 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiniBEE: A New Form Factor for Compact Bimanual Dexterity
Oct 02, 2025Bimanual robot manipulators can achieve impressive dexterity, but typically rely on two full six- or seven- degree-of-freedom arms so that paired grippers can coordinate effectively. This traditional framework increases system complexity while only exploiting a fraction of the overall workspace for dexterous interaction. We introduce the MiniBEE (Miniature Bimanual End-effector), a compact system in which two reduced-mobility arms (3+ DOF each) are coupled into a kinematic chain that preserves full relative positioning between grippers. To guide our design, we formulate a kinematic dexterity metric that enlarges the dexterous workspace while keeping the mechanism lightweight and wearable. The resulting system supports two complementary modes: (i) wearable kinesthetic data collection with self-tracked gripper poses, and (ii) deployment on a standard robot arm, extending dexterity across its entire workspace. We present kinematic analysis and design optimization methods for maximizing dexterous range, and demonstrate an end-to-end pipeline in which wearable demonstrations train imitation learning policies that perform robust, real-world bimanual manipulation.
NTIRE 2025 Image Shadow Removal Challenge Report
Jun 18, 2025



This work examines the findings of the NTIRE 2025 Shadow Removal Challenge. A total of 306 participants have registered, with 17 teams successfully submitting their solutions during the final evaluation phase. Following the last two editions, this challenge had two evaluation tracks: one focusing on reconstruction fidelity and the other on visual perception through a user study. Both tracks were evaluated with images from the WSRD+ dataset, simulating interactions between self- and cast-shadows with a large number of diverse objects, textures, and materials.
NTIRE 2025 challenge on Text to Image Generation Model Quality Assessment
May 22, 2025This paper reports on the NTIRE 2025 challenge on Text to Image (T2I) generation model quality assessment, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2025. The aim of this challenge is to address the fine-grained quality assessment of text-to-image generation models. This challenge evaluates text-to-image models from two aspects: image-text alignment and image structural distortion detection, and is divided into the alignment track and the structural track. The alignment track uses the EvalMuse-40K, which contains around 40K AI-Generated Images (AIGIs) generated by 20 popular generative models. The alignment track has a total of 371 registered participants. A total of 1,883 submissions are received in the development phase, and 507 submissions are received in the test phase. Finally, 12 participating teams submitted their models and fact sheets. The structure track uses the EvalMuse-Structure, which contains 10,000 AI-Generated Images (AIGIs) with corresponding structural distortion mask. A total of 211 participants have registered in the structure track. A total of 1155 submissions are received in the development phase, and 487 submissions are received in the test phase. Finally, 8 participating teams submitted their models and fact sheets. Almost all methods have achieved better results than baseline methods, and the winning methods in both tracks have demonstrated superior prediction performance on T2I model quality assessment.
SEAGULL: No-reference Image Quality Assessment for Regions of Interest via Vision-Language Instruction Tuning
Nov 15, 2024



Existing Image Quality Assessment (IQA) methods achieve remarkable success in analyzing quality for overall image, but few works explore quality analysis for Regions of Interest (ROIs). The quality analysis of ROIs can provide fine-grained guidance for image quality improvement and is crucial for scenarios focusing on region-level quality. This paper proposes a novel network, SEAGULL, which can SEe and Assess ROIs quality with GUidance from a Large vision-Language model. SEAGULL incorporates a vision-language model (VLM), masks generated by Segment Anything Model (SAM) to specify ROIs, and a meticulously designed Mask-based Feature Extractor (MFE) to extract global and local tokens for specified ROIs, enabling accurate fine-grained IQA for ROIs. Moreover, this paper constructs two ROI-based IQA datasets, SEAGULL-100w and SEAGULL-3k, for training and evaluating ROI-based IQA. SEAGULL-100w comprises about 100w synthetic distortion images with 33 million ROIs for pre-training to improve the model's ability of regional quality perception, and SEAGULL-3k contains about 3k authentic distortion ROIs to enhance the model's ability to perceive real world distortions. After pre-training on SEAGULL-100w and fine-tuning on SEAGULL-3k, SEAGULL shows remarkable performance on fine-grained ROI quality assessment. Code and datasets are publicly available at the https://github.com/chencn2020/Seagull.
MobileIQA: Exploiting Mobile-level Diverse Opinion Network For No-Reference Image Quality Assessment Using Knowledge Distillation
Sep 02, 2024With the rising demand for high-resolution (HR) images, No-Reference Image Quality Assessment (NR-IQA) gains more attention, as it can ecaluate image quality in real-time on mobile devices and enhance user experience. However, existing NR-IQA methods often resize or crop the HR images into small resolution, which leads to a loss of important details. And most of them are of high computational complexity, which hinders their application on mobile devices due to limited computational resources. To address these challenges, we propose MobileIQA, a novel approach that utilizes lightweight backbones to efficiently assess image quality while preserving image details through high-resolution input. MobileIQA employs the proposed multi-view attention learning (MAL) module to capture diverse opinions, simulating subjective opinions provided by different annotators during the dataset annotation process. The model uses a teacher model to guide the learning of a student model through knowledge distillation. This method significantly reduces computational complexity while maintaining high performance. Experiments demonstrate that MobileIQA outperforms novel IQA methods on evaluation metrics and computational efficiency. The code is available at https://github.com/chencn2020/MobileIQA.
PromptIQA: Boosting the Performance and Generalization for No-Reference Image Quality Assessment via Prompts
Mar 08, 2024Due to the diversity of assessment requirements in various application scenarios for the IQA task, existing IQA methods struggle to directly adapt to these varied requirements after training. Thus, when facing new requirements, a typical approach is fine-tuning these models on datasets specifically created for those requirements. However, it is time-consuming to establish IQA datasets. In this work, we propose a Prompt-based IQA (PromptIQA) that can directly adapt to new requirements without fine-tuning after training. On one hand, it utilizes a short sequence of Image-Score Pairs (ISP) as prompts for targeted predictions, which significantly reduces the dependency on the data requirements. On the other hand, PromptIQA is trained on a mixed dataset with two proposed data augmentation strategies to learn diverse requirements, thus enabling it to effectively adapt to new requirements. Experiments indicate that the PromptIQA outperforms SOTA methods with higher performance and better generalization. The code will be available.
GMC-IQA: Exploiting Global-correlation and Mean-opinion Consistency for No-reference Image Quality Assessment
Jan 19, 2024
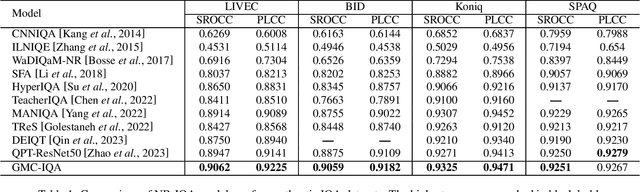
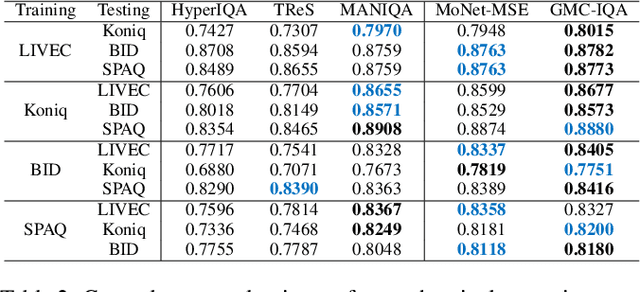
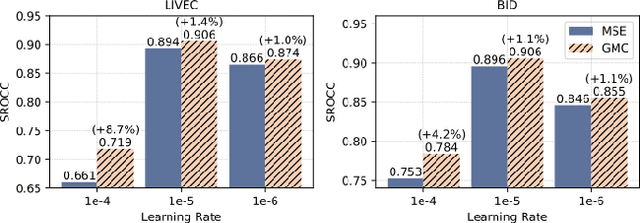
Due to the subjective nature of image quality assessment (IQA), assessing which image has better quality among a sequence of images is more reliable than assigning an absolute mean opinion score for an image. Thus, IQA models are evaluated by global correlation consistency (GCC) metrics like PLCC and SROCC, rather than mean opinion consistency (MOC) metrics like MAE and MSE. However, most existing methods adopt MOC metrics to define their loss functions, due to the infeasible computation of GCC metrics during training. In this work, we construct a novel loss function and network to exploit Global-correlation and Mean-opinion Consistency, forming a GMC-IQA framework. Specifically, we propose a novel GCC loss by defining a pairwise preference-based rank estimation to solve the non-differentiable problem of SROCC and introducing a queue mechanism to reserve previous data to approximate the global results of the whole data. Moreover, we propose a mean-opinion network, which integrates diverse opinion features to alleviate the randomness of weight learning and enhance the model robustness. Experiments indicate that our method outperforms SOTA methods on multiple authentic datasets with higher accuracy and generalization. We also adapt the proposed loss to various networks, which brings better performance and more stable training.
Learned Smartphone ISP on Mobile GPUs with Deep Learning, Mobile AI & AIM 2022 Challenge: Report
Nov 07, 2022
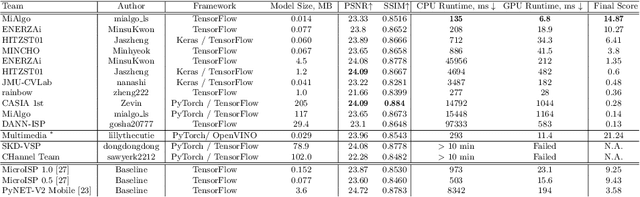
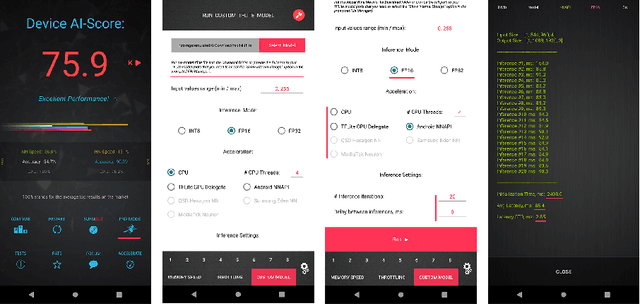
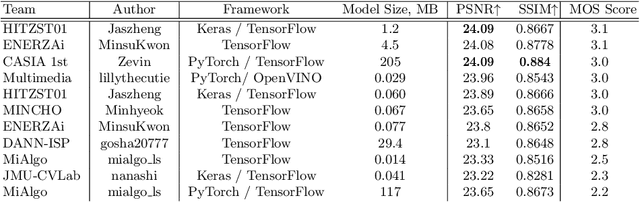
The role of mobile cameras increased dramatically over the past few years, leading to more and more research in automatic image quality enhancement and RAW photo processing. In this Mobile AI challenge, the target was to develop an efficient end-to-end AI-based image signal processing (ISP) pipeline replacing the standard mobile ISPs that can run on modern smartphone GPUs using TensorFlow Lite. The participants were provided with a large-scale Fujifilm UltraISP dataset consisting of thousands of paired photos captured with a normal mobile camera sensor and a professional 102MP medium-format FujiFilm GFX100 camera. The runtime of the resulting models was evaluated on the Snapdragon's 8 Gen 1 GPU that provides excellent acceleration results for the majority of common deep learning ops. The proposed solutions are compatible with all recent mobile GPUs, being able to process Full HD photos in less than 20-50 milliseconds while achieving high fidelity results. A detailed description of all models developed in this challenge is provided in this paper.
Boundary Guided Semantic Learning for Real-time COVID-19 Lung Infection Segmentation System
Sep 07, 2022
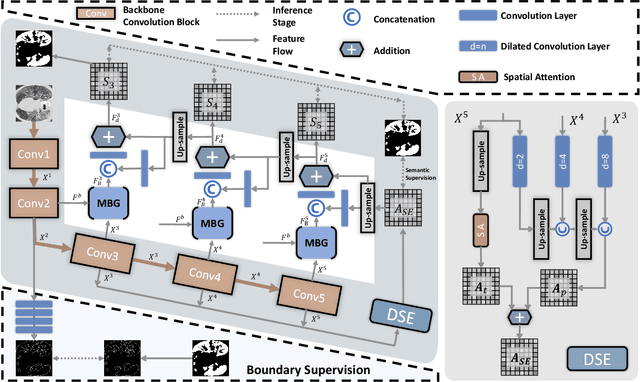
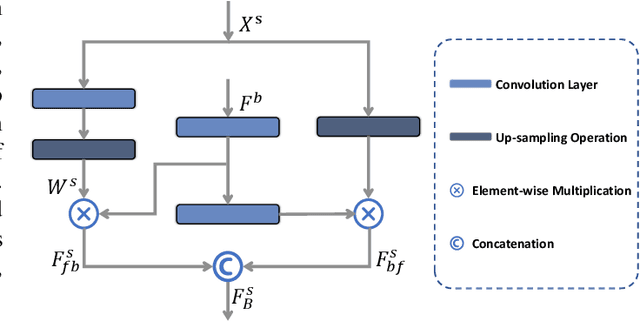
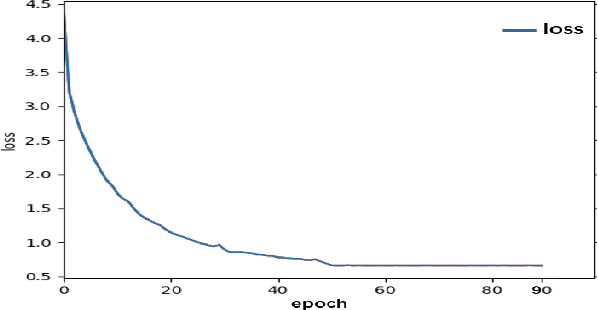
The coronavirus disease 2019 (COVID-19) continues to have a negative impact on healthcare systems around the world, though the vaccines have been developed and national vaccination coverage rate is steadily increasing. At the current stage, automatically segmenting the lung infection area from CT images is essential for the diagnosis and treatment of COVID-19. Thanks to the development of deep learning technology, some deep learning solutions for lung infection segmentation have been proposed. However, due to the scattered distribution, complex background interference and blurred boundaries, the accuracy and completeness of the existing models are still unsatisfactory. To this end, we propose a boundary guided semantic learning network (BSNet) in this paper. On the one hand, the dual-branch semantic enhancement module that combines the top-level semantic preservation and progressive semantic integration is designed to model the complementary relationship between different high-level features, thereby promoting the generation of more complete segmentation results. On the other hand, the mirror-symmetric boundary guidance module is proposed to accurately detect the boundaries of the lesion regions in a mirror-symmetric way. Experiments on the publicly available dataset demonstrate that our BSNet outperforms the existing state-of-the-art competitors and achieves a real-time inference speed of 44 FPS.