 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Cross Task Generalization in Handwriting-Based Alzheimer's Screening via Vision Language Adaptation
Nov 08, 2025Alzheimer's disease is a prevalent neurodegenerative disorder for which early detection is critical. Handwriting-often disrupted in prodromal AD-provides a non-invasive and cost-effective window into subtle motor and cognitive decline. Existing handwriting-based AD studies, mostly relying on online trajectories and hand-crafted features, have not systematically examined how task type influences diagnostic performance and cross-task generalization. Meanwhile, large-scale vision language models have demonstrated remarkable zero or few-shot anomaly detection in natural images and strong adaptability across medical modalities such as chest X-ray and brain MRI. However, handwriting-based disease detection remains largely unexplored within this paradigm. To close this gap, we introduce a lightweight Cross-Layer Fusion Adapter framework that repurposes CLIP for handwriting-based AD screening. CLFA implants multi-level fusion adapters within the visual encoder to progressively align representations toward handwriting-specific medical cues, enabling prompt-free and efficient zero-shot inference. Using this framework, we systematically investigate cross-task generalization-training on a specific handwriting task and evaluating on unseen ones-to reveal which task types and writing patterns most effectively discriminate AD. Extensive analyses further highlight characteristic stroke patterns and task-level factors that contribute to early AD identification, offering both diagnostic insights and a benchmark for handwriting-based cognitive assessment.
EM-DARTS: Hierarchical Differentiable Architecture Search for Eye Movement Recognition
Sep 22, 2024



Eye movement biometrics has received increasing attention thanks to its high secure identification. Although deep learning (DL) models have been recently successfully applied for eye movement recognition, the DL architecture still is determined by human prior knowledge. Differentiable Neural Architecture Search (DARTS) automates the manual process of architecture design with high search efficiency. DARTS, however, usually stacks the same multiple learned cells to form a final neural network for evaluation, limiting therefore the diversity of the network. Incidentally, DARTS usually searches the architecture in a shallow network while evaluating it in a deeper one, which results in a large gap between the architecture depths in the search and evaluation scenarios. To address this issue, we propose EM-DARTS, a hierarchical differentiable architecture search algorithm to automatically design the DL architecture for eye movement recognition. First, we define a supernet and propose a global and local alternate Neural Architecture Search method to search the optimal architecture alternately with an differentiable neural architecture search. The local search strategy aims to find an optimal architecture for different cells while the global search strategy is responsible for optimizing the architecture of the target network. To further reduce redundancy, a transfer entropy is proposed to compute the information amount of each layer, so as to further simplify search network. Our experiments on three public databases demonstrate that the proposed EM-DARTS is capable of producing an optimal architecture that leads to state-of-the-art recognition performance.
Relax DARTS: Relaxing the Constraints of Differentiable Architecture Search for Eye Movement Recognition
Sep 18, 2024



Eye movement biometrics is a secure and innovative identification method. Deep learning methods have shown good performance, but their network architecture relies on manual design and combined priori knowledge. To address these issues, we introduce automated network search (NAS) algorithms to the field of eye movement recognition and present Relax DARTS, which is an improvement of the Differentiable Architecture Search (DARTS) to realize more efficient network search and training. The key idea is to circumvent the issue of weight sharing by independently training the architecture parameters $\alpha$ to achieve a more precise target architecture. Moreover, the introduction of module input weights $\beta$ allows cells the flexibility to select inputs, to alleviate the overfitting phenomenon and improve the model performance. Results on four public databases demonstrate that the Relax DARTS achieves state-of-the-art recognition performance. Notably, Relax DARTS exhibits adaptability to other multi-feature temporal classification tasks.
MsMemoryGAN: A Multi-scale Memory GAN for Palm-vein Adversarial Purification
Aug 20, 2024

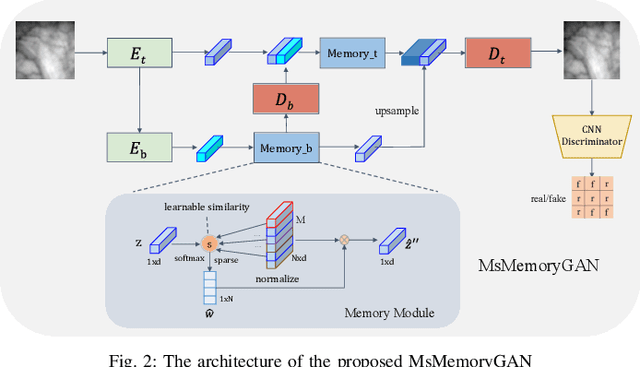
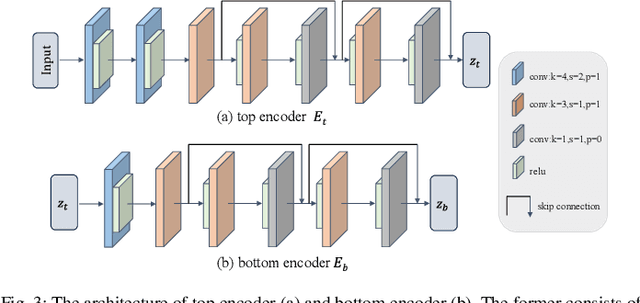
Deep neural networks have recently achieved promising performance in the vein recognition task and have shown an increasing application trend, however, they are prone to adversarial perturbation attacks by adding imperceptible perturbations to the input, resulting in making incorrect recognition. To address this issue, we propose a novel defense model named MsMemoryGAN, which aims to filter the perturbations from adversarial samples before recognition. First, we design a multi-scale autoencoder to achieve high-quality reconstruction and two memory modules to learn the detailed patterns of normal samples at different scales. Second, we investigate a learnable metric in the memory module to retrieve the most relevant memory items to reconstruct the input image. Finally, the perceptional loss is combined with the pixel loss to further enhance the quality of the reconstructed image. During the training phase, the MsMemoryGAN learns to reconstruct the input by merely using fewer prototypical elements of the normal patterns recorded in the memory. At the testing stage, given an adversarial sample, the MsMemoryGAN retrieves its most relevant normal patterns in memory for the reconstruction. Perturbations in the adversarial sample are usually not reconstructed well, resulting in purifying the input from adversarial perturbations. We have conducted extensive experiments on two public vein datasets under different adversarial attack methods to evaluate the performance of the proposed approach. The experimental results show that our approach removes a wide variety of adversarial perturbations, allowing vein classifiers to achieve the highest recognition accuracy.
Neural Architecture Search based Global-local Vision Mamba for Palm-Vein Recognition
Aug 13, 2024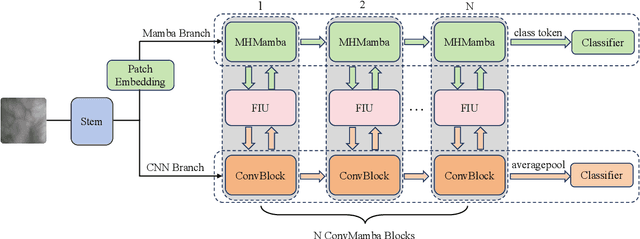
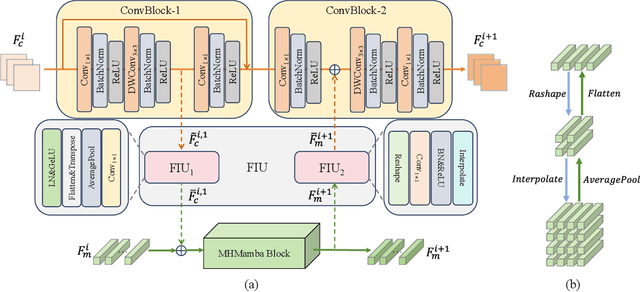
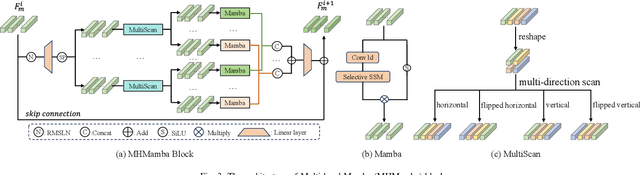
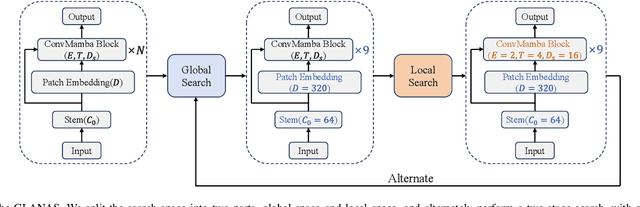
Due to the advantages such as high security, high privacy, and liveness recognition, vein recognition has been received more and more attention in past years. Recently, deep learning models, e.g., Mamba has shown robust feature representation with linear computational complexity and successfully applied for visual tasks. However, vision Manba can capture long-distance feature dependencies but unfortunately deteriorate local feature details. Besides, manually designing a Mamba architecture based on human priori knowledge is very time-consuming and error-prone. In this paper, first, we propose a hybrid network structure named Global-local Vision Mamba (GLVM), to learn the local correlations in images explicitly and global dependencies among tokens for vein feature representation. Secondly, we design a Multi-head Mamba to learn the dependencies along different directions, so as to improve the feature representation ability of vision Mamba. Thirdly, to learn the complementary features, we propose a ConvMamba block consisting of three branches, named Multi-head Mamba branch (MHMamba), Feature Iteration Unit branch (FIU), and Convolutional Neural Network (CNN) branch, where the Feature Iteration Unit branch aims to fuse convolutional local features with Mamba-based global representations. Finally, a Globallocal Alternate Neural Architecture Search (GLNAS) method is proposed to search the optimal architecture of GLVM alternately with the evolutionary algorithm, thereby improving the recognition performance for vein recognition tasks. We conduct rigorous experiments on three public palm-vein databases to estimate the performance. The experimental results demonstrate that the proposed method outperforms the representative approaches and achieves state-of-the-art recognition accuracy.
Adversarial Masking Contrastive Learning for vein recognition
Jan 16, 2024Vein recognition has received increasing attention due to its high security and privacy. Recently, deep neural networks such as Convolutional neural networks (CNN) and Transformers have been introduced for vein recognition and achieved state-of-the-art performance. Despite the recent advances, however, existing solutions for finger-vein feature extraction are still not optimal due to scarce training image samples. To overcome this problem, in this paper, we propose an adversarial masking contrastive learning (AMCL) approach, that generates challenging samples to train a more robust contrastive learning model for the downstream palm-vein recognition task, by alternatively optimizing the encoder in the contrastive learning model and a set of latent variables. First, a huge number of masks are generated to train a robust generative adversarial network (GAN). The trained generator transforms a latent variable from the latent variable space into a mask space. Then, we combine the trained generator with a contrastive learning model to obtain our AMCL, where the generator produces challenging masking images to increase the contrastive loss and the contrastive learning model is trained based on the harder images to learn a more robust feature representation. After training, the trained encoder in the contrastive learning model is combined with a classification layer to build a classifier, which is further fine-tuned on labeled training data for vein recognition. The experimental results on three databases demonstrate that our approach outperforms existing contrastive learning approaches in terms of improving identification accuracy of vein classifiers and achieves state-of-the-art recognition results.
EmMixformer: Mix transformer for eye movement recognition
Jan 10, 2024



Eye movement (EM) is a new highly secure biometric behavioral modality that has received increasing attention in recent years. Although deep neural networks, such as convolutional neural network (CNN), have recently achieved promising performance, current solutions fail to capture local and global temporal dependencies within eye movement data. To overcome this problem, we propose in this paper a mixed transformer termed EmMixformer to extract time and frequency domain information for eye movement recognition. To this end, we propose a mixed block consisting of three modules, transformer, attention Long short-term memory (attention LSTM), and Fourier transformer. We are the first to attempt leveraging transformer to learn long temporal dependencies within eye movement. Second, we incorporate the attention mechanism into LSTM to propose attention LSTM with the aim to learn short temporal dependencies. Third, we perform self attention in the frequency domain to learn global features. As the three modules provide complementary feature representations in terms of local and global dependencies, the proposed EmMixformer is capable of improving recognition accuracy. The experimental results on our eye movement dataset and two public eye movement datasets show that the proposed EmMixformer outperforms the state of the art by achieving the lowest verification error.
Adversarial AutoMixup
Dec 19, 2023Data mixing augmentation has been widely applied to improve the generalization ability of deep neural networks. Recently, offline data mixing augmentation, e.g. handcrafted and saliency information-based mixup, has been gradually replaced by automatic mixing approaches. Through minimizing two sub-tasks, namely, mixed sample generation and mixup classification in an end-to-end way, AutoMix significantly improves accuracy on image classification tasks. However, as the optimization objective is consistent for the two sub-tasks, this approach is prone to generating consistent instead of diverse mixed samples, which results in overfitting for target task training. In this paper, we propose AdAutomixup, an adversarial automatic mixup augmentation approach that generates challenging samples to train a robust classifier for image classification, by alternatively optimizing the classifier and the mixup sample generator. AdAutomixup comprises two modules, a mixed example generator, and a target classifier. The mixed sample generator aims to produce hard mixed examples to challenge the target classifier while the target classifier`s aim is to learn robust features from hard mixed examples to improve generalization. To prevent the collapse of the inherent meanings of images, we further introduce an exponential moving average (EMA) teacher and cosine similarity to train AdAutomixup in an end-to-end way. Extensive experiments on seven image benchmarks consistently prove that our approach outperforms the state of the art in various classification scenarios.
Exploring Emotion Expression Recognition in Older Adults Interacting with a Virtual Coach
Nov 09, 2023The EMPATHIC project aimed to design an emotionally expressive virtual coach capable of engaging healthy seniors to improve well-being and promote independent aging. One of the core aspects of the system is its human sensing capabilities, allowing for the perception of emotional states to provide a personalized experience. This paper outlines the development of the emotion expression recognition module of the virtual coach, encompassing data collection, annotation design, and a first methodological approach, all tailored to the project requirements. With the latter, we investigate the role of various modalities, individually and combined, for discrete emotion expression recognition in this context: speech from audio, and facial expressions, gaze, and head dynamics from video. The collected corpus includes users from Spain, France, and Norway, and was annotated separately for the audio and video channels with distinct emotional labels, allowing for a performance comparison across cultures and label types. Results confirm the informative power of the modalities studied for the emotional categories considered, with multimodal methods generally outperforming others (around 68% accuracy with audio labels and 72-74% with video labels). The findings are expected to contribute to the limited literature on emotion recognition applied to older adults in conversational human-machine interaction.