 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge5%>100%: Breaking Performance Shackles of Full Fine-Tuning on Visual Recognition Tasks
Aug 15, 2024



Pre-training & fine-tuning can enhance the transferring efficiency and performance in visual tasks. Recent delta-tuning methods provide more options for visual classification tasks. Despite their success, existing visual delta-tuning art fails to exceed the upper limit of full fine-tuning on challenging tasks like object detection and segmentation. To find a competitive alternative to full fine-tuning, we propose the Multi-cognitive Visual Adapter (Mona) tuning, a novel adapter-based tuning method. First, we introduce multiple vision-friendly filters into the adapter to enhance its ability to process visual signals, while previous methods mainly rely on language-friendly linear filters. Second, we add the scaled normalization layer in the adapter to regulate the distribution of input features for visual filters. To fully demonstrate the practicality and generality of Mona, we conduct experiments on multiple representative visual tasks, including instance segmentation on COCO, semantic segmentation on ADE20K, object detection on Pascal VOC, oriented object detection on DOTA/STAR, and image classification on three common datasets. Exciting results illustrate that Mona surpasses full fine-tuning on all these tasks, and is the only delta-tuning method outperforming full fine-tuning on the above various tasks. For example, Mona achieves 1% performance gain on the COCO dataset compared to full fine-tuning. Comprehensive results suggest that Mona-tuning is more suitable for retaining and utilizing the capabilities of pre-trained models than full fine-tuning. We will make the code publicly available.
GMC-IQA: Exploiting Global-correlation and Mean-opinion Consistency for No-reference Image Quality Assessment
Jan 19, 2024
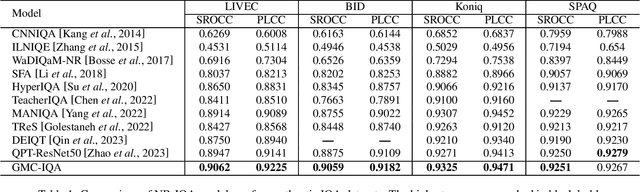
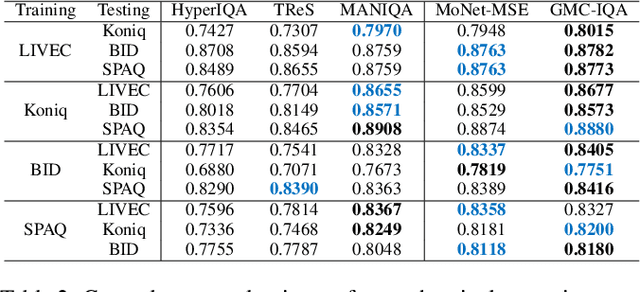
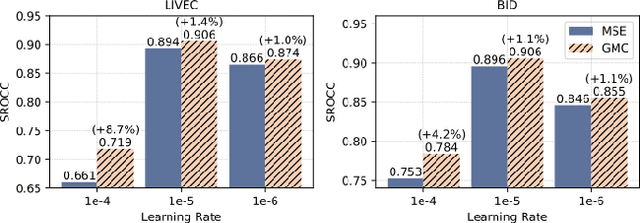
Due to the subjective nature of image quality assessment (IQA), assessing which image has better quality among a sequence of images is more reliable than assigning an absolute mean opinion score for an image. Thus, IQA models are evaluated by global correlation consistency (GCC) metrics like PLCC and SROCC, rather than mean opinion consistency (MOC) metrics like MAE and MSE. However, most existing methods adopt MOC metrics to define their loss functions, due to the infeasible computation of GCC metrics during training. In this work, we construct a novel loss function and network to exploit Global-correlation and Mean-opinion Consistency, forming a GMC-IQA framework. Specifically, we propose a novel GCC loss by defining a pairwise preference-based rank estimation to solve the non-differentiable problem of SROCC and introducing a queue mechanism to reserve previous data to approximate the global results of the whole data. Moreover, we propose a mean-opinion network, which integrates diverse opinion features to alleviate the randomness of weight learning and enhance the model robustness. Experiments indicate that our method outperforms SOTA methods on multiple authentic datasets with higher accuracy and generalization. We also adapt the proposed loss to various networks, which brings better performance and more stable training.
Adapter is All You Need for Tuning Visual Tasks
Nov 30, 2023
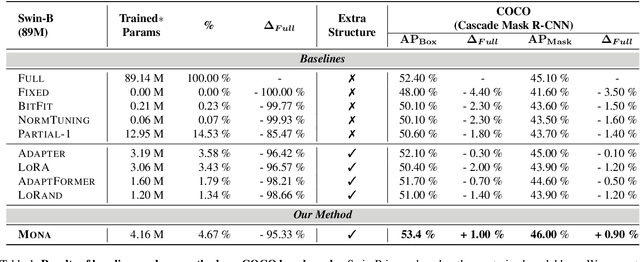
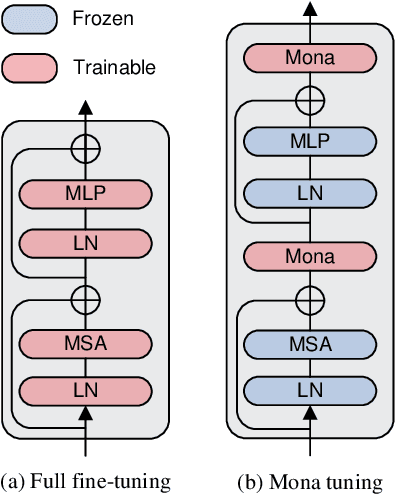
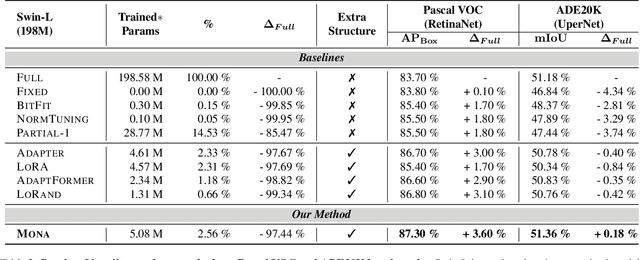
Pre-training & fine-tuning can enhance the transferring efficiency and performance in visual tasks. Recent delta-tuning methods provide more options for visual classification tasks. Despite their success, existing visual delta-tuning art fails to exceed the upper limit of full fine-tuning on challenging tasks like instance segmentation and semantic segmentation. To find a competitive alternative to full fine-tuning, we propose the Multi-cognitive Visual Adapter (Mona) tuning, a novel adapter-based tuning method. First, we introduce multiple vision-friendly filters into the adapter to enhance its ability to process visual signals, while previous methods mainly rely on language-friendly linear filters. Second, we add the scaled normalization layer in the adapter to regulate the distribution of input features for visual filters. To fully demonstrate the practicality and generality of Mona, we conduct experiments on multiple representative visual tasks, including instance segmentation on COCO, semantic segmentation on ADE20K, object detection on Pascal VOC, and image classification on several common datasets. Exciting results illustrate that Mona surpasses full fine-tuning on all these tasks and is the only delta-tuning method outperforming full fine-tuning on instance segmentation and semantic segmentation tasks. For example, Mona achieves a 1% performance gain on the COCO dataset compared to full fine-tuning. Comprehensive results suggest that Mona-tuning is more suitable for retaining and utilizing the capabilities of pre-trained models than full fine-tuning. The code will be released at https://github.com/Leiyi-Hu/mona.