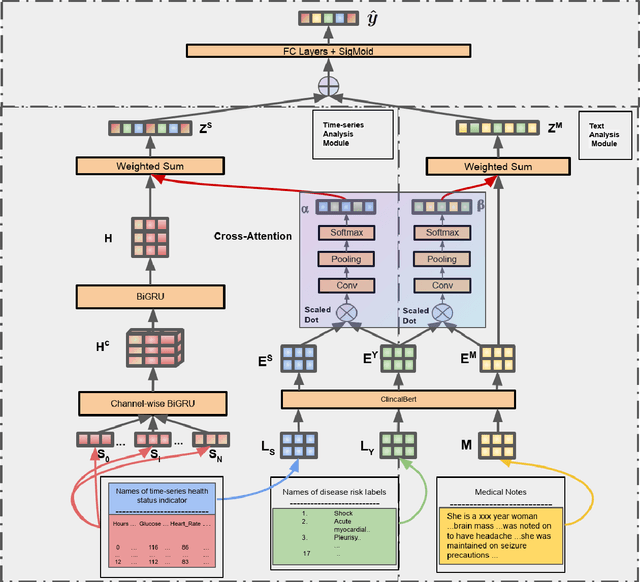
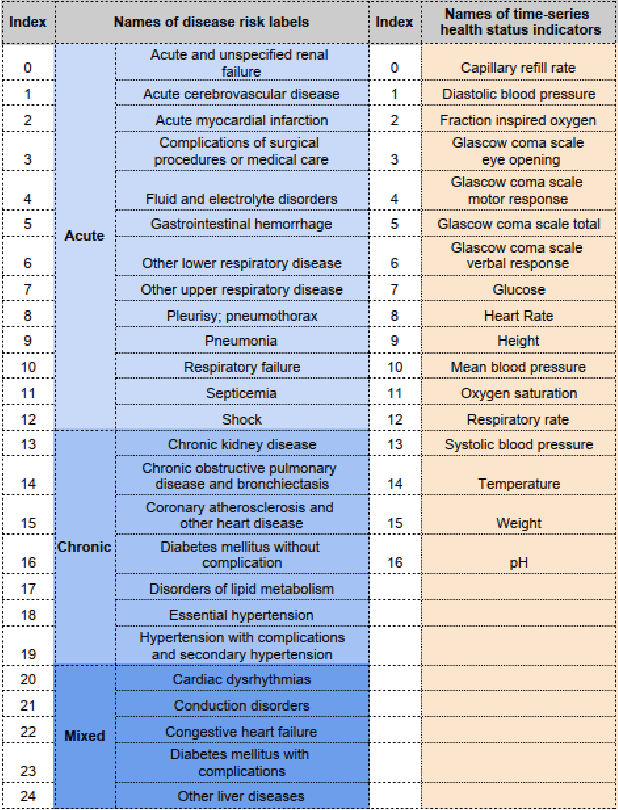

Disease risk prediction has attracted increasing attention in the field of modern healthcare, especially with the latest advances in artificial intelligence (AI). Electronic health records (EHRs), which contain heterogeneous patient information, are widely used in disease risk prediction tasks. One challenge of applying AI models for risk prediction lies in generating interpretable evidence to support the prediction results while retaining the prediction ability. In order to address this problem, we propose the method of jointly embedding words and labels whereby attention modules learn the weights of words from medical notes according to their relevance to the names of risk prediction labels. This approach boosts interpretability by employing an attention mechanism and including the names of prediction tasks in the model. However, its application is only limited to the handling of textual inputs such as medical notes. In this paper, we propose a label dependent attention model LDAM to 1) improve the interpretability by exploiting Clinical-BERT (a biomedical language model pre-trained on a large clinical corpus) to encode biomedically meaningful features and labels jointly; 2) extend the idea of joint embedding to the processing of time-series data, and develop a multi-modal learning framework for integrating heterogeneous information from medical notes and time-series health status indicators. To demonstrate our method, we apply LDAM to the MIMIC-III dataset to predict different disease risks. We evaluate our method both quantitatively and qualitatively. Specifically, the predictive power of LDAM will be shown, and case studies will be carried out to illustrate its interpretability.