 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNavigating Fairness: Practitioners' Understanding, Challenges, and Strategies in AI/ML Development
Mar 21, 2024
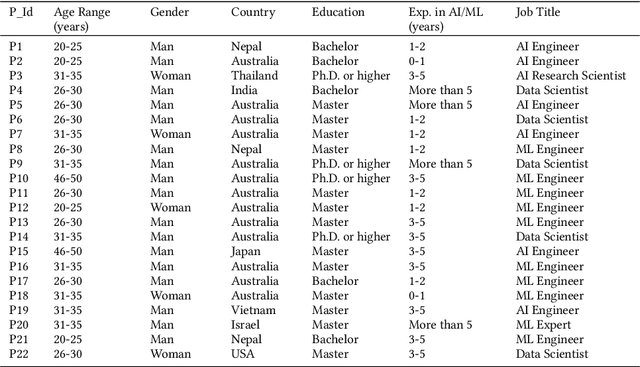
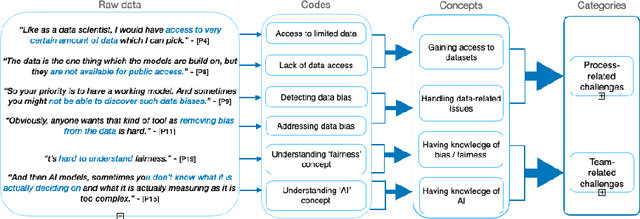

The rise in the use of AI/ML applications across industries has sparked more discussions about the fairness of AI/ML in recent times. While prior research on the fairness of AI/ML exists, there is a lack of empirical studies focused on understanding the views and experiences of AI practitioners in developing a fair AI/ML. Understanding AI practitioners' views and experiences on the fairness of AI/ML is important because they are directly involved in its development and deployment and their insights can offer valuable real-world perspectives on the challenges associated with ensuring fairness in AI/ML. We conducted semi-structured interviews with 22 AI practitioners to investigate their understanding of what a 'fair AI/ML' is, the challenges they face in developing a fair AI/ML, the consequences of developing an unfair AI/ML, and the strategies they employ to ensure AI/ML fairness. We developed a framework showcasing the relationship between AI practitioners' understanding of 'fair AI/ML' and (i) their challenges in its development, (ii) the consequences of developing an unfair AI/ML, and (iii) strategies used to ensure AI/ML fairness. Additionally, we also identify areas for further investigation and offer recommendations to aid AI practitioners and AI companies in navigating fairness.
Beyond Accuracy: An Empirical Study on Unit Testing in Open-source Deep Learning Projects
Feb 26, 2024



Deep Learning (DL) models have rapidly advanced, focusing on achieving high performance through testing model accuracy and robustness. However, it is unclear whether DL projects, as software systems, are tested thoroughly or functionally correct when there is a need to treat and test them like other software systems. Therefore, we empirically study the unit tests in open-source DL projects, analyzing 9,129 projects from GitHub. We find that: 1) unit tested DL projects have positive correlation with the open-source project metrics and have a higher acceptance rate of pull requests, 2) 68% of the sampled DL projects are not unit tested at all, 3) the layer and utilities (utils) of DL models have the most unit tests. Based on these findings and previous research outcomes, we built a mapping taxonomy between unit tests and faults in DL projects. We discuss the implications of our findings for developers and researchers and highlight the need for unit testing in open-source DL projects to ensure their reliability and stability. The study contributes to this community by raising awareness of the importance of unit testing in DL projects and encouraging further research in this area.
Ethics in the Age of AI: An Analysis of AI Practitioners' Awareness and Challenges
Jul 14, 2023



Ethics in AI has become a debated topic of public and expert discourse in recent years. But what do people who build AI - AI practitioners - have to say about their understanding of AI ethics and the challenges associated with incorporating it in the AI-based systems they develop? Understanding AI practitioners' views on AI ethics is important as they are the ones closest to the AI systems and can bring about changes and improvements. We conducted a survey aimed at understanding AI practitioners' awareness of AI ethics and their challenges in incorporating ethics. Based on 100 AI practitioners' responses, our findings indicate that majority of AI practitioners had a reasonable familiarity with the concept of AI ethics, primarily due to workplace rules and policies. Privacy protection and security was the ethical principle that majority of them were aware of. Formal education/training was considered somewhat helpful in preparing practitioners to incorporate AI ethics. The challenges that AI practitioners faced in the development of ethical AI-based systems included (i) general challenges, (ii) technology-related challenges and (iii) human-related challenges. We also identified areas needing further investigation and provided recommendations to assist AI practitioners and companies in incorporating ethics into AI development.
A Comparison of Similarity Based Instance Selection Methods for Cross Project Defect Prediction
Apr 02, 2021



Context: Previous studies have shown that training data instance selection based on nearest neighborhood (NN) information can lead to better performance in cross project defect prediction (CPDP) by reducing heterogeneity in training datasets. However, neighborhood calculation is computationally expensive and approximate methods such as Locality Sensitive Hashing (LSH) can be as effective as exact methods. Aim: We aim at comparing instance selection methods for CPDP, namely LSH, NN-filter, and Genetic Instance Selection (GIS). Method: We conduct experiments with five base learners, optimizing their hyper parameters, on 13 datasets from PROMISE repository in order to compare the performance of LSH with benchmark instance selection methods NN-Filter and GIS. Results: The statistical tests show six distinct groups for F-measure performance. The top two group contains only LSH and GIS benchmarks whereas the bottom two groups contain only NN-Filter variants. LSH and GIS favor recall more than precision. In fact, for precision performance only three significantly distinct groups are detected by the tests where the top group is comprised of NN-Filter variants only. Recall wise, 16 different groups are identified where the top three groups contain only LSH methods, four of the next six are GIS only and the bottom five contain only NN-Filter. Finally, NN-Filter benchmarks never outperform the LSH counterparts with the same base learner, tuned or non-tuned. Further, they never even belong to the same rank group, meaning that LSH is always significantly better than NN-Filter with the same learner and settings. Conclusions: The increase in performance and the decrease in computational overhead and runtime make LSH a promising approach. However, the performance of LSH is based on high recall and in environments where precision is considered more important NN-Filter should be considered.