 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsensus-Aligned Neuron Efficient Fine-Tuning Large Language Models for Multi-Domain Machine Translation
Feb 05, 2026Multi-domain machine translation (MDMT) aims to build a unified model capable of translating content across diverse domains. Despite the impressive machine translation capabilities demonstrated by large language models (LLMs), domain adaptation still remains a challenge for LLMs. Existing MDMT methods such as in-context learning and parameter-efficient fine-tuning often suffer from domain shift, parameter interference and limited generalization. In this work, we propose a neuron-efficient fine-tuning framework for MDMT that identifies and updates consensus-aligned neurons within LLMs. These neurons are selected by maximizing the mutual information between neuron behavior and domain features, enabling LLMs to capture both generalizable translation patterns and domain-specific nuances. Our method then fine-tunes LLMs guided by these neurons, effectively mitigating parameter interference and domain-specific overfitting. Comprehensive experiments on three LLMs across ten German-English and Chinese-English translation domains evidence that our method consistently outperforms strong PEFT baselines on both seen and unseen domains, achieving state-of-the-art performance.
360-GeoGS: Geometrically Consistent Feed-Forward 3D Gaussian Splatting Reconstruction for 360 Images
Jan 05, 20263D scene reconstruction is fundamental for spatial intelligence applications such as AR, robotics, and digital twins. Traditional multi-view stereo struggles with sparse viewpoints or low-texture regions, while neural rendering approaches, though capable of producing high-quality results, require per-scene optimization and lack real-time efficiency. Explicit 3D Gaussian Splatting (3DGS) enables efficient rendering, but most feed-forward variants focus on visual quality rather than geometric consistency, limiting accurate surface reconstruction and overall reliability in spatial perception tasks. This paper presents a novel feed-forward 3DGS framework for 360 images, capable of generating geometrically consistent Gaussian primitives while maintaining high rendering quality. A Depth-Normal geometric regularization is introduced to couple rendered depth gradients with normal information, supervising Gaussian rotation, scale, and position to improve point cloud and surface accuracy. Experimental results show that the proposed method maintains high rendering quality while significantly improving geometric consistency, providing an effective solution for 3D reconstruction in spatial perception tasks.
Hyperspherical Graph Representation Learning via Adaptive Neighbor-Mean Alignment and Uniformity
Dec 30, 2025Graph representation learning (GRL) aims to encode structural and semantic dependencies of graph-structured data into low-dimensional embeddings. However, existing GRL methods often rely on surrogate contrastive objectives or mutual information maximization, which typically demand complex architectures, negative sampling strategies, and sensitive hyperparameter tuning. These design choices may induce over-smoothing, over-squashing, and training instability. In this work, we propose HyperGRL, a unified framework for hyperspherical graph representation learning via adaptive neighbor-mean alignment and sampling-free uniformity. HyperGRL embeds nodes on a unit hypersphere through two adversarially coupled objectives: neighbor-mean alignment and sampling-free uniformity. The alignment objective uses the mean representation of each node's local neighborhood to construct semantically grounded, stable targets that capture shared structural and feature patterns. The uniformity objective formulates dispersion via an L2-based hyperspherical regularization, encouraging globally uniform embedding distributions while preserving discriminative information. To further stabilize training, we introduce an entropy-guided adaptive balancing mechanism that dynamically regulates the interplay between alignment and uniformity without requiring manual tuning. Extensive experiments on node classification, node clustering, and link prediction demonstrate that HyperGRL delivers superior representation quality and generalization across diverse graph structures, achieving average improvements of 1.49%, 0.86%, and 0.74% over the strongest existing methods, respectively. These findings highlight the effectiveness of geometrically grounded, sampling-free contrastive objectives for graph representation learning.
Multilingual Generative Retrieval via Cross-lingual Semantic Compression
Oct 09, 2025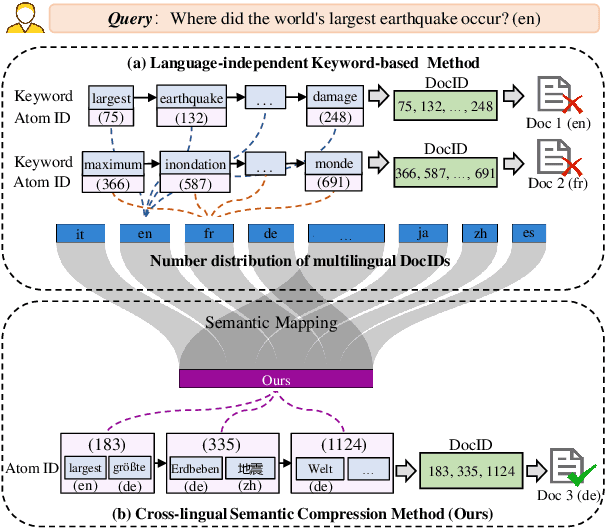
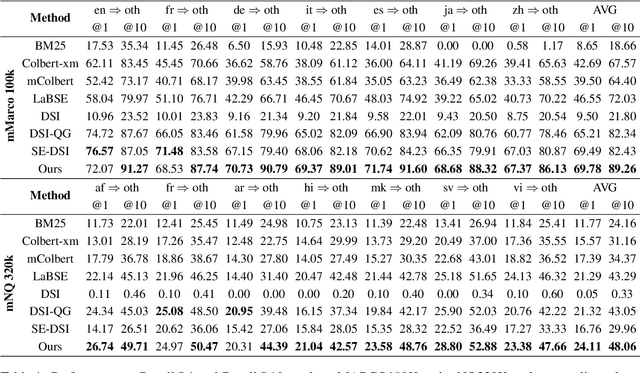
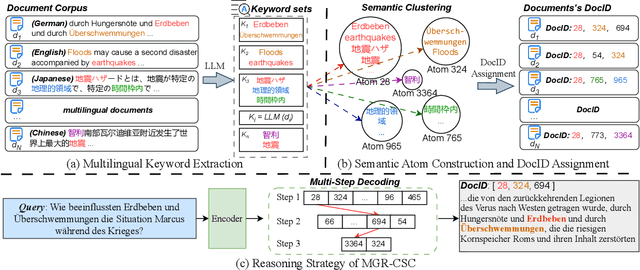

Generative Information Retrieval is an emerging retrieval paradigm that exhibits remarkable performance in monolingual scenarios.However, applying these methods to multilingual retrieval still encounters two primary challenges, cross-lingual identifier misalignment and identifier inflation. To address these limitations, we propose Multilingual Generative Retrieval via Cross-lingual Semantic Compression (MGR-CSC), a novel framework that unifies semantically equivalent multilingual keywords into shared atoms to align semantics and compresses the identifier space, and we propose a dynamic multi-step constrained decoding strategy during retrieval. MGR-CSC improves cross-lingual alignment by assigning consistent identifiers and enhances decoding efficiency by reducing redundancy. Experiments demonstrate that MGR-CSC achieves outstanding retrieval accuracy, improving by 6.83% on mMarco100k and 4.77% on mNQ320k, while reducing document identifiers length by 74.51% and 78.2%, respectively.
FLEXI: Benchmarking Full-duplex Human-LLM Speech Interaction
Sep 26, 2025Full-Duplex Speech-to-Speech Large Language Models (LLMs) are foundational to natural human-computer interaction, enabling real-time spoken dialogue systems. However, benchmarking and modeling these models remains a fundamental challenge. We introduce FLEXI, the first benchmark for full-duplex LLM-human spoken interaction that explicitly incorporates model interruption in emergency scenarios. FLEXI systematically evaluates the latency, quality, and conversational effectiveness of real-time dialogue through six diverse human-LLM interaction scenarios, revealing significant gaps between open source and commercial models in emergency awareness, turn terminating, and interaction latency. Finally, we suggest that next token-pair prediction offers a promising path toward achieving truly seamless and human-like full-duplex interaction.
THE-SEAN: A Heart Rate Variation-Inspired Temporally High-Order Event-Based Visual Odometry with Self-Supervised Spiking Event Accumulation Networks
Mar 07, 2025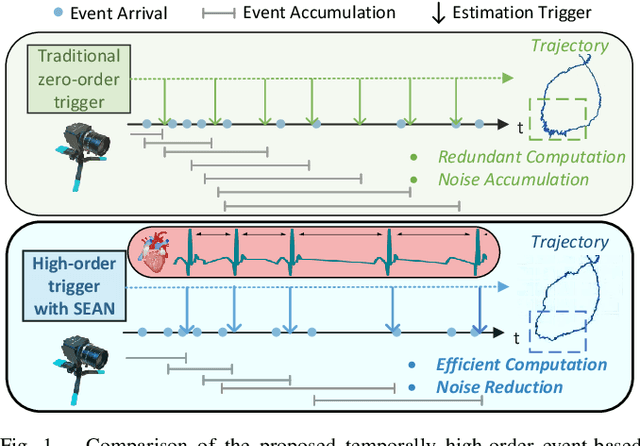
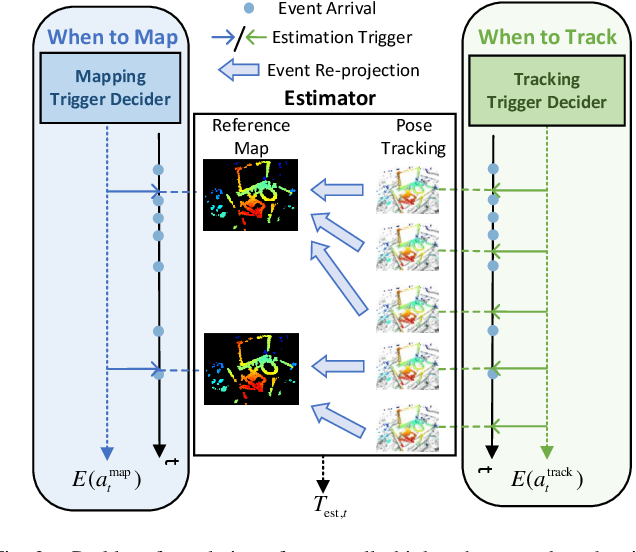
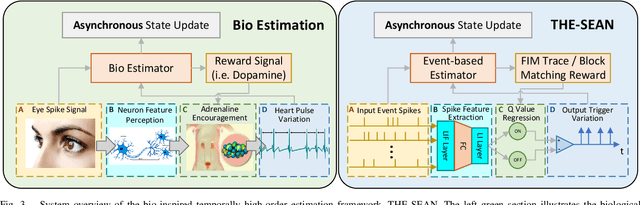
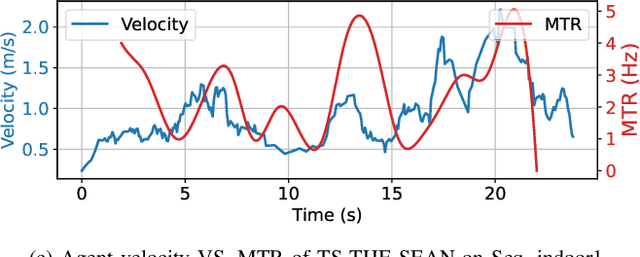
Event-based visual odometry has recently gained attention for its high accuracy and real-time performance in fast-motion systems. Unlike traditional synchronous estimators that rely on constant-frequency (zero-order) triggers, event-based visual odometry can actively accumulate information to generate temporally high-order estimation triggers. However, existing methods primarily focus on adaptive event representation after estimation triggers, neglecting the decision-making process for efficient temporal triggering itself. This oversight leads to the computational redundancy and noise accumulation. In this paper, we introduce a temporally high-order event-based visual odometry with spiking event accumulation networks (THE-SEAN). To the best of our knowledge, it is the first event-based visual odometry capable of dynamically adjusting its estimation trigger decision in response to motion and environmental changes. Inspired by biological systems that regulate hormone secretion to modulate heart rate, a self-supervised spiking neural network is designed to generate estimation triggers. This spiking network extracts temporal features to produce triggers, with rewards based on block matching points and Fisher information matrix (FIM) trace acquired from the estimator itself. Finally, THE-SEAN is evaluated across several open datasets, thereby demonstrating average improvements of 13\% in estimation accuracy, 9\% in smoothness, and 38\% in triggering efficiency compared to the state-of-the-art methods.
Relax DARTS: Relaxing the Constraints of Differentiable Architecture Search for Eye Movement Recognition
Sep 18, 2024



Eye movement biometrics is a secure and innovative identification method. Deep learning methods have shown good performance, but their network architecture relies on manual design and combined priori knowledge. To address these issues, we introduce automated network search (NAS) algorithms to the field of eye movement recognition and present Relax DARTS, which is an improvement of the Differentiable Architecture Search (DARTS) to realize more efficient network search and training. The key idea is to circumvent the issue of weight sharing by independently training the architecture parameters $\alpha$ to achieve a more precise target architecture. Moreover, the introduction of module input weights $\beta$ allows cells the flexibility to select inputs, to alleviate the overfitting phenomenon and improve the model performance. Results on four public databases demonstrate that the Relax DARTS achieves state-of-the-art recognition performance. Notably, Relax DARTS exhibits adaptability to other multi-feature temporal classification tasks.
TON-VIO: Online Time Offset Modeling Networks for Robust Temporal Alignment in High Dynamic Motion VIO
Mar 19, 2024Temporal misalignment (time offset) between sensors is common in low cost visual-inertial odometry (VIO) systems. Such temporal misalignment introduces inconsistent constraints for state estimation, leading to a significant positioning drift especially in high dynamic motion scenarios. In this article, we focus on online temporal calibration to reduce the positioning drift caused by the time offset for high dynamic motion VIO. For the time offset observation model, most existing methods rely on accurate state estimation or stable visual tracking. For the prediction model, current methods oversimplify the time offset as a constant value with white Gaussian noise. However, these ideal conditions are seldom satisfied in real high dynamic scenarios, resulting in the poor performance. In this paper, we introduce online time offset modeling networks (TON) to enhance real-time temporal calibration. TON improves the accuracy of time offset observation and prediction modeling. Specifically, for observation modeling, we propose feature velocity observation networks to enhance velocity computation for features in unstable visual tracking conditions. For prediction modeling, we present time offset prediction networks to learn its evolution pattern. To highlight the effectiveness of our method, we integrate the proposed TON into both optimization-based and filter-based VIO systems. Simulation and real-world experiments are conducted to demonstrate the enhanced performance of our approach. Additionally, to contribute to the VIO community, we will open-source the code of our method on: https://github.com/Franky-X/FVON-TPN.
SYENet: A Simple Yet Effective Network for Multiple Low-Level Vision Tasks with Real-time Performance on Mobile Device
Aug 16, 2023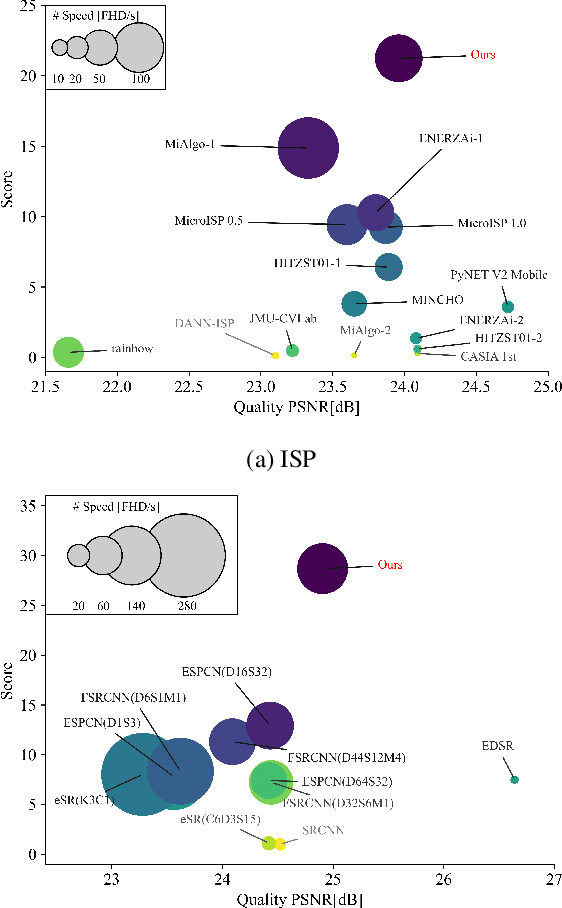



With the rapid development of AI hardware accelerators, applying deep learning-based algorithms to solve various low-level vision tasks on mobile devices has gradually become possible. However, two main problems still need to be solved: task-specific algorithms make it difficult to integrate them into a single neural network architecture, and large amounts of parameters make it difficult to achieve real-time inference. To tackle these problems, we propose a novel network, SYENet, with only $~$6K parameters, to handle multiple low-level vision tasks on mobile devices in a real-time manner. The SYENet consists of two asymmetrical branches with simple building blocks. To effectively connect the results by asymmetrical branches, a Quadratic Connection Unit(QCU) is proposed. Furthermore, to improve performance, a new Outlier-Aware Loss is proposed to process the image. The proposed method proves its superior performance with the best PSNR as compared with other networks in real-time applications such as Image Signal Processing(ISP), Low-Light Enhancement(LLE), and Super-Resolution(SR) with 2K60FPS throughput on Qualcomm 8 Gen 1 mobile SoC(System-on-Chip). Particularly, for ISP task, SYENet got the highest score in MAI 2022 Learned Smartphone ISP challenge.
High-Accuracy Absolute-Position-Aided Code Phase Tracking Based on RTK/INS Deep Integration in Challenging Static Scenarios
Dec 31, 2022

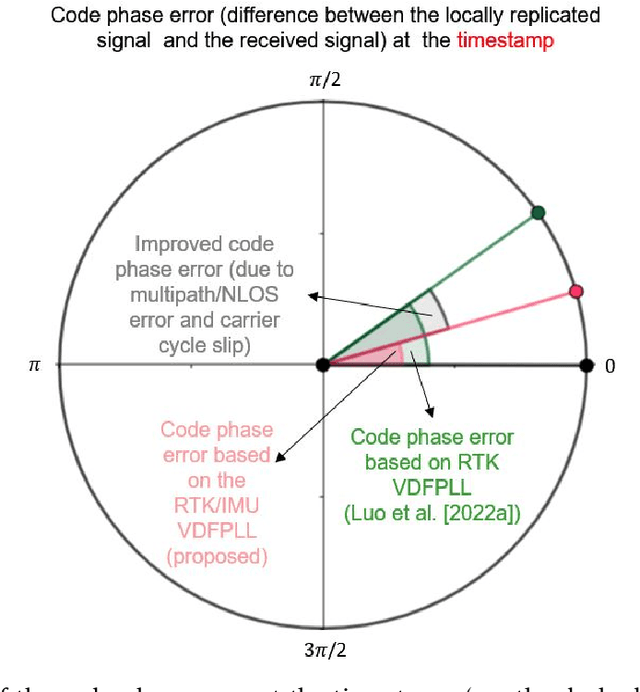
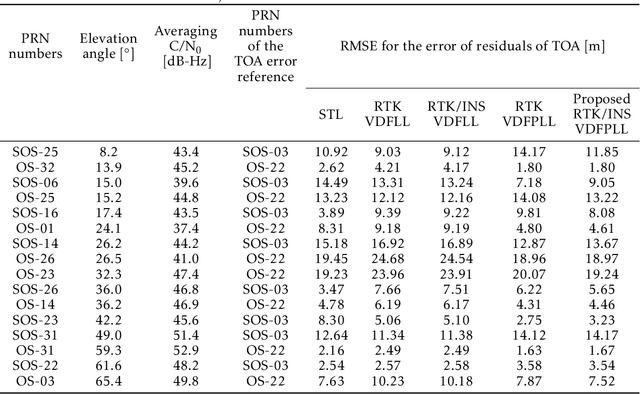
Many multi-sensor navigation systems urgently demand accurate positioning initialization from global navigation satellite systems (GNSSs) in challenging static scenarios. However, ground blockages against line-of-sight (LOS) signal reception make it difficult for GNSS users. Steering local codes in GNSS basebands is a desiring way to correct instantaneous signal phase misalignment, efficiently gathering useful signal power and increasing positioning accuracy. Besides, inertial navigation systems (INSs) have been used as a well-complementary dead reckoning (DR) sensor for GNSS receivers in kinematic scenarios resisting various interferences since early. But little work focuses on the case of whether the INS can improve GNSS receivers in static scenarios. Thus, this paper proposes an enhanced navigation system deeply integrated with low-cost INS solutions and GNSS high-accuracy carrier-based positioning. First, an absolute code phase is predicted from base station information, and integrated solution of the INS DR and real-time kinematic (RTK) results through an extended Kalman filter (EKF). Then, a numerically controlled oscillator (NCO) leverages the predicted code phase to improve the alignment between instantaneous local code phases and received ones. The proposed algorithm is realized in a vector-tracking GNSS software-defined radio (SDR). Real-world experiments demonstrate the proposed SDR regarding estimating time-of-arrival (TOA) and positioning accuracy.