 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObservation, Analysis, and Solution: Exploring Strong Lightweight Vision Transformers via Masked Image Modeling Pre-Training
Apr 18, 2024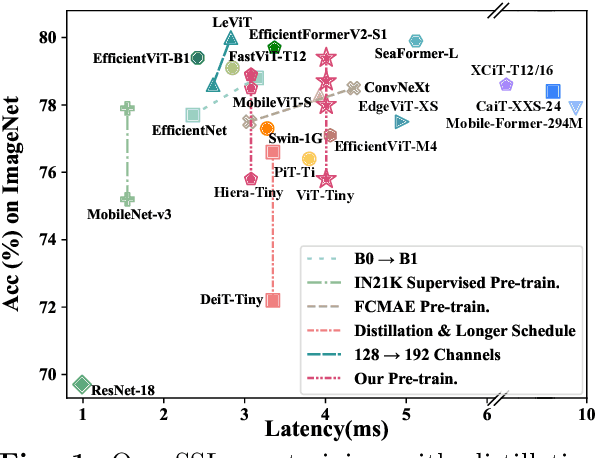
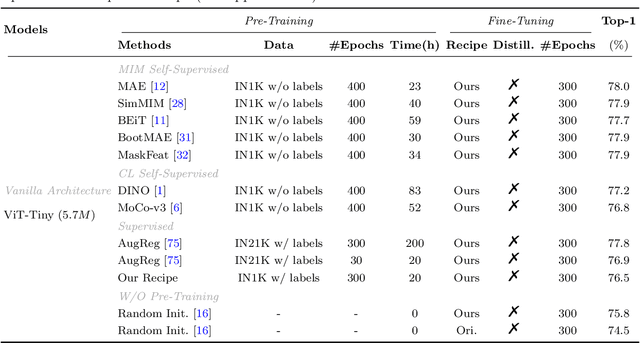

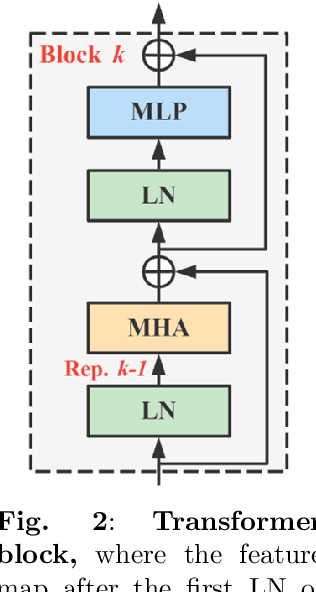
Masked image modeling (MIM) pre-training for large-scale vision transformers (ViTs) in computer vision has enabled promising downstream performance on top of the learned self-supervised ViT features. In this paper, we question if the extremely simple ViTs' fine-tuning performance with a small-scale architecture can also benefit from this pre-training paradigm, which is considerably less studied yet in contrast to the well-established lightweight architecture design methodology with sophisticated components introduced. By carefully adapting various typical MIM pre-training methods to this lightweight regime and comparing them with the contrastive learning (CL) pre-training on various downstream image classification and dense prediction tasks, we systematically observe different behaviors between MIM and CL with respect to the downstream fine-tuning data scales. Furthermore, we analyze the frozen features under linear probing evaluation and also the layer representation similarities and attention maps across the obtained models, which clearly show the inferior learning of MIM pre-training on higher layers, leading to unsatisfactory fine-tuning performance on data-insufficient downstream tasks. This finding is naturally a guide to choosing appropriate distillation strategies during pre-training to solve the above deterioration problem. Extensive experiments on various vision tasks demonstrate the effectiveness of our observation-analysis-solution flow. In particular, our pre-training with distillation on pure lightweight ViTs with vanilla/hierarchical design (5.7M/6.5M) can achieve 79.4%/78.9% top-1 accuracy on ImageNet-1K. It also enables SOTA performance on the ADE20K semantic segmentation task (42.8% mIoU) and LaSOT visual tracking task (66.1% AUC) in the lightweight regime. The latter even surpasses all the current SOTA lightweight CPU-realtime trackers.
GMC-IQA: Exploiting Global-correlation and Mean-opinion Consistency for No-reference Image Quality Assessment
Jan 19, 2024
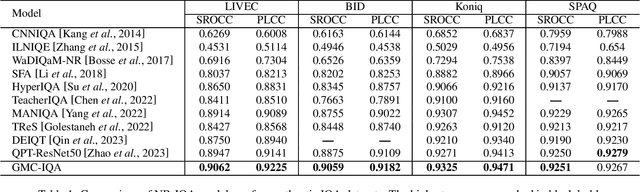
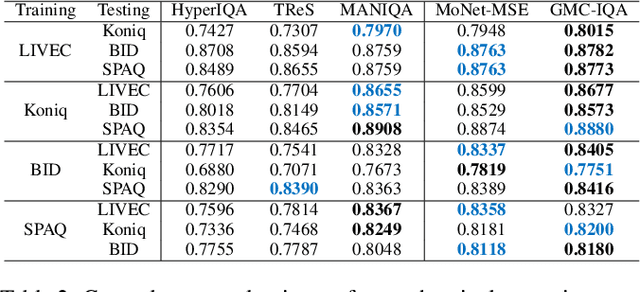
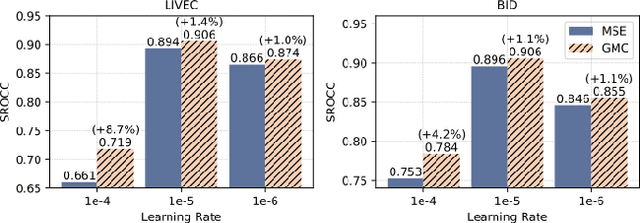
Due to the subjective nature of image quality assessment (IQA), assessing which image has better quality among a sequence of images is more reliable than assigning an absolute mean opinion score for an image. Thus, IQA models are evaluated by global correlation consistency (GCC) metrics like PLCC and SROCC, rather than mean opinion consistency (MOC) metrics like MAE and MSE. However, most existing methods adopt MOC metrics to define their loss functions, due to the infeasible computation of GCC metrics during training. In this work, we construct a novel loss function and network to exploit Global-correlation and Mean-opinion Consistency, forming a GMC-IQA framework. Specifically, we propose a novel GCC loss by defining a pairwise preference-based rank estimation to solve the non-differentiable problem of SROCC and introducing a queue mechanism to reserve previous data to approximate the global results of the whole data. Moreover, we propose a mean-opinion network, which integrates diverse opinion features to alleviate the randomness of weight learning and enhance the model robustness. Experiments indicate that our method outperforms SOTA methods on multiple authentic datasets with higher accuracy and generalization. We also adapt the proposed loss to various networks, which brings better performance and more stable training.
RT-MonoDepth: Real-time Monocular Depth Estimation on Embedded Systems
Aug 21, 2023



Depth sensing is a crucial function of unmanned aerial vehicles and autonomous vehicles. Due to the small size and simple structure of monocular cameras, there has been a growing interest in depth estimation from a single RGB image. However, state-of-the-art monocular CNN-based depth estimation methods using fairly complex deep neural networks are too slow for real-time inference on embedded platforms. This paper addresses the problem of real-time depth estimation on embedded systems. We propose two efficient and lightweight encoder-decoder network architectures, RT-MonoDepth and RT-MonoDepth-S, to reduce computational complexity and latency. Our methodologies demonstrate that it is possible to achieve similar accuracy as prior state-of-the-art works on depth estimation at a faster inference speed. Our proposed networks, RT-MonoDepth and RT-MonoDepth-S, runs at 18.4\&30.5 FPS on NVIDIA Jetson Nano and 253.0\&364.1 FPS on NVIDIA Jetson AGX Orin on a single RGB image of resolution 640$\times$192, and achieve relative state-of-the-art accuracy on the KITTI dataset. To the best of the authors' knowledge, this paper achieves the best accuracy and fastest inference speed compared with existing fast monocular depth estimation methods.
Open-Vocabulary One-Stage Detection with Hierarchical Visual-Language Knowledge Distillation
Mar 20, 2022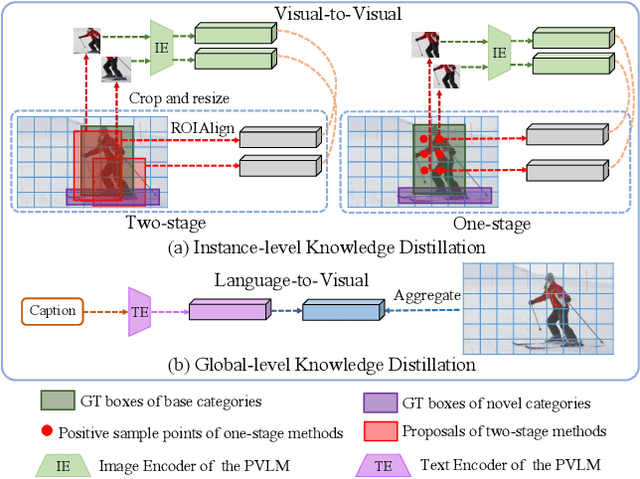
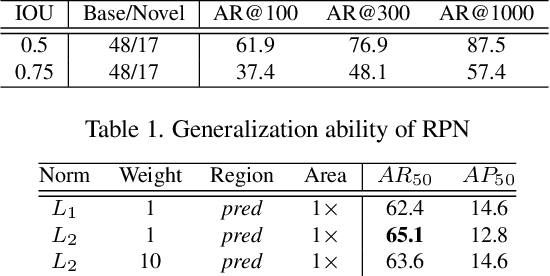
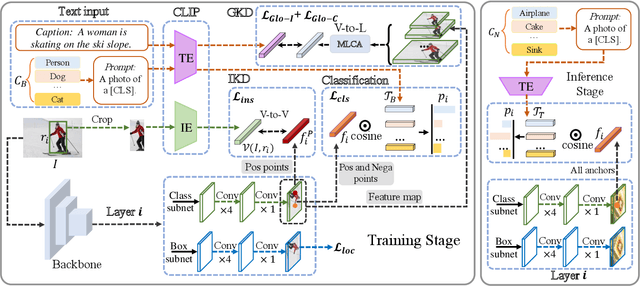
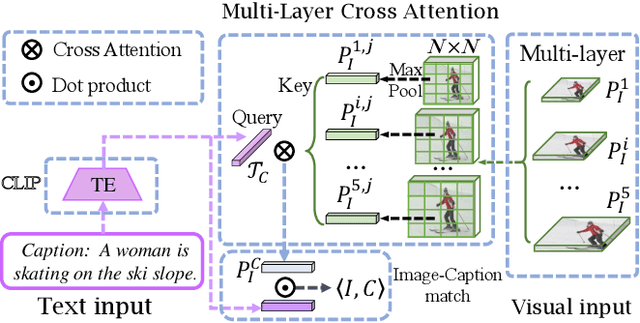
Open-vocabulary object detection aims to detect novel object categories beyond the training set. The advanced open-vocabulary two-stage detectors employ instance-level visual-to-visual knowledge distillation to align the visual space of the detector with the semantic space of the Pre-trained Visual-Language Model (PVLM). However, in the more efficient one-stage detector, the absence of class-agnostic object proposals hinders the knowledge distillation on unseen objects, leading to severe performance degradation. In this paper, we propose a hierarchical visual-language knowledge distillation method, i.e., HierKD, for open-vocabulary one-stage detection. Specifically, a global-level knowledge distillation is explored to transfer the knowledge of unseen categories from the PVLM to the detector. Moreover, we combine the proposed global-level knowledge distillation and the common instance-level knowledge distillation to learn the knowledge of seen and unseen categories simultaneously. Extensive experiments on MS-COCO show that our method significantly surpasses the previous best one-stage detector with 11.9\% and 6.7\% $AP_{50}$ gains under the zero-shot detection and generalized zero-shot detection settings, and reduces the $AP_{50}$ performance gap from 14\% to 7.3\% compared to the best two-stage detector.