 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRectify Evaluation Preference: Improving LLMs' Critique on Math Reasoning via Perplexity-aware Reinforcement Learning
Nov 13, 2025To improve Multi-step Mathematical Reasoning (MsMR) of Large Language Models (LLMs), it is crucial to obtain scalable supervision from the corpus by automatically critiquing mistakes in the reasoning process of MsMR and rendering a final verdict of the problem-solution. Most existing methods rely on crafting high-quality supervised fine-tuning demonstrations for critiquing capability enhancement and pay little attention to delving into the underlying reason for the poor critiquing performance of LLMs. In this paper, we orthogonally quantify and investigate the potential reason -- imbalanced evaluation preference, and conduct a statistical preference analysis. Motivated by the analysis of the reason, a novel perplexity-aware reinforcement learning algorithm is proposed to rectify the evaluation preference, elevating the critiquing capability. Specifically, to probe into LLMs' critiquing characteristics, a One-to-many Problem-Solution (OPS) benchmark is meticulously constructed to quantify the behavior difference of LLMs when evaluating the problem solutions generated by itself and others. Then, to investigate the behavior difference in depth, we conduct a statistical preference analysis oriented on perplexity and find an intriguing phenomenon -- ``LLMs incline to judge solutions with lower perplexity as correct'', which is dubbed as \textit{imbalanced evaluation preference}. To rectify this preference, we regard perplexity as the baton in the algorithm of Group Relative Policy Optimization, supporting the LLMs to explore trajectories that judge lower perplexity as wrong and higher perplexity as correct. Extensive experimental results on our built OPS and existing available critic benchmarks demonstrate the validity of our method.
5%>100%: Breaking Performance Shackles of Full Fine-Tuning on Visual Recognition Tasks
Aug 15, 2024



Pre-training & fine-tuning can enhance the transferring efficiency and performance in visual tasks. Recent delta-tuning methods provide more options for visual classification tasks. Despite their success, existing visual delta-tuning art fails to exceed the upper limit of full fine-tuning on challenging tasks like object detection and segmentation. To find a competitive alternative to full fine-tuning, we propose the Multi-cognitive Visual Adapter (Mona) tuning, a novel adapter-based tuning method. First, we introduce multiple vision-friendly filters into the adapter to enhance its ability to process visual signals, while previous methods mainly rely on language-friendly linear filters. Second, we add the scaled normalization layer in the adapter to regulate the distribution of input features for visual filters. To fully demonstrate the practicality and generality of Mona, we conduct experiments on multiple representative visual tasks, including instance segmentation on COCO, semantic segmentation on ADE20K, object detection on Pascal VOC, oriented object detection on DOTA/STAR, and image classification on three common datasets. Exciting results illustrate that Mona surpasses full fine-tuning on all these tasks, and is the only delta-tuning method outperforming full fine-tuning on the above various tasks. For example, Mona achieves 1% performance gain on the COCO dataset compared to full fine-tuning. Comprehensive results suggest that Mona-tuning is more suitable for retaining and utilizing the capabilities of pre-trained models than full fine-tuning. We will make the code publicly available.
Adapter is All You Need for Tuning Visual Tasks
Nov 30, 2023
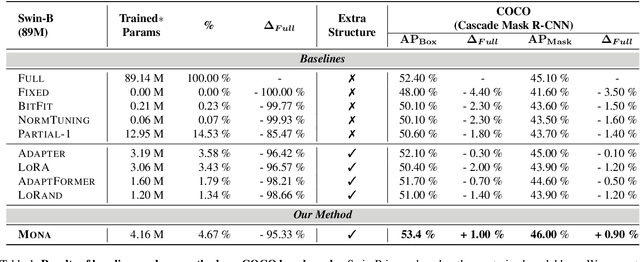
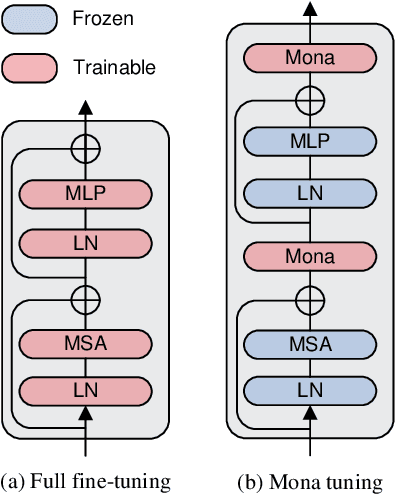
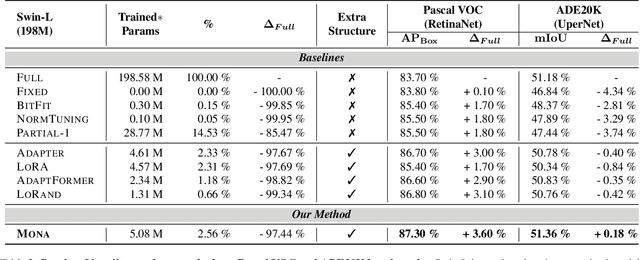
Pre-training & fine-tuning can enhance the transferring efficiency and performance in visual tasks. Recent delta-tuning methods provide more options for visual classification tasks. Despite their success, existing visual delta-tuning art fails to exceed the upper limit of full fine-tuning on challenging tasks like instance segmentation and semantic segmentation. To find a competitive alternative to full fine-tuning, we propose the Multi-cognitive Visual Adapter (Mona) tuning, a novel adapter-based tuning method. First, we introduce multiple vision-friendly filters into the adapter to enhance its ability to process visual signals, while previous methods mainly rely on language-friendly linear filters. Second, we add the scaled normalization layer in the adapter to regulate the distribution of input features for visual filters. To fully demonstrate the practicality and generality of Mona, we conduct experiments on multiple representative visual tasks, including instance segmentation on COCO, semantic segmentation on ADE20K, object detection on Pascal VOC, and image classification on several common datasets. Exciting results illustrate that Mona surpasses full fine-tuning on all these tasks and is the only delta-tuning method outperforming full fine-tuning on instance segmentation and semantic segmentation tasks. For example, Mona achieves a 1% performance gain on the COCO dataset compared to full fine-tuning. Comprehensive results suggest that Mona-tuning is more suitable for retaining and utilizing the capabilities of pre-trained models than full fine-tuning. The code will be released at https://github.com/Leiyi-Hu/mona.