 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGEM-TFL: Bridging Weak and Full Supervision for Forgery Localization through EM-Guided Decomposition and Temporal Refinement
Mar 05, 2026Temporal Forgery Localization (TFL) aims to precisely identify manipulated segments within videos or audio streams, providing interpretable evidence for multimedia forensics and security. While most existing TFL methods rely on dense frame-level labels in a fully supervised manner, Weakly Supervised TFL (WS-TFL) reduces labeling cost by learning only from binary video-level labels. However, current WS-TFL approaches suffer from mismatched training and inference objectives, limited supervision from binary labels, gradient blockage caused by non-differentiable top-k aggregation, and the absence of explicit modeling of inter-proposal relationships. To address these issues, we propose GEM-TFL (Graph-based EM-powered Temporal Forgery Localization), a two-phase classification-regression framework that effectively bridges the supervision gap between training and inference. Built upon this foundation, (1) we enhance weak supervision by reformulating binary labels into multi-dimensional latent attributes through an EM-based optimization process; (2) we introduce a training-free temporal consistency refinement that realigns frame-level predictions for smoother temporal dynamics; and (3) we design a graph-based proposal refinement module that models temporal-semantic relationships among proposals for globally consistent confidence estimation. Extensive experiments on benchmark datasets demonstrate that GEM-TFL achieves more accurate and robust temporal forgery localization, substantially narrowing the gap with fully supervised methods.
DeformTrace: A Deformable State Space Model with Relay Tokens for Temporal Forgery Localization
Mar 05, 2026Temporal Forgery Localization (TFL) aims to precisely identify manipulated segments in video and audio, offering strong interpretability for security and forensics. While recent State Space Models (SSMs) show promise in precise temporal reasoning, their use in TFL is hindered by ambiguous boundaries, sparse forgeries, and limited long-range modeling. We propose DeformTrace, which enhances SSMs with deformable dynamics and relay mechanisms to address these challenges. Specifically, Deformable Self-SSM (DS-SSM) introduces dynamic receptive fields into SSMs for precise temporal localization. To further enhance its capacity for temporal reasoning and mitigate long-range decay, a Relay Token Mechanism is integrated into DS-SSM. Besides, Deformable Cross-SSM (DC-SSM) partitions the global state space into query-specific subspaces, reducing non-forgery information accumulation and boosting sensitivity to sparse forgeries. These components are integrated into a hybrid architecture that combines the global modeling of Transformers with the efficiency of SSMs. Extensive experiments show that DeformTrace achieves state-of-the-art performance with fewer parameters, faster inference, and stronger robustness.
Integrated Precoder and Trajectory Design for MIMO UAV-Assisted Relay System With Finite-Alphabet Inputs
Nov 13, 2024Unmanned aerial vehicles (UAVs) are gaining widespread use in wireless relay systems due to their exceptional flexibility and cost-effectiveness. This paper focuses on the integrated design of UAV trajectories and the precoders at both the transmitter and UAV in a UAV-assisted relay communication system, accounting for transmit power constraints and UAV flight limitations. Unlike previous works that primarily address multiple-input single-output (MISO) systems with Gaussian inputs, we investigate a more realistic scenario involving multiple-input multiple-output (MIMO) systems with finite-alphabet inputs. To tackle the challenging and inherently non-convex problem, we propose an efficient solution algorithm that leverages successive convex approximation and alternating optimization techniques. Simulation results validate the effectiveness of the proposed algorithm, demonstrating its capability to optimize system performance.
Optimal Trade and Industrial Policies in the Global Economy: A Deep Learning Framework
Jul 25, 2024



We propose a deep learning framework, DL-opt, designed to efficiently solve for optimal policies in quantifiable general equilibrium trade models. DL-opt integrates (i) a nested fixed point (NFXP) formulation of the optimization problem, (ii) automatic implicit differentiation to enhance gradient descent for solving unilateral optimal policies, and (iii) a best-response dynamics approach for finding Nash equilibria. Utilizing DL-opt, we solve for non-cooperative tariffs and industrial subsidies across 7 economies and 44 sectors, incorporating sectoral external economies of scale. Our quantitative analysis reveals significant sectoral heterogeneity in Nash policies: Nash industrial subsidies increase with scale elasticities, whereas Nash tariffs decrease with trade elasticities. Moreover, we show that global dual competition, involving both tariffs and industrial subsidies, results in lower tariffs and higher welfare outcomes compared to a global tariff war. These findings highlight the importance of considering sectoral heterogeneity and policy combinations in understanding global economic competition.
Beyond Accuracy: An Empirical Study on Unit Testing in Open-source Deep Learning Projects
Feb 26, 2024



Deep Learning (DL) models have rapidly advanced, focusing on achieving high performance through testing model accuracy and robustness. However, it is unclear whether DL projects, as software systems, are tested thoroughly or functionally correct when there is a need to treat and test them like other software systems. Therefore, we empirically study the unit tests in open-source DL projects, analyzing 9,129 projects from GitHub. We find that: 1) unit tested DL projects have positive correlation with the open-source project metrics and have a higher acceptance rate of pull requests, 2) 68% of the sampled DL projects are not unit tested at all, 3) the layer and utilities (utils) of DL models have the most unit tests. Based on these findings and previous research outcomes, we built a mapping taxonomy between unit tests and faults in DL projects. We discuss the implications of our findings for developers and researchers and highlight the need for unit testing in open-source DL projects to ensure their reliability and stability. The study contributes to this community by raising awareness of the importance of unit testing in DL projects and encouraging further research in this area.
GUIGAN: Learning to Generate GUI Designs Using Generative Adversarial Networks
Jan 27, 2021
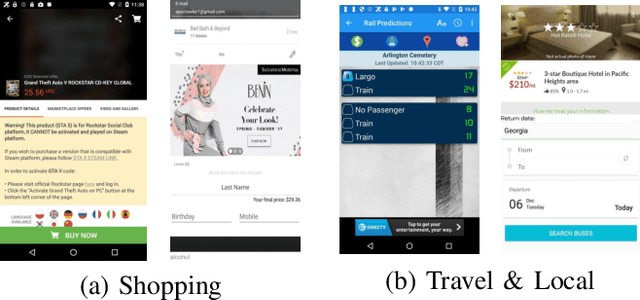
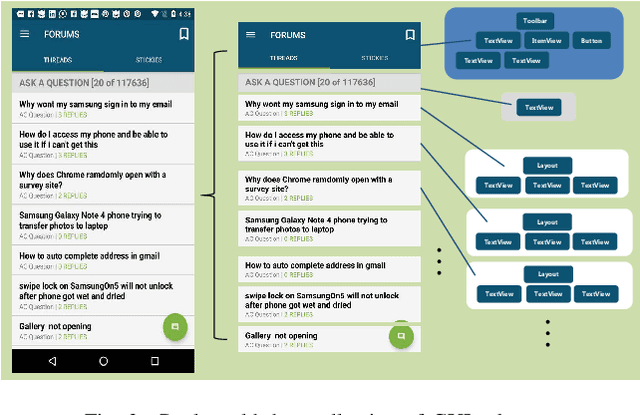
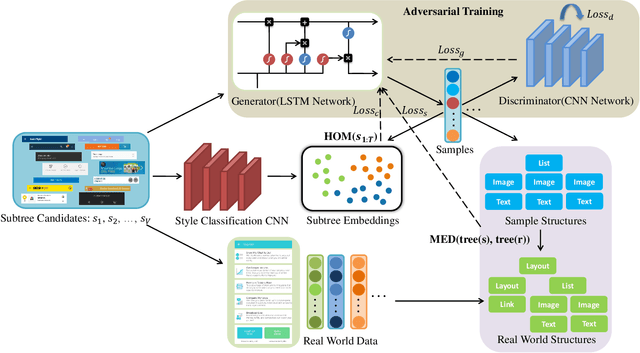
Graphical User Interface (GUI) is ubiquitous in almost all modern desktop software, mobile applications, and online websites. A good GUI design is crucial to the success of the software in the market, but designing a good GUI which requires much innovation and creativity is difficult even to well-trained designers. Besides, the requirement of the rapid development of GUI design also aggravates designers' working load. So, the availability of various automated generated GUIs can help enhance the design personalization and specialization as they can cater to the taste of different designers. To assist designers, we develop a model GUIGAN to automatically generate GUI designs. Different from conventional image generation models based on image pixels, our GUIGAN is to reuse GUI components collected from existing mobile app GUIs for composing a new design that is similar to natural-language generation. Our GUIGAN is based on SeqGAN by modeling the GUI component style compatibility and GUI structure. The evaluation demonstrates that our model significantly outperforms the best of the baseline methods by 30.77% in Frechet Inception distance (FID) and 12.35% in 1-Nearest Neighbor Accuracy (1-NNA). Through a pilot user study, we provide initial evidence of the usefulness of our approach for generating acceptable brand new GUI designs.
Semi-interactive Attention Network for Answer Understanding in Reverse-QA
Jan 12, 2019
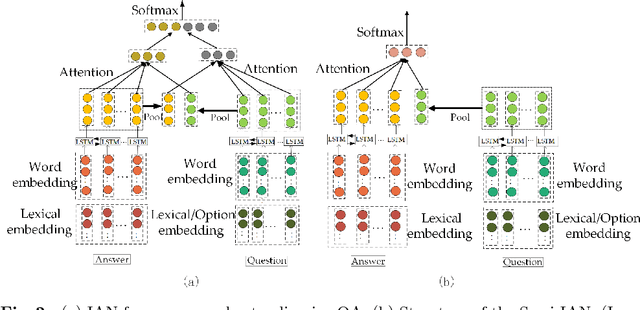
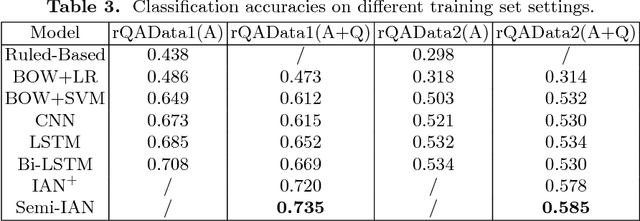
Question answering (QA) is an important natural language processing (NLP) task and has received much attention in academic research and industry communities. Existing QA studies assume that questions are raised by humans and answers are generated by machines. Nevertheless, in many real applications, machines are also required to determine human needs or perceive human states. In such scenarios, machines may proactively raise questions and humans supply answers. Subsequently, machines should attempt to understand the true meaning of these answers. This new QA approach is called reverse-QA (rQA) throughout this paper. In this work, the human answer understanding problem is investigated and solved by classifying the answers into predefined answer-label categories (e.g., True, False, Uncertain). To explore the relationships between questions and answers, we use the interactive attention network (IAN) model and propose an improved structure called semi-interactive attention network (Semi-IAN). Two Chinese data sets for rQA are compiled. We evaluate several conventional text classification models for comparison, and experimental results indicate the promising performance of our proposed models.